200905程序员下午真题
第 1 题
(共15分)
阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入答题纸的对应栏内。
【说明】
下面的流程图采用公式 计算 的近似值。
设x位于区间 (0,1), 该流程图的算法要点是逐步累积计算每项Xn/n!的值 (作为T),再逐步累加T 值得到所需的结果S。当T 值小于10-5时,结束计算。

答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:
(1)S (2) x/n (3)T<0.00001 (4) S+T (5)n+1→n
- 试题解析:
本题属于简单的数值计算应用。
人们经常需要近似计算初等函数的值。在计算机内部,近似计算初等函数的值最常用的方法就是将初等函数按幂级数展开,再计算前若干项的和,直到计算误差满足要求为止。
在设计算法时应考虑,对于自变量的大致范围,如何展开级数,使级数收敛的速度比较快,在计算过程中,怎样估计计算的误差是否己经满足要求。
由于初等函数在计算机中需要频繁使用,因此设计高效率的算法非常重要。这种精益求精的设计是全世界许多专家已经反复探索并实现了的。
对于一般程序员来说,只要求基本的、正确的算法设计,并实现编程就可以了。
本题中,为了计算指数函数ex的值,已经给出了基本的算法,以及计算过程中控制误差终止计算的方法。本题主要的重点是如何设计计算流程,实现级数前若干项的求和,以及判断终止计算的条件。
级数求和通常采用逐项累加的方法。设S为累加的结果,T为动态的项值,那么,S+T→S就能完成各项的累加。
由于本题中T= xn/n!,如果每次都直接计算该项的值,则计算量会很大。这种项的特殊性表明,后一项与前一项有简单的关系Tn=Tn-1*x/n。充分利用前项的计算结果则会大大减少计算量。这是程序员需要掌握的基本技巧。
本题的流程图中,一开始先输入自变量x,接着对一些变量赋初值。变量n与T需要赋初值,对变量S也应赋初值。级数项号n的初值为1,逐次进行累积的T也应有初值1,逐次进行累加的S则应有初值0或级数第1项的值1。从随后的流程看,S应有初值1,本题(1)处填S。
项值T的累积公式应是T*x/n→T,所以本题中(2)处应填x/n 。
流程图中(3)处为判断计算过程结束的条件,按照题中的要求,当T<105时计算过程结束,因此,(3)处应填T<0.00001。
流程图中(4)处需要累加S,实现S+T→S,因此,(4)处应填S+T。
流程图中(5)处应对级数的项号n进行自增,因此,(5)处应填n+1→n。
第 2 题
(共15分)
阅读以下说明和C 函数,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
C 语言常用整型(int)或长整型(long)来说明需要处理的整数,在一般情况下可以满足表示及运算要求,而在某些情况下,需要表示及运算的整数比较大,即使采用更长的整型(例如,long long类型,某些C系统会提供)也无法正确表示,此时可用一维数组来表示一个整数。
假设下面要处理的大整数均为正数,将其从低位到高位每4位一组进行分组(最后一组可能不足4位),每组作为1个整数存入数组。例如,大整数2543698845679015847在数组A 中的表示如下(特别引入-1表示分组结束):
![]()
在上述表示机制下,函数add_large_number(A,B,C)将保存在一维整型数组A和B中的两个大整数进行相加,结果(和数)保存在一维整型数组C中。
【C 函数】
void add_large_number(int A[], int B[], int C[])
{
int i, cf ; /*cf存放进位*/
int t, *p; /*t为临时变量,p为临时指针*/
cf = (1) ;
for(i = 0; A[i]>-1 && B[i]>-1 ; i++) {
/*将数组A、B 对应分组中的两个整数进行相加*/
t = (2) ;
C[i] = t % 10000;
cf = (3) ;
}
if ( (4) ) p = B;
else p = A;
for( ; p[i]>-1; i++) { /*将分组多的其余各组整数带进位复制入数组C*/
C[i] = (p[i] + cf) %10000; cf = (p[i] + cf) /10000;
}
if ( cf > 0 ) C[i++] = cf;
(5) = -1; /*标志"和数"的分组结束*/
}
答案与解析
- 试题难度:较难
- 知识点:C程序设计>C程序设计
- 试题答案:
(1) 0
(2) A[i]+ B[i]+cf,或其等价形式
(3) t/10000,或(A[i]+ B[i]+cf)/10000,或其等价形式
(4) A[i]==-1,或B[i]>-1,或其等价形式
(5) C[i],或其等价形式 - 试题解析:
本题考查C程序设计基本能力。
用整型数组表示大整数时,一个数组元素可以表示整数的一位,也可以表示多位,为提高存储空间的利用率并提高运算速度,本题中采用一个数组元素表示4位的整数。在这种表示方式下进行两个大整数的相加运算时,主要考虑进位的处理。
题目中用变量cf来表示进位情况,显然,开始相加前尚未产生进位,所以cf的初始值为0,因此空(1)处应填入0。
由于相加时需要对齐,并且根据程序中C[i] = t%10000对t的使用,空(2)处应填入A[i]十B[i] + cf。该运算同时产生下一步运算需要使用的进位值cf,因此空(3)处应填入t /10000或(A[i]+ B[i]+cf)/10000。
参与相加运算的两个整数位数不一定相同,因此,尚有剩余的那个整数的其余位数应带进位记录下来,程序中设置的临时指针p指向保存这个整数的数组。根据题中设置的标志A[i]>-1&& B[i]>-1,若数组A表示的整数己经结束,则满足A[i]==-1,否则满足B[i]==-1,因此考查if语句的逻辑后,空(4)处应填入A[i]==-1,或B[i] >-l 。
另外,当两个整数相加后产生进位,此时可能需要将此进位结果作为和数来记录,以9999 9999 4567与5555相加为例说明,和数1 0000 0000 0122比9999 9999 4567还要多1位,并且在数组中表示时的分组数也多1个。if语句if(cf >0)C[i++]=cf;即用来处理这种情况。空(5)处的语句用于为表示和数的数组设置标志,因此应填入C[i]。
若要输出用数组表示的整数,则可用以下程序段:
void print_ arr(int arr[],int n)
{ /*输出arr[n-1]~arr[0]中的数据*/
int i;
printf("%4d",arr[n-1]);
for (i= n-2;i>=0;i--){
printf("%d%d",arr[i]/1000,(arr[i]%1000)/100);
printf("%d%d",(arr[i]%100)/10, arr[i]%10) ;
}
printf ("\n") ;
}
第 3 题
(共15分)
阅读以下说明、C 函数和问题,将解答填入答题纸的对应栏内。
【说明】
二叉查找树又称为二叉排序树,它或者是一棵空树,或者是具有如下性质的二叉树:
若它的左子树非空,则其左子树上所有结点的键值均小于根结点的键值;
若它的右子树非空,则其右子树上所有结点的键值均大于根结点的键值;
左、右子树本身就是二叉查找树。
设二叉查找树采用二叉链表存储结构,链表结点类型定义如下:
typedef struct BiTnode{
int key_value; /*结点的键值,为非负整数*/
struct BiTnode *left,*right; /*结点的左、右子树指针*/
}*BSTree;
函数find_key(root, key)的功能是用递归方式在给定的二叉查找树(root指向根结点)中查找键值为key的结点并返回结点的指针;若找不到,则返回空指针。
【函数】
BSTree find_key(BSTree root, int key)
{
if ( (1) )
return NULL;
else
if (key == root-> key_value)
return (2) ;
else if (key < root -> key_value)
return (3) ;
else
return (4) ;
}
【问题1】
请将函数find_key中应填入(1)~(4)处的字句写在答题纸的对应栏内。
【问题2】
若某二叉查找树中有n个结点,则查找一个给定关键字时,需要比较的结点个数取决于 (5) 。
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:
(1) !root,或root=0,或root==NULL
(2) root
(3) find_key(root→left, key)
(4) find_key(root→right, key)
(5)该关键字对应结点在该二叉查找树所在层次(数)或位置,或者该二叉树中从根结点到该关键字对应结点的路径长度 - 试题解析:
本题考查数据结构的应用、指针和递归程序设计。
根据二叉查找树的定义,在一棵二叉查找树上进行查找时,首先用给定的关键字与树根结点的关键字比较,若相等,则查找成功;若给定的关键字小于树根结点的关键字,则接下来到左子树上进行查找,否则接下来到右子树上进行查找。如果在给定的二叉查找树上不存在与给定关键字相同的结点,则必然进入某结点的空的子树时结束查找。因此,空(1)处填入!root表明进入了空树;空(2)处填入root表明返回结点的指针;空(3)处填入find_key(root→left, key)表明下一步到左子树上继续查找;空(4)处填入find_key(root→right, key)表明下一步到右子树上继续查找。
显然,在二叉排序树上进行查找时,若成功,则查找过程是走了一条从根结点到达所找结点的路径。例如,在下图所示的二叉排序树中查找62,则依次与46、54、101和62作了比较。因此,在树中查找一个关键字时,需要比较的结点个数取决于该关键字对应结点在该二叉查找树所在层次(数)或位置。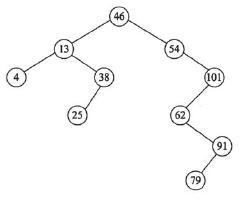
第 4 题
(共15 分)
阅读以下两个说明、C 函数和问题,将解答写入答题纸的对应栏内。
【说明1】
函数 main()的功能旨在对输入的一个正整数 n,计算12+22+32+...+n2 ,但是对该函数进行测试后没有得到期望的结果。
【C函数1】

1. 输入5测试上述main函数时,显示结果如下所示。

2. 将行号为7的代码修改为:printf("n = %d\nresult: %d\n", n, sum); 并再次输入5测试main函数,显示结果如下所示。

【问题1】(9 分)
请给出上述main函数中需要修改的代码行号,并给出修改后的整行代码。 行号 修改后的整行代码

【说明2】
函数test_f2()编译时系统报告有错,修改后得到函数f2_B()。对函数f2_B()进行编译时顺利通过,在某些C 系统中执行时却由于发生异常而不能正确结束。
【C函数2】

【问题2】(6 分)
(1)请指出函数test_f2中不能通过编译的表达式;
(2)请指出可能导致函数f2_B 运行异常的表达式。
()(共15 分)
阅读以下两个说明、C 函数和问题,将解答写入答题纸的对应栏内。
【说明1】
函数 main()的功能旨在对输入的一个正整数 n,计算 ,但是对该函数进行测试后没有得到期望的结果。
【C函数1】
1. 输入5测试上述main函数时,显示结果如下所示。
2. 将行号为7的代码修改为:printf("n = %d\nresult: %d\n", n, sum); 并再次输入5测试main函数,显示结果如下所示。
【问题1】(9 分)
请给出上述main函数中需要修改的代码行号,并给出修改后的整行代码。 行号 修改后的整行代码
【说明2】
函数test_f2()编译时系统报告有错,修改后得到函数f2_B()。对函数f2_B()进行编译时顺利通过,在某些C 系统中执行时却由于发生异常而不能正确结束。
【C函数2】
【问题2】(6 分)
(1)请指出函数test_f2中不能通过编译的表达式;
(2)请指出可能导致函数f2_B 运行异常的表达式。
答案与解析
- 试题难度:较难
- 知识点:
- 试题答案:
问题1:本表中的解答无次序要求。

注:在第3行、第4行中增加语句sum=0;,或者将sum=0加在第5行的正确位置也可以,即
For(k=1,sum=0; k<=n; k++) 或者for(sum=0, k=1;k<=n; k++)
问题2:
(1)str++
(2)*str=‘a’ - 试题解析:
本题考查C程序的调试和排错能力。
【问题1分析】程序中的错误可分为语法错误和语义错误,其中语义错误又分为静态语义错误和动态语义错误。语法错误和静态语义错误可在编译时检测出,动态语义错误则在程序运行时才能表现出来。
C函数1所示代码己经通过编译,而运行结果不对。虽然直接的运行结果为输出变量sum的值,但其计算过程却与n和k的值相关。因此,可以从每个变量初始值的设定、修改方式和引用方式考查。对于变量k,其初始值由语句表达式k=1确定,修改方式为k++,引用处为循环条件k<=n和sum += k*k,没有不当之处。
对于变量n,其初始值由scanf(“%d”,n)确定,引用处为循环条件k<=n,得到初始值后不再进行修改。然而从第2次测试main函数时显示的结果可知,n的值并不是为其输入的值5,显然对n值的设定有误,仔细检查scanf函数的调用可知,其中的n之前缺少了取地址运算符号&,正确的函数调用为scan(“%d”,&n)。
对于变量n,其修改和引用处分别为sum+= k*k、printf(“result: %d\n”, sum),没有对其进行初始化,而是在一个未知的数值上开始累加,因此,sum最后的结果无法符合预期的值。另外,函数中还有一个比较隐蔽的错误,就是语句结束符号“;”的不当使用,导致循环语句for(k = 1; k<=n; k++)只是将k的值从1递增到n+1,没有产生实质的运算结果,使得sum的值不会随着sum+=k*k发生变化。
【问题2分析】 函数test_f2()编译时系统报告有错,检查其函数体,其中的char str[]=“test string”;表明str是一位数组名,因此,*str表示str[0],通过*str = ‘a’;为str[0]赋值显然是允许的。出错的地方是str++,在C语言中,数组名是指针(地址)常量,是不允许修改的,str++试图修改指针常量str,因此编译时会报告错误。若将str修改为指针变量,即在函数。F2_B()中定义为char *str=“test string”,则可以通过str++修改str的值,使得str可以指向不同的字符对象。使某些C系统执行f2_B()时发生异常的表达式是*str=‘a’,该表达式要修改str所指对象的值,而定义char *str =“test string”则令str指向了一个字符串常量,由于此常量在运行过程中不可修改,因此试图通过指针str修改常量的动作导致了异常。
第 5 题
(共15 分)
阅读以下说明和C++代码,将应填入 (n) 处的字句写在答题纸的对应栏内。
【说明】
C++标准模板库中提供了map模板类,该模板类可以表示多个“键-值”对的集合,其中键的作用与普通数组中的索引相当,而值用作待存储和检索的数据。此外,C++模板库还提供了pair模板类,该类可以表示一个“键-值”对。pair对象包含两个属性:first和second,其中first表示“键-值”中的“键” ,而second表示“键-值”中的“值”。
map 类提供了 insert 方法和 find 方法,用于插入和查找信息。应用时,将一个 pair对象插入(insert)到 map 对象后,根据“键”在 map 对象中进行查找(find),即可获得一个指向pair对象的迭代器。
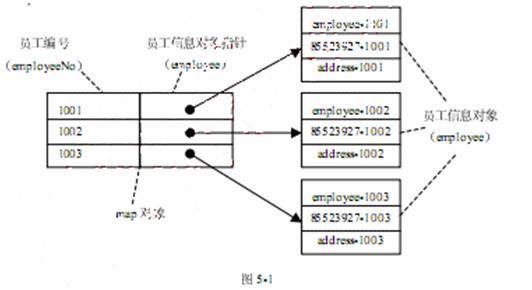
下面的 C++代码中使用了 map和 pair 模板类,将编号为 1001、1002、1003 的员工信息插入到map对象中,然后输入一个指定的员工编号,通过员工编号来获取员工的基本信息。员工编号为整型编码,员工的基本信息定义为类employee。
map对象与员工对象之间的关系及存储结构如图5-1所示。
【C++代码】
#include <iostream>
#include <map>
#include <string>
using namespace std ;
class employee{
(1) :
employee(string name,string phoneNumber, string address){
this->name = name;
this->phoneNumber = phoneNumber;
this->address = address;
}
string name;
string phoneNumber;
string address;
};
int main( )
{
map <int, employee*> employeeMap;
typedef pair <int, employee*> employeePair;
for (int employIndex = 1001; employIndex <= 1003; employIndex++){
char temp[10] ; //临时存储空间
_itoa(employIndex,temp,10); //将employIndex转化为字符串存储在temp中
string tmp( (2) ); //通过temp构造string对象
employeeMap. (3) ( employeePair ( employIndex,
new employee("employee-" + tmp,
"85523927-"+tmp,
"address-"+tmp)
)
); //将员工编号和员工信息插入到employeeMap对象中
}
int employeeNo = 0;
cout << "请输入员工编号:";
(4) >> employeeNo; //从标准输入获得员工编号
map<int,employee*>::const_iterator it;
it = (5) .find(employeeNo); //根据员工编号查找员工信息
if (it == employeeMap.end()) {
cout << "该员工编号不存在 !" << endl;
return -1;
}
cout << "你所查询的员工编号为:" << it->first << endl;
cout << "该员工姓名:" << it->second->name << endl;
cout << "该员工电话:" << it->second->phoneNumber << endl;
cout << "该员工地址:" << it->second->address << endl;
return 0;
}
答案与解析
- 试题难度:较难
- 知识点:
- 试题答案:
(1)public (2)temp (3) insert (4) cin (5) employeeMap
- 试题解析:
本题主要考查C++程序设计语言中类库的使用。题干中已经给出了Map类和Pair类的使用方式,Map类主要用于存储一组员工的信息,而Pair类则主要用于建立员工号和员工信息的对应关系,员工信息主要使用类employee的对象来存储。C++语言的类生成对象时,需要调用类的构造方法,因此,employee的构造方法应该为公有构造方法,空缺(1)处的答案应该为public;空缺(2)处的代码主要是根据字符数组temp[10]来构造一个string对象,参数应为temp;空缺(3)处的代码是构造员工对象,并将员工对象和员工编号放入一个Pair对象中,再将Pair对象插入到employeeMap中,根据题干说明,Map类中insert方法完成插入对象的功能,因此,空缺(3)处应该填入insert;空缺(4)处的自的是从标准输入中获得员工编号,标准类库中已经定义了标准输入为cin;空缺(5)处是根据用户输入的员工编号,查取员工信息,Map类中的find方法可完成该功能,而当前员工的编号和员工信息都存储在Map类的实例employeeMap中。
第 6 题
阅读以下说明和Java代码,将应填入 (n) 处的字句写在答题纸的对应栏内。
【说明】
java.util包中提供了HashMap模板类,该模板类可以表示多个“键-值”对的集合,其中 “键” 的作用与普通数组中的索引相当,而 “值” 用作待存储和检索的数据。 HashMap实现了Map接口。在Map接口中定义了put和get方法,put方法表示Map对象中加入一个“键-值”对,get方法则通过“键”来获取其对应的“值” 。
下面的Java代码中使用了HashMap模板类,将编号为1001、1002、1003的员工信息插入到HashMap对象中,然后输入一个指定的员工编号,通过员工编号来获取员工的基本信息。员工编号为整型编码,而员工的基本信息定义为类employee。
HashMap对象与员工对象之间的关系及存储结构如图6-1所示。

【Java 代码】
import javA.util.*;
class employee{
employee(String name,String phoneNumber, String address){
this.name = name;
this.phoneNumber = phoneNumber;
this.address = address;
}
String name;
String phoneNumber;
String address;
};
public class javaMain {
public static void main(String[] args) {
Map<Integer, employee> employeeMap = new HashMap<Integer, employee>();
for (Integer employIndex = 1001; employIndex <= 1003; employIndex++){
String tmp = employIndex. (1) ();
employeeMap. (2) (employIndex, (3) ("employee-"+tmp,
"85523927-"+tmp,
"address-"+tmp
)
); //将员工编号和员工信息插入到employeeMap对象中
}
int employeeNo = 0;
System.out.print("请输入员工编号:");
Scanner s= new Scanner(System.in);
employeeNo = s.nextInt(); //从标准输入获得员工编号
employee result = employeeMap. (4) (employeeNo);
if ( (5) == null)
{
System.out.println("该员工编号不存在 !");
return;
}
System.out.println("你所查询的员工编号为:" + employeeNo);
System.out.println("该员工姓名:" + result.name);
System.out.println("该员工电话:" + result.phoneNumber);
System.out.println("该员工地址:" + result.address );
}
}
答案与解析
- 试题难度:较难
- 知识点:
- 试题答案:
(1)toString (2) put (3) new employee (4) get (5)result
- 试题解析:
本题主要考查Java程序设计语言中类库的使用。空缺(1)处需要将employIndex转化为字符串,因此可以使用整型数的toString方法;空缺(2)和(3)处的代码是希望构造出employee对象,并把新构造出的对象及其对应的编号加入到HashMap类的实例employee -Map中,而HashMap的put方法可完成插入编号和员工对象的功能,因此空缺(2)处需要填写put方法,空缺(3)处需要使用new构造一个新的 employee对象;空缺(4)处主要是使用employeeMap对象根据员工号码查找员工信息,可使用HashMap中的get方法,该方法查询到员工信息后将放入result引用中,若没有查到,result将为空。