201805信息安全下午真题
第 1 题
阅读下列说明,回答问题1至问题4,将解答填入答题纸的对应栏内。
【说明】恶意代码是指为达到恶意目的专门设计的程序或者代码。常见的恶意代码类型有特洛伊木马、蠕虫、病毒、后门、Rootkit、僵尸程序、广告软件。
2017年5月,勒索软件WanaCry席卷全球,国内大量高校及企事业单位的计算机被攻击,文件及数据被加密后无法使用,系统或服务无法正常运行,损失巨大。
【问题1】(2分)
按照恶意代码的分类,此次爆发的恶意软件属于哪种类型?
【问题2】(2分)
此次勒索软件针对的攻击目标是Windows还是Linux类系统?
【问题3】(6分)
恶意代码具有的共同特征是什么?
【问题4】(5分)
由于此次勒索软件需要利用系统的SMB服务漏洞(端口号445)进行传播,我们可以配置防火墙过滤规则来阻止勒索软件的攻击,请填写表1-1中的空(1)-(5),使该过滤规则完整。
注:假设本机IP地址为:1.2.3.4,”*”表示通配符。

答案与解析
- 试题难度:较难
- 知识点:恶意代码防范技术原理>恶意代码概述
- 试题答案:【问题1】蠕虫类型
【问题2】Windows操作系统
【问题3】恶意代码具有如下共同特征:(1) 恶意的目的(2) 本身是计算机程序(3) 通过执行发生作用。
【问题4】(1) (2) (3)445 (4)TCP (5)* - 试题解析:
【问题1】
WannaCry,一种“蠕虫式”的勒索病毒软件,大小3.3MB,由不法分子利用NSA泄露的危险漏洞“EternalBlue”(永恒之蓝)进行传播。该恶意软件会扫描电脑上的TCP 445端口(Server Message Block/SMB),以类似于蠕虫病毒的方式传播,攻击主机并加密主机上存储的文件,然后要求以比特币的形式支付赎金。
【问题2】
主要是利用windows操作系统中存在的漏洞。
【问题3】
恶意代码是指故意编制或设置的、对网络或系统会产生威胁或潜在威胁的计算机代码。具有如下共同特征:
(1)恶意的目的
(2)本身是计算机程序
(3)通过执行发生作用。
【问题4】
针对该勒索软件的攻击和传播特点,需要对SMB服务所在的445端口进行过滤,只要网外对网内445端口的所有连接请求予以过滤。需要注意的是SMB服务是基于TCP协议的。
第 2 题
阅读下列说明和图,回答问题1至问题3,将解答填入答题纸的对应栏内。
【说明】
密码学的基本目标是在有攻击者存在的环境下,保证通信双方(A和B)之间能够使用不安全的通信信道实现安全通信。密码技术能够实现信息的保密性、完整性、可用性和不可否认性等安全目标。一种实用的保密通信模型往往涉及对称加密、公钥密码、Hash函数、数字签名等多种密码技术。
在以下描述中,M表示消息,H表示Hash函数,E表示加密算法,D表示解密算法,K表示密钥,SKA表示A的私钥,PKA表示A的公钥,SKB表示B的私钥,PKB表示B的公钥,||表示连接操作。
【问题1】(6分)
用户AB双方采用的保密通信的基本过程如图2-1所示。
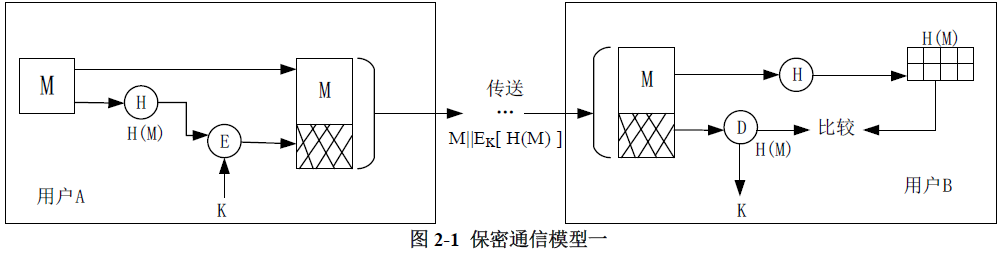
请问图2-1所设计的保密通信模型能实现信息的哪些安全目标?图2-1中的用户A侧的H和E能否互换计算顺序?如果不能互换请说明原因:如果能互换请说明对安全目标的影响。
【问题2】(4分)
图2-2给出了另一种保密通信的基本过程:
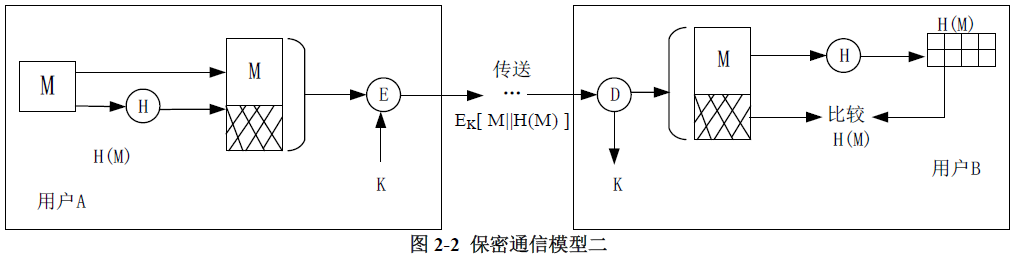
请问图2-2设计的保密通信模型能实现信息安全的哪些特性?
【问题3】(5分)
为了在传输过程中能够保障信息的保密性、完整性和不可否认性,设计了一个安全通信模型结构如图2-3所示:
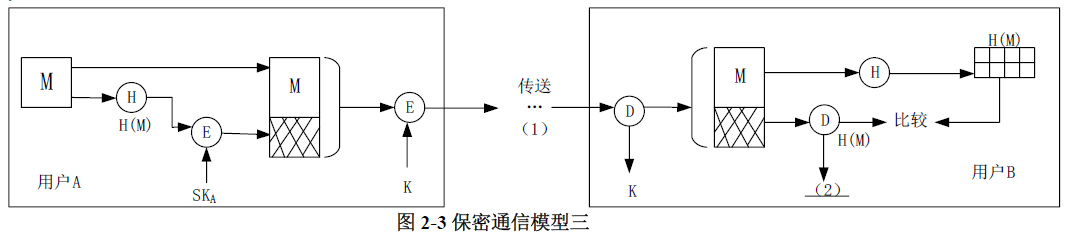
**答案与解析** - 试题难度:较难 - 知识点:认证技术原理与应用>认证类型与认证过程 - 试题答案:【问题1】
能实现保密性和完整性。
【问题3】
(1)Ek[ M||SKA(H(M)) ] (2)PKA
通过双方共享的密钥K对M和H(M)进行加密后,可以在保证信息完整性的基础上进一步实现信息的保密性。
【问题3】
其安全通信模型基本流程为:发送方先对明文M进行hash运算,对结果H(M)进行签名,即SKA(H(M),接着用收发双方的共享密钥K对明文M和签名摘要SKA(H(M))进行加密,得到Ek[ M||SKA(H(M)) ],将其传送给接收方;接收方接收该内容后,首先使用同样的共享密钥K进行解密,得到明文M和签名摘要SKA(H(M),然后再使用A的公钥PKA对签名摘要SKA(H(M))进行验证,若验证成功,则得到H(M),接着对接收到的明文M进行同样的Hash运算,将其结果与接收到的H(M)进行对比,以验证信息的完整性。
第 3 题
阅读下列说明,回答问题1至问题3,将解答填入答题纸的对应栏内。
【说明】在Linux系统中,用户账号是用户的身份标志,它由用户名和用户口令组成。
【问题1】(4分)
Linux系统将用户名和口令分别保存在哪些文件中?
【问题2】(7分)
Linux系统的用户名文件通常包含如下形式的内容:
root:x:0:0:root:root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
hujw:x:500:500:hujianwei:/home/hujw:/bin/bash
文件中的一行记录对应着一个用户,每行记录用冒号(:)分隔为7个字段,请问第1个冒号(第二列)和第二个冒号(第三列)的含义是什么?上述用户名文件中,第三列的数字分别代表什么含义?
【问题3】(4分)
Linux系统中用户名文件和口令字文件的默认访问权限分别是什么?
答案与解析
- 试题难度:较难
- 知识点:操作系统安全保护>UNIX/Linux操作系统安全分析与防护
- 试题答案:【问题1】
用户名是存放在/etc/passwd文件中,口令是以加密的形式存放在/etc/shadow文件中。
【问题2】用户名:口令: 用户标识号:组标识号:注释性描述:主目录:登录Shell。
第一个冒号的第二列代表口令;第二个冒号的第三列代表用户标识号。
root用户id为0;bin用户id为1到99;hujw用户id为500。超级用户(0),系统管理账号(1-99), 普通账号(500)。【问题3】
数字形式:744 , 400 (600)或文字形式:用户名文件全局可读,口令字文件只有超级用户可读(写)。 - 试题解析:【问题1】
在Linux系统中,系统用户名是存放在/etc/passwd文件中,口令是以加密的形式存放在/etc/shadow文件中。
【问题2】
在Linux系统中,系统用户名是存放在/etc/passwd文件中,口令是以加密的形式存放在/etc/shadow文件中。/etc/passwd文件介绍:
一般/etc/passwd中一行记录对应着一个用户,每行记录又被冒号(:)分隔为7个字段,其格式和具体含义如下:
用户名:口令:用户标识号:组标识号:注释性描述:主目录:登录Shell
用户名(login_name):是代表用户账号的字符串。通常长度不超过8个字符,并且由大小写字母和/或数字组成。登录名中不能有冒号(:),因为冒号在这里是分隔符。为了兼容起见,登录名中最好不要包含点字符(.),并且不使用连字符(-)和加号(+)打头。
口令(passwd):一些系统中,存放着加密后的用户口令字。虽然这个字段存放的只是用户口令的加密串,不是明文,但是由于/etc/passwd文件对所有用户都可读,所以这仍是一个安全隐患。因此,现在许多Linux系统(如SVR4)都使用了shadow技术,把真正的加密后的用户口令字存放到/etc/shadow文件中,而在/etc/passwd文件的口令字段中只存放一个特殊的字符,例如“x”或者“*”。
用户标识号(UID):是一个整数,系统内部用它来标识用户。一般情况下它与用户名是一一对应的。如果几个用户名对应的用户标识号是一样的,系统内部将把它们视为同一个用户,但是它们可以有不同的口令、不同的主目录以及不同的登录Shell等。取值范围是0-65535。0是超级用户root的标识号,1-99由系统保留,作为管理账号,普通用户的标识号从100开始。在Linux系统中,这个界限是500。
组标识号(GID):字段记录的是用户所属的用户组。它对应着/etc/group文件中的一条记录。
注释性描述(users):字段记录着用户的一些个人情况,例如用户的真实姓名、电话、地址等,这个字段并没有什么实际的用途。在不同的Linux系统中,这个字段的格式并没有统一。在许多Linux系统中,这个字段存放的是一段任意的注释性描述文字,用作finger命令的输出。
主目录(home_directory):也就是用户的起始工作目录,它是用户在登录到系统之后所处的目录。在大多数系统中,各用户的主目录都被组织在同一个特定的目录下,而用户主目录的名称就是该用户的登录名。各用户对自己的主目录有读、写、执行(搜索)权限,其他用户对此目录的访问权限则根据具体情况设置。
登录Shell(Shell):用户登录后,要启动一个进程,负责将用户的操作传给内核,这个进程是用户登录到系统后运行的命令解释器或某个特定的程序,即Shell。Shell是用户与Linux系统之间的接口。Linux的Shell有许多种,每种都有不同的特点。常用的有sh(BourneShell),csh(CShell),ksh(KornShell),tcsh(TENEX/TOPS-20typeCShell),bash(BourneAgainShell)等。系统管理员可以根据系统情况和用户习惯为用户指定某个Shell。如果不指定Shell,那么系统使用sh为默认的登录Shell,即这个字段的值为/bin/sh。
/etc/shadow文件介绍:
/etc/shadow文件格式与/etc/passwd文件格式类似,同样由若干个字段组成,字段之间用“:”隔开。
文件中字段主要含义为:登录名:加密口令:最后一次修改时间:最小时间间隔:最大时间间隔:警告时间:不活动时间:失效时间:标志
1、“登录名”是与/etc/passwd文件中的登录名相一致的用户账号。
2、“口令”字段存放的是加密后的用户口令字:
如果为空,则对应用户没有口令,登录时不需要口令;
星号代表账号被锁定;
双叹号表示这个密码已经过期了;
$6$开头的,表明是用SHA-512加密;
$1$表明是用MD5加密;
$2$ 是用Blowfish加密;
$5$ 是用 SHA-256加密;
3、“最后一次修改时间”表示的是从某个时刻起,到用户最后一次修改口令时的天数。时间起点对不同的系统可能不一样。例如在SCOLinux中,这个时间起点是1970年1月1日。
4、“最小时间间隔”指的是两次修改口令之间所需的最小天数。
5、“最大时间间隔”指的是口令保持有效的最大天数。
6、“警告时间”字段表示的是从系统开始警告用户到用户密码正式失效之间的天数。
7、“不活动时间”表示的是用户没有登录活动但账号仍能保持有效的最大天数。
8、“失效时间”字段给出的是一个绝对的天数,如果使用了这个字段,那么就给出相应账号的生存期。期满后,该账号就不再是一个合法的账号,也就不能再用来登录了。
用户标识号(UID)是一个整数,系统内部用它来标识用户。其取值范围是0-65535。0是超级用户root的标识号,1-99由系统保留,作为管理账号,普通用户的标识号从100开始。在Linux系统中,这个界限是500。
【问题3】
通常情况下,用户名文件是系统中所有用户可读的,但只有root 有修改权限。采用标准的Linux系统访问控制来描述就是rwx r--r--用数字表示就是744。而口令字文件只有root用户有权读写,其他用户是没有任何权限的,因此其访问权限模式是: 400 或者600。
第 4 题
阅读下列说明和C语言代码,回答问题1至问题4,将解答写在答题纸的对应栏内。
【说明】
在客户服务器通信模型中,客户端需要每隔一定时间向服务器发送数据包,以确定服务器是否掉线,服务器也能以此判断客户端是否存活,这种每隔固定时间发一次的数据包也称为心跳包。心跳包的内容没有什么特别的规定,一般都是很小的包。
某系统采用的请求和应答两种类型的心跳包格式如图4-1所示。
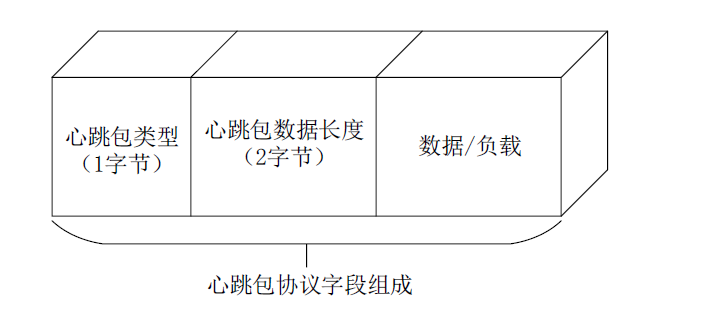
图4-1 协议包格式
心跳包类型占1个字节,主要是请求和响应两种类型;
心跳包数据长度字段占2个字节,表示后续数据或者负载的长度。
接收端收到该心跳包后的处理函数是process_heartbeat(),其中参数p指向心跳包的报文数据,s是对应客户端的socket网络通信套接字。
void process_heartbeat(unsigned char *p, SOCKET s)
{
unsigned short hbtype;
unsigned int payload;
hbtype=*p++; //心跳包类型
n2s(p, payload); //心跳包数据长度
pl=p; //pl指向心跳包数据
if(hbtype=HB_REQUEST){
unsigned char *buffer, *bp;
buffer=malloc(1+2+payload);
*bp++=HB_RESPONSE; //填充1 byte的心跳包类型
s2n(payload, bp); //填充2 bytes的数据长度
memcpy(bp,pl,payload);
/*将构造好的心跳响应包通过socket s返回客户端 */
r=write_bytes(s, buffer,3+payload);
}
}
【问题1】(4分)
(1)心跳包数据长度字段的最大取值是多少?
(2)心跳包中的数据长度字段给出的长度值是否必须和后续的数据字段的实际长度一致?
【问题2】(5分)
(1)上述接收代码存在什么样的安全漏洞?
(2)该漏洞的危害是什么?
【问题3】(2分)
模糊测试(Fuzzing)是一种非常重要的信息系统安全测评方法,它是一种基于缺陷注入的自动化测试技术。请问模糊测试属于黑盒测试还是白盒测试?其测试结果是否存在误报?
【问题4】(4分)
模糊测试技术能否测试出上述代码存在的安全漏洞?为什么?
答案与解析
- 试题难度:较难
- 知识点:网络安全测评技术与标准>网络安全测评技术与工具
- 试题答案:
【问题1】
(1)心跳包数据长度的最大取值为65535。
(2)必须是一致的。
【问题2】
存在溢出安全漏洞。
接收端处理代码在组装响应包时,心跳包数据长度字段(payload)采用的是客户端。
发送的请求包中使用的长度字段,由于心跳包数据长度字段完全由客户端控制,当payload大于实际心跳包数据的长度时,将导致越界访问接收端内存,从而泄露内存信息。(2分)
造成的危害:在正常的情况下,response 报文中的data就是request报文中的data数据,但是在异常情况下,payload 的长度远大于实际数据的长度,这样就会发生内存的越界访问,但这种越界访问并不会直接导致程序异常,(因为这里直接memcpy后,服务器端并没有使用copy后的数据,而只是简单的进行了回复报文的填充,如果服务端使用了copy的数据也许就可能发现问题)这里使用了memcpy函数,该函数会直接根据长度把内存中数据复制给另一个变量。这样就给恶意的程序留下了后门,当恶意程序给data的长度变量赋值为65535时,就可以把内存中64KB的内存数据通过Response报文发送给客户端,这样客户端程序就可以获取到一些敏感数据泄露。
【问题3】
属于黑盒测试;不存在误报。
【问题4】
不能。
因为不会产生异常,模糊测试器就无法监视到异常,从而无法检测到该漏洞。 - 试题解析:
【问题1】
已知表示心跳包的数据长度值为2字节,则其最大长度为216-1=65535。
心跳包中的数据长度字段给出的长度值必须与后续的数据字段的实际长度一致;如果不一致会产生“心脏出血”漏洞,造成有用数据泄露。
【问题2】
心脏出血漏洞主要通过攻击者模拟向服务器端发送自己编写的Heartbeat心跳数据包,主要是HeartbeatMessage的长度与payload的length进行匹配,若payload_lenght长度大于HeartbeatMessage的length,则会在服务器返回的response响应包中产生数据溢出,造成有用数据泄露。
题中每条心跳包记录中包含一个类型域(type)、一个长度域(length)和一个指向记录数据的指针(data)。心跳包的第一个字节标明了心跳包的类型。宏n2s从指针p指向的数组中取出前两个字节,并把它们存入变量payload中——这实际上是心跳包载荷的长度域(length)。注意程序并没有检查这条心跳包记录的实际长度。变量pl则指向由访问者提供的心跳包数据。
buffer = malloc(1 + 2 + payload);程序将分配一段由访问者指定大小的内存区域,这段内存区域最大为 (65535 + 1 + 2)个字节。变量bp是用来访问这段内存区域的指针。
代码中宏s2n与宏n2s干的事情正好相反:s2n读入一个16 bit长的值,然后将它存成双字节值,所以s2n会将与请求的心跳包载荷长度相同的长度值存入变量payload。然后程序从pl处开始复制payload个字节到新分配的bp数组中——pl指向了用户提供的心跳包数据。最后,程序将所有数据发回给用户。如果用户并没有在心跳包中提供足够多的数据,比如pl指向的数据实际上只有一个字节,那么memcpy会把这条心跳包记录之后的数据(无论那些数据是什么)都复制出来。
分配的buffer是根据数据包给出的长度字段来分配的,并在memcpy函数实现内存数据拷贝,因此有可能越界读取额外的内存数据,造成信息泄露。
【问题3】
模糊测试是一种黑盒测试技术,它将大量的畸形数据输入到目标程序中,通过监测程序的异常来发现被崩程序中可能存在的安全漏洞。模糊测试是一种基于缺陷注入的自动化测试技术,没有具体的执行规则,旨在预测软件中可能存在的错误以及什么样的输入能够触发错误。其通过模糊器向目标应用发送大量的畸形数据并监视程序运行异常以发现软件故障,通过记录触发异常的输入数据来进一步定位异常位置。与基于源代码的白盒测试相比,模糊测试的测试对象是二进制目标文件,因而具有更好的适用性:模糊测试是一种自动化的动态漏洞挖掘技术,不存在误报,也不需要人工进行大量的逆向分析工作。
【问题4】
上述代码存在的信息泄露漏洞在模糊测试过程中,不管用什么样的数据包长度去测试,被测代码都是正常运行,没有出现异常情况,因此也就无法判断是否有漏洞,所以模糊测试无法测试出该代码存在的漏洞。
第 5 题
阅读下列说明和图,回答问题1至问题5,将解答写在答题纸的对应栏内。
【说明】
入侵检测系(IDS)和入侵防护系统(IPS)是两种重要的网络安全防御手段,IDS注重的是网络安全状况的监管,IPS则注重对入侵行为的控制。
【问题1】(2分)
网络安全防护可以分为主动防护和被动防护,请问IDS和IPS分别属于哪种防护?
【问题2】(4分)
入侵检测是动态安全模型(P2DR)的重要组成部分。请列举P2DR模型的4个主要组成部分。
【问题3】(2分)
假如某入侵检测系统记录了如图5-1所示的网络数据包:

请问图中的数据包属于哪种网络攻击?该攻击的具体名字是什么?
【问题4】(4分)
入侵检测系统常用的两种检测技术是异常检测和误用检测,请问针对图中所描述的网络攻击应该采用哪种检测技术?请简要说明原因。
【问题5】(3分)
Snort是一款开源的网络入侵检测系统,它能够执行实时流量分析和IP协议网络的数据包记录。
Snort的配置有3种模式,请给出这3种模式的名字。
答案与解析
- 试题难度:较难
- 知识点:入侵检测技术原理与应用>入侵检测技术
- 试题答案:【问题1】
入侵检测技术(IDS)属于被动防护;入侵防护系统 (IPS)属于主动防护。
【问题2】
P2DR 模型包含 4 个主要组成部分包括:Policy (安全策略)、 Protection (防护)、 Detection (检测)和 Response (响应)。
【问题3】
属于拒绝服务攻击;具体为SYN 洪泛攻击。
【问题4】误用检测:该攻击有很明确的攻击特征和模式,适合采用误用检测。
【问题5】
Snort 的配置的3个主要模式:嗅探 (Sniffer)、包记录 (PacketLogger)和网络入侵检测。 - 试题解析:
【问题1】
入侵检测技术 (IDS) 注重的是网络安全状况的监管,通过监视网络或系统资源,寻找违反安全策略的行为或攻击迹象,并发出报警。因此IDS 系统属于被动防护。入侵防护系统(IPS)则倾向于提供主动防护,注重对入侵行为的控制。其设计宗旨是预先对入侵活动和攻击性网络流量进行拦截,避免其造成损失。
【问题2】
P2DR模型是在整体的安全策略的控制和指导下,在综合运用防护工具 ,如防火墙、操作系统身份认证、加密等手段的同时,利用检测工具,如漏溺评估、入侵检测等系统了解和评估系统的安全状态,通过适当的响应将系统调整到“最安全”和“风险最低”的状态。防护、检测和自由应组成了一个完整的、动态的安全循环。
【问题3】
SYN 洪泛攻击通过创建大量“半连接”来进行攻击,任何连接收到Internet上并提供基于TCP的网络服务的主机或路由器都可能成为这种攻击的目标;同步包风暴是当前最流行的 DoS(拒绝服务攻击)与 DDoS(分布式拒绝服务攻击)的方式之一,利用TCP协议缺陷发送大量伪造的TCP连接请求,使得被攻击者资源耗尽。三次握手,进行了两次(SYN)(SYN/ACK),不进行第三次握手(ACK),连接队列处于等待状态,大量的这样的等待,占满全部队列空间,系统挂起。
【问题4】
异常检测是指根据非正常行为( 系统或用户)和使用计算机非正常资源来检测入侵行为。其关键在于建立用户及系统正常行为轮廓(Profile),检测实际活动以判断是否背离正常轮廓。
误用检测又称为基于特征的检测,基于误用的入侵检测系统通过使用某种模式或者信号标示表示攻击,进而发现同类型的攻击。
显然针对上述攻击,根据SYN分组特征模式,应该采用误用检测来检测攻击。
【问题5】
Snort 的配置有3个主要模式:嗅探 (Sniffer)、包记录 (PacketLogger) 和网络入侵检测。嗅探模式主要是读取网络上的数据包并在控制台上用数据流不断地显示出来:包记录模式把数据包记录在磁盘上:网络入侵监测模式是最复杂最难配置的,它可以分析网流量与用户定义的规则设置进行匹配然后根据结果执行相应的操作。