201305软设下午真题
第 1 题
【问题1】(4分)
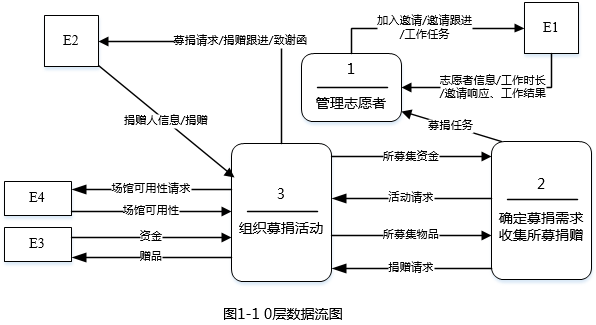
使用说明中的词语,给出图1-1中的实体E1~E4的名称。
【问题2】(7分)
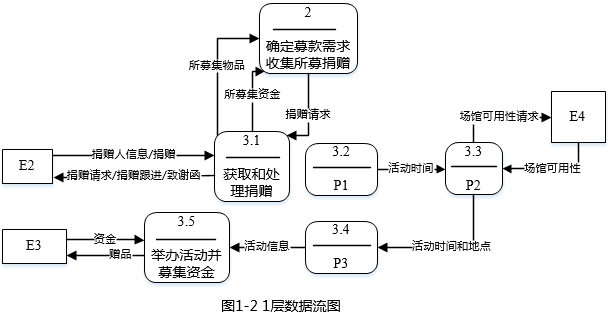
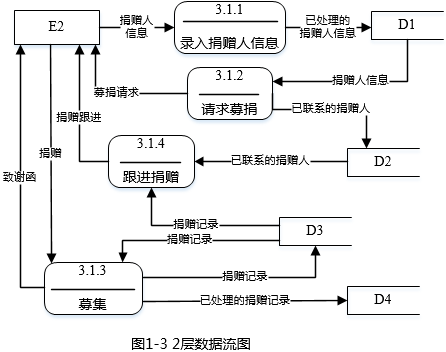
在建模DFD时,需要对有些复杂加工(处理)进行进一步精化,图1-2为图1-1中处理3的进一步细化的1层数据流图,图1-3为图1-2中3.1进一步细化的2层数据流图。补全1-2中加工P1、P2和P3的名称和图1-2与图1-3中缺少的数据流。
【问题3】(4分)
使用说明中的词语,给出图1-3中的数据存储D1~D4的名称。
答案与解析
- 试题难度:较难
- 知识点:数据流图>数据流图
- 试题答案:
【问题1】
E1:志愿者 E2:捐赠人 E3:募捐机构 E4:场馆
【问题2】
P1:确定活动时间范围 P2:搜索场馆 P3:推广募捐活动
图1-2缺少的数据流:
名称:活动请求 起点:2确定募款需求收集所募捐款 终点:P1
名称:所募集资金 起点:3.5举办活动并募集资金 终点:2确定募捐需求收集所募捐款
图1-3缺失的数据流:
名称:捐赠请求 起点:2确定募款需求收集所募捐款 终点:3.1.3募集
名称:所募集资金 起点:3.1.3募集 终点:2确定募款需求收集所募捐款
名称:所募集物品 起点:3.1.3募集 终点:2确定募款需求收集所募捐款
或后两条数据流合并为:
名称:所募集捐赠 起点:3.1.3募集 终点:2确定募款需求收集所募捐款
【问题3】
D1:捐赠人信息表 D2:已联系的捐赠人信息表 D3:捐赠表 D4:已经处理的捐赠表。 - 试题解析:
解答这类题目有两个原则:
1.第一个原则是紧扣试题系统说明部分,数据流图与系统说明有着严格的对应关系,系统说明部分的每一句话都能对应到图中来,解题时一句一句的对照图来分析。
2.第二个原则即数据平衡原则,这一点在解题过程中也是至关重要的。数据平衡原则有两方面的含义,一方面是分层数据流图父子图之间的数据流平衡原则,另一方面是每张数据流图中输入与输出数据流的平衡原则。
【问题1】
根据0层数据流管理志愿者中的募捐任务给志愿者发送加入邀请,邀请跟进,工作任务和管理志愿者提供的邀请响应可知E1为志愿者;从录入捐款人信息,向捐赠人发送募捐请求,;向捐赠人发送致谢函等可知E2为捐赠人;从根据说明中从募捐机构获取资金并向其发放赠品可知E3为募捐机构;根据向场馆发送可用性请求和获得场所可用性可知E4为场馆。
【问题2】
根据1层数据流图中P1的输出流活动时间再结合说明可知P1为确定活动时间范围;从加工P2的输入流活动时间和输出流场馆可用性请求和活动时间和地点可知P2为搜索场馆;说明中根据活动时间和地点推广募捐活动,根据相应的活动信息举办活动,再结合P3的输入输出流可知P3为推广募捐活动。
比较0层和1层中的数据流可知,P1加工只有输出流,故缺少输出流,根据说明可知需要根据活动请求才能确定P1,故该数据流为活动请求,在0层数据流中活动请求的起始加工为确定募款需求收集所募捐赠,故可知答案。又因为对于加工3.5只有输入数据流资金,没有输出数据流,因此缺失数据流所募集资金,起点为加工3.5,又因为加工2为确定募捐请求和收集所募捐赠,所以该数据流终点为加工2。
比较1层图和2层图的数据流可知,2层图是1层图中加工3.1的分解,而对于加工3.1与加工2之间,在父图中存在3条数据流,而子图中没有给出,因此子图缺失数据流:捐赠请求,起点为2,终点为3.1.3;所募集物品,起点为3.1.3,终点为2;所募集资金,起点为3.1.3,终点为2。或者将后面两条数据流合并为所募集捐赠。
【问题3】
根据最后的说明和2层数据流可知D1为捐赠人信息表,D2为已联系的捐赠人信息表,D3为捐赠表,D4为已经处理的捐赠表。
第 2 题
【逻辑结构设计】
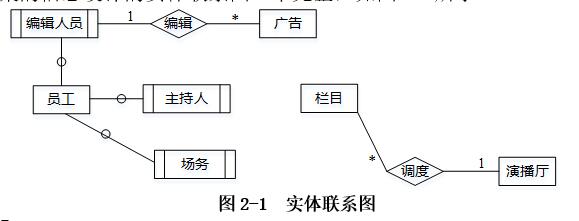
根据概念模式设计阶段完成的实体联系图,得出如下关系模型(不完整):
演播厅(房间号,房间面积)
栏目(栏目名称,播出时间,时长)
广告(广告编号,销售价格, (1) )
员工(工号,姓名,性别,出生日期,电话,住址)
主持人(主持人工号, (2) )
插播单( (3) ,播出时间)
调度单( (4) )
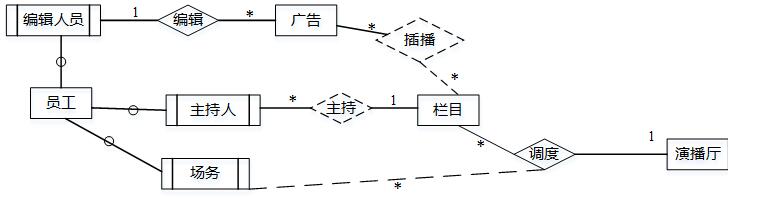
【问题1】(7分)
补充图2-1中的联系和联系类型。
【问题2】(5分)
根据图2-1,将逻辑结构设计阶段生产的关系模型的空(1)~(4)补充完整,并用下划线指出(1)~(4)所在关系模型的主键。
【问题3】(3分)
现需要记录广告商信息,增加广告商实体。一个广告商可以提供多条广告,一条广告只由一个广告商提供。请根据该要求,对图2-1进行修改,画出修改后的实体间联系和联系的类型。
答案与解析
- 试题难度:较难
- 知识点:数据库设计>数据库设计
- 试题答案:
【问题1】
【问题2】
(1)编辑人员工号 主键:广告编号
(2)栏目名称 主键:主持人工号
(3)栏目名称、广告编号 主键:栏目名称、广告编号
(4)栏目名称、房间号、场务工号 主键:栏目名称、房间号、场务工号
【问题3】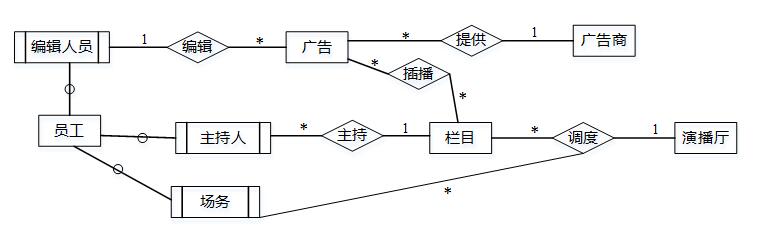
- 试题解析:
本题考查数据库设计,设计考点有:数据库的概念结构设计和逻辑结构设计。
【问题1】
由说明每档栏目可以插播多条广告,每条广告可以在多档栏目中插播,可知广告和栏目之间是插播关系且为多比多;一个主持人可以主持一个栏目,一个栏目可以有多个主持人,故主持人和栏目之间是多比一的关系;一销售档栏目只会占用一个演播厅,但会使用多名场务来进行演出协调,故三者之间存在三元联系,其中场务为多du。补充关系如图1所示。
【问题2】
逻辑结构设计中,广告实体中缺少编辑人员工号,主键为广告编号;主持人实体与栏目实体为多对一的关系,故将栏目中主键栏目名称加入到主持人实体中,主键为主持人工号;插播单为栏目实体和广告实体这种多对多的关系所派生出的实体,其中记录了栏目和广告的主键信息,故插播单中缺少栏目名称和广告编号信息,又因为题干说明电视台根据栏目来插播广告,因此主键为栏目名称和广告编号;调度单为场务、栏目和演播厅实体这种多对多的关系所派生的实体,故其记录了栏目名称,房间号,场务工号,主键为栏目名称、房间号和场务工号。
【问题3】
因为一个广告商可以提供多条广告,一条广告只能由一个广告商提供,故广告商和广告之间的关系为一对多,其关系如图所示。
第 3 题
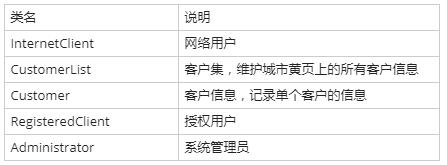
表3-1 类列表

【问题1】(5分)
根据说明中的描述,给出图3-1中A1和A2处所对应的参与者,UC1和UC2所对应的用例以及(1)处的关系。
【问题2】(7分)
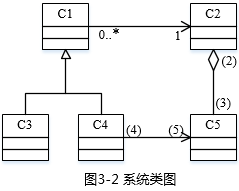
根据说明中的描述,给出图3-2中C1~C5所对应的类名(表3-1中给出的类名)和(2)~(5)处所对应的多重度。
【问题3】(3分)
认定类是面向对象分析中非常关键的一个步骤。一般首先从问题域中得到候选类集合,在根据相应的原则从该集合中删除不作为类的,剩余的就是从问题域中认定出来的类。简要说明选择候选类的原则,以及对候选类集合进行删除的原则。
答案与解析
- 试题难度:较难
- 知识点:UML建模>用例图
- 试题答案:
【问题1】
A1网络用户;A2授权用户;UC1更新信息;UC2认证;
(1)<<include>>
【问题2】
C1:InternetClient;C2:CustomerList;C3:Administrator;C4:RegisteredClient
C5:Customer;
(2)1 ;(3)0…*;(4)0..1;(5)0..1
【问题3】
候选类的选择运用了良性依赖原则“不会在实际中造成危害的依赖关系,都是良性依赖”和接口隔离原则(ISP)。 - 试题解析:
本题考查面向对象分析中的类图、用例图。
【问题1】
用例图中,A1可以搜索信息,A2由A1派生且A2参与了两个用例,根据题中的说明(1)和(2),可知A1为网络用户,A2为授权用户;由用例UC1和登录用例之间存在关系,可知UC1为更新信息,因为更新信息前必须登录,所以更新信息用例包含登录用例,它们之间的关系为include。
【问题2】
本问题查考类图。考查类图的层次结构和多重度。首先根据C2和C5之间存在聚合关系,满足要求的类应该是客户与客户集,又因为其中C2为整体,C5为部分,所以C2为客户集,C5为客户信息。
又因为图中更有两个非常明显的继承结构,即C3和C4继承与C1,且C1与C2是多对一的关系,根据C2为
客户集 ,又因为说明(1)中任何网络用户都可以搜索客户信息,即C1为网络用户,由此很明显得出C3和C4在授权用户和系统管理员中选取。再由C4和C5之间的关联关系,且C5为客户信息 ,通过题意可以了解到
客户信息 是由其成为授权用户之后,自己发布与管理的,而管理员在此并未进行职责描述(管理员对客户的删除,可以通过其父类对客户集进行操作),可以不管他。用户C4显然就是授权用户,由此得出C3为管理员。由此(2)~(5)的多重度就显而易见,(2)为1,(3)为0…*,(4)为1,(5)为1。</p>
【问题3】
候选类的选择运用了良性依赖原则“不会在实际中造成危害的依赖关系,都是良性依赖”和接口隔离原则(ISP)。ISP:使用多个专门的接口比使用单一的总接口要好。一个类对另外一个类的依赖性应当是建立在最小的接口上的。一个接口代表一个角色,不应当将不同的角色都交给一个接口。没有关系的接口合并在一起,形成一个臃肿的大接口,这是对角色和接口的污染。“不应该强迫客户依赖于它们不用的方法。接口属于客户,不属于它所在的类层次结构。”这个说得很明白了,再通俗点说,不要强迫客户使用它们不用的方法,如果强迫用户使用它们不使用的方法,那么这些客户就会面临由于这些不使用的方法的改变所带来的改变。
第 4 题
设有m台完全相同的机器运行n个独立的任务,运行任务i所需的时间为ti,要求确定一个调度方案,使得完成所有任务所需要的时间最短。
假设任务已经按照其运行时间从大到小排序,算法基于最长运行时间作业优先的策略,按顺序先把每个任务分配到一台机器上,然后将剩余的任务依次放入最先空闲的机器。
【C代码】
下面是算法的C语言实现。
1.常量和变量说明
m:机器数
n:任务数
t[]:输入数组,长度为n,下标从0开始,其中每个元素表示任务的运行时间,下标从0开始。
s[][]:二维数组,长度为m*n,下标从0开始,其中元素s[i][j]表示机器i运行的任务j的编号。
d[]:数组,长度为m其中元素d[i]表示机器i的运行时间,下标从0开始。
count[]:数组,长度为m,下标从0开始,其中元素count[i]表示机器i运行的任务数。
i:循环变量。
j:循环变量。
k:临时变量。
max:完成所有任务的时间。
min:临时变量。
2.函数schedule
void schedule(){
int i,j,k,max=0;
for( i=0;i<m;i++){
d[i]=0;
for(j=0;j<n;j++){
s[i][j]=0;
}
}
for(i=0;i<m;i++){ //分配前m个任务
s[i][0]=i;
(1) ;
count[i]=1;
}
for( (2) ;i<n;i++){ //分配后n-m个任务
int min = d[0];
k=0;
for(j=1;j<m;j++){ //确定空闲时间
if(min>d[j]){
min = d[j];
k=j; //机器k空闲
}
}
(3) ;
count[k] = count[k]+1;
d[k] = d[k]+t[i];
}
for(i =0;i<m;i++){ //确定完成所有任务所需要的时间
if( (4) ){
max=d[i];
}
}
}
【问题1】(8分)
根据说明和C代码,填充C代码中的空(1)~(4)。
【问题2】(2分)
根据说明和C代码,该问题采用了 (5) 算法设计策略,时间复杂度 (6) (用O符号表示)
【问题3】(5分)
考虑实例m=3(编号0~2),n=7(编号0~6),各任务的运行时间为{16,14,6,5,4,3,2}。则在机器0、1和2上运行的任务分别为(7)、(8)和(9)(给出任务编号)。从任务开始运行到完成所需的时间为(10)。
答案与解析
- 试题难度:较难
- 知识点:数据结构与算法应用>贪心法
- 试题答案:
【问题1】
(1)d[i] = t[i] (2)i=m (3)s[k][count[k]]=i (4)max<d[i]
【问题2】
(5)贪心 (6)O(mn)
【问题3】
(7)0 (8)1、5 (9)2、3、4、6 (10)17 - 试题解析:
本题考查算法的设计和分析技术中的贪心算法。
贪婪算法(Greedy algorithm)是一种对某些求最优解问题的更简单、更迅速的设计技术。用贪婪法设计算法的特点是一步一步地进行,常以当前情况为基础根据某个优化测度作最优选择,而不考虑各种可能的整体情况,它省去了为找最优解要穷尽所有可能而必须耗费的大量时间,它采用自顶向下,以迭代的方法做出相继的贪心选择,每做一次贪心选择就将所求问题简化为一个规模更小的子问题,通过每一步贪心选择,可得到问题的一个最优解,虽然每一步上都要保证能获得局部最优解,但由此产生的全局解有时不一定是最优的,所以贪婪法不要回溯。
【问题1】
根据上述思想和题中的说明,首先将s[][]和d[]数组初始化为0,然后要做的就是按要求“算法基于最长运行时间作业优先的策略,按顺序先把每个任务分配到一台机器上”,可以推断(1)处为d[i] = t[i],此后需将剩下的n-m个任务按顺序分配给空闲的机器,故(2)处将i初始化为以m为起始的任务,即i=m,(3)处所在的位置是分配后n-m个任务,在这个过程中,必须要对s矩阵的内容进行修改,但目前已经出的代码没有这个内容,所以此处必然是对s的修改。从对s矩阵的注释可以了解到,s[i][j]表示机器i运行的任务j的编号,此时涉及任务的机器号为k,而待分配的任务i是机器的第count[k]个任务,即s[k][count[k]]=i,(4)处已经完成了任务的运行,此处需要统计所有机器所运行任务的最长时间,对于每个机器i的运行时间为d[i],存在d[i]大于当前的最大时间Max,就将当前机器的运行时间d[i]赋给Max,即Max<d[i]。
【问题2】
根据以上分析,(5)处采用了贪心算法的策略,而时间复杂度由算法中的两个嵌套for循环和两个非嵌套for循环确定,即为O(mn)。
【问题3】
根据题中算法的思想将任务的前三个任务分给三个机器,再将接下来的任务分给最先空闲的机器,故可知机器0运行任务0,机器1运行任务1、5,机器3运行任务2、3、4、6;且运行的最长时间为17。
第 5 题
现要求实现一个能够自动生成求职简历的程序,简历的基本内容包括求职者的姓名、性别、年龄及工作经历。希望每份简历中的工作经历有所不同,并尽量减少程序中的重复代码。
现采用原型模式(Prototype)来实现上述要求,得到如图5-1所示的类图。

图5-1 类图
【C++代码】
#include<string>
using namespace std;
class Cloneable{
public:
(1) ;
};
class workExperience:public Cloneable{ //工作经历
private:
string workData;
string company;
public:
Cloneable * clone(){
(2) ;
Obj->workDate= this->workDate;
Obj->company = this->company;
return Obj;
}
//其余代码省略
};
class Resume:public Cloneable{ //简历
private:
string name;
string sex;
string age;
WorkExperience * work;
Resume(WorkExperience * work){
this->work = (3) ;
}
public:
Resume(string name){/*实现省略*/}
void SetPersonInfo(string sex,string age){/*实现省略*/}
void SetWorkExperience(string workDate,string company){/*实现省略*/}
Cloneable * Clone(){
(4) ;
Obj->name = this->name;
Obj->sex = this->sex;
Obj->age = this->age;
return Obj;
}
};
int main(){
Resume * a = new Resume(“张三”);
a->SetPersonInfo(“男”,“29”);
a-> SetWorkExperience(“1998-2000”,“XXX公司”);
Resume * b = (5) ;
b-> SetWorkExperience(“2001-2006”,“YYY公司”);
return 0;
}
答案与解析
- 试题难度:较难
- 知识点:面向对象程序设计>C++程序设计
- 试题答案:
(1)virtual Cloneable *Clone()=0
(2)WorkExperience *obj = new WorkExperience()
(3)(WorkExperience *) work->Clone()
(4)Resume *obj = new Resume(this->work)
(6)(Resume *)a->Clone() - 试题解析:
本题考查原型模型的概念及应用。
原型模型的主要思想: 先借用已有系统作为原型模型,通过“样品”不断改进,使得最后的产品就是用户所需要的。 原型模型通过向用户提供原型获取用户的反馈,使开发出的软件能够真正反映用户的需求。同时,原型模型采用逐步求精的方法完善原型,使得原型能够“快速”开发,避免了像瀑布模型一样在冗长的开发过程中难以对用户的反馈作出快速的响应。相对瀑布模型而言,原型模型更符合人们开发软件的习惯,使目前较流行的一种实用软件生存期模型。
Prototype模式其实就是常说的“虚拟构造函数”一个实现,C++的实现机制中并没有支持这个特性,但是通过不同派生类实现的Clone接口函数可以完成与“虚拟构造函数”同样的效果。
题中声明一个虚拟基类,所有的原型都是从这个基类继承,(1)所代表的就是这个基类中的纯虚函数,需要供继承者自行实现,即为virtual Cloneable * Clone()=0,(1)声明一个抽象基类,并定义clone()函数为纯虚函数。然后根据基类实例化各个子类,并且实现赋复制构造函数,并实现clone()函数,由此可知(2)处为WorkExperience * Obj,(3)处为Work,(4)处为Resume * Obj。在main函数中实现Resume * b对*a的复制,故根据C++语法(5)中为a->Clone()。注:解析部分只是给出思路,没有遵循相关语法。
第 6 题
现要求实现一个能够自动生成求职简历的程序,简历的基本内容包括求职者的姓名、性别、年龄及工作经历。希望每份简历中的工作经历有所不同,并尽量减少程序中的重复代码。
现采用原型模式(Prototype)来实现上述要求,得到如图6-1所示的类图。
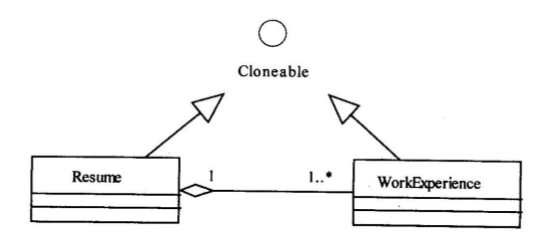
图6-1 类图
【Java代码】
public class WorkExperience (1) Cloneable{ //工作经历
private String workDate;
private String company;
public Object clone(){
(2) ;
Obj.workDate= this.workDate;
Obj.company = this.company;
return Obj;
}
//其余代码省略
}
public class Resume (3) Cloneable{ //简历
private String name;
private String sex;
private String age;
private WorkExperience work;
public Resume(string name){
this.name = name;
work = new WorkExperience();
}
private Resume(WorkExperience work){
this.work = (4) ;
}
public void SetPersonInfo(string sex,string age){/*实现省略*/}
public void SetWorkExperience(string workDate,string company){/*实现省略*/}
public Object clone(){
Resume Obj = (5) ;
return Obj;
}
}
Class WorkResume{
public static void main(){
Resume a = new Resume(“张三”);
a.SetPersonInfo(“男”,“29”);
a.SetWorkExperience(“1998-2000”,“XXX公司”);
Resume b = (6) ;
b. SetWorkExperience(“2001-2006”,“YYY公司”);
}
}
答案与解析
- 试题难度:较难
- 知识点:面向对象程序设计>Java程序设计>原型(克隆)模式
- 试题答案:
(1)implements
(2)WorkExperience obj = new WorkExperience()
(3)implements
(4)(WorkExperience)work.Clone()
(5) new Resume(this.work)
(6)(Resume)a.Clone() - 试题解析:
本题考查原型模型的概念及应用。
原型模型的主要思想: 先借用已有系统作为原型模型,通过“样品”不断改进,使得最后的产品就是用户所需要的。 原型模型通过向用户提供原型获取用户的反馈,使开发出的软件能够真正反映用户的需求。同时,原型模型采用逐步求精的方法完善原型,使得原型能够“快速”开发,避免了像瀑布模型一样在冗长的开发过程中难以对用户的反馈作出快速的响应。相对瀑布模型而言,原型模型更符合人们开发软件的习惯,使目前较流行的一种实用软件生存期模型。
所有java类都继承自java.lang.Object,而object类提供一个clone()方法,可以将一个java对象复制一份。因此在java中可以直接使用Object提供的clone()方法来实现对象的克隆。能够实现克隆的java类必须实现一个标识接口Cloneable,表示这个java支持复制。
题中WorkExperience类和Resume类需要实现Cloneable接口,故(1)和(3)为implements,WorkExperience中需要实现Clone()方法,并将自身复制一份,有下面代码可知(2)为WorkExperience obj = new WorkExperience()。Resume类中的私有构造方法实现WorkExperience深复制,故(4)中为(WorkExperience)work.clone(),而Resume类中Clone方法实现自身的复制,故(5)中为new Resume(this.work)。
在main中实现Resume b对a的复制,故(6)中为(Resume)a.Clone()。