201311评测上午真题
第 1 题
在程序执行过程中,Cache与主存的地址映像由( )。
- (A) 硬件自动完成
- (B) 程序员调度
- (C) 操作系统管理
- (D) 程序员与操作系统协同完成
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>Cache
- 试题答案:[['A']]
- 试题解析:高速缓存(Cache)的出现主要有两个因素:首先是由于CPU的速度和性能提高很快而主存速度较低而且价格高,其次就是程序执行的局部性特点。因此,才将速度比较快而容量有限的静态存储芯片构成Cache,以尽可能发挥CPU的高速度。因此,必须用硬件来实现Cache的全部功能。
第 2 题
指令寄存器的位数取决于( )。
- (A) 存储器的容量
- (B) 指令字长
- (C) 数据总线的宽度
- (D) 地址总线的宽度
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>其它
- 试题答案:[['B']]
- 试题解析:存储容量是指存储器可以容纳的二进制信息量,用存储器中存储地址寄存器MAR的编址数与存储字位数的乘积表示。
指令寄存器(IR)用来保存当前正在执行的一条指令。当执行一条指令时,先把它从内存取到缓冲寄存器中,然后再传送至指令寄存器。所以跟指令的长度有关。
数据总线负责计算机中数据在各组成部分之间的传送,数据总线宽度是指在芯片内部数据传送的宽度,而数据总线宽度则决定了CPU与二级缓存、内存以及输入/输出设备之间一次数据传输的信息量
地址总线宽度决定了CPU可以访问的物理地址空间,简单地说就是CPU到底能够使用多大容量的内存。
第 3 题
计算机存储数据采用的是双符号位(00表示正号、11表示负号),两个符号相同的数相加时,如果运算结果的两个符号位经( )运算得1,则可断定这两个数相加的结果产生了溢出。
- (A) 逻辑与
- (B) 逻辑或
- (C) 逻辑同或
- (D) 逻辑异或
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>数据的表示
- 试题答案:[[D]]
- 试题解析:当两个同符号的数相加(或者是相异符号数相减)时,运算结果有可能产生溢出。常用的溢出检测机制主要有进位判决法和双符号位判决法。计算机运算溢出检测机制,采用双符号位,00表示正号,11表示负号。如果进位将会导致符号位不一致,从而检测出溢出。结果的符号位为01时,称为上溢,为10时,称为下溢。我们可以认为当符号位为11或00时运算结果不溢出。
如:设X?=?+?1000001,Y?=?+?1000011,采用双符号位表示X=00 1000001,Y=00 1000011,[X?+?Y]补=01 0000100,实际上,运算结果产生了正溢出
由此可知运算结果的两个符号位经异或运算得1,则可断定这两个数相加的结果产生了溢出。
第 4 题
某指令流水线由4段组成,各段所需要的时间如下图所示。连续输入8条指令时的吞吐率(单位时间内流水线所完成的任务数或输出的结果数)为 ( )。

- (A) 8/56Δt
- (B) 8/32Δt
- (C) 8/28Δt
- (D) 8/24Δt
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>流水线技术
- 试题答案:[[C]]
- 试题解析:线水线周期为执行时间最长的一段,所以本题流水线的周期为3Δt
流水线的计算公式为:单条指令所需时间+(n-1)(流水线周期);本题为8条指令即n=8;因此执行完8条指令所需的时间为(1+2+3+1)Δt +(8-1)3Δt =28Δt
流水线的吞吐率(Though Put rate,TP)是指在单位时间内流水线所完成的任务数量或输出的结果数量。计算流水线吞吐率的最基本的公式为:TP=n/Tk
所以本题的正确答案为:8/28Δt
第 5 题
( )不是RISC的特点。
- (A) 指令种类丰富
- (B) 高效的流水线操作
- (C) 寻址方式较少
- (D) 硬布线控制
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>CISC与RISC
- 试题答案:[[A]]
- 试题解析:RISC与CISC是常见的两种指令系统。
RISC的特点是:指令数量少,使用频率接近,定长格式,大部分为单周期指令,操作寄存器,只有Load/Store操作内存;寻址方式少;并增加了通用寄存器;硬布线逻辑控制为主;适合采用流水线。
CISC的特点是:指令数量多,使用频率差别大,可变长格式;寻址方式多;常常采用微程序控制技术(微码)。
第 6 题
程序运行过程中常使用参数在函数(过程)间传递信息,引用调用传递的是实参的( )。
- (A) 地址
- (B) 类型
- (C) 名称
- (D) 值
答案与解析
- 试题难度:容易
- 知识点:程序设计语言>传值与传址
- 试题答案:[['A']]
- 试题解析:传值调用:在按值调用时,过程的形式参数取得的是实际参数的值。在这种情况下,形式参数实际上是过程中的局部量,其值的改变不会导致调用点所传送的实际参数的值发生改变,也就是数据的传送是单向的。
引用调用:在按引用调用时,过程的形式参数取得的是实际参数所在的单元地址。在过程中,对该形式参数的引用相当于对实际参数所在的存储单元的地址引用。任何改变形式参数值的操作会反映在该存储单元中,也就是反映在实际参数中,因此数据的传送是双向的。
第 7 题
( )不是单元测试主要检查的内容。
- (A) 模块接口
- (B) 局部数据结构
- (C) 全局数据结构
- (D) 重要的执行路径
答案与解析
- 试题难度:一般
- 知识点:软件测试基础>软件测试策略(开发阶段)
- 试题答案:[['C']]
- 试题解析:单元测试的内容:模块接口测试;局部数据结构测试;路径测试;错误处理测试;边界测试。
第 8 题
PKI体制中,保证数字证书不被篡改的方法是( )。
- (A) 用CA的私钥对数字证书签名
- (B) 用CA的公钥对数字证书签名
- (C) 用证书主人的私钥对数字证书签名
- (D) 用证书主人的公钥对数字证书签名
答案与解析
- 试题难度:一般
- 知识点:信息安全>信息摘要与数字签名
- 试题答案:[[A]]
- 试题解析:在PKI体制中,识别数字证书的颁发机构以及通过该机构核实证书的有效性,了解证书是否被篡改均通过一种机制——对数字证书做数字签名。数字签名将由CA机构使用自己的私钥进行。
第 9 题
下列算法中,不属于公开密钥加密算法的是( )。
- (A) ECC
- (B) DSA
- (C) RSA
- (D) DES
答案与解析
- 试题难度:一般
- 知识点:信息安全>对称加密与非对称加密
- 试题答案:[[D]]
- 试题解析:常见的对称性加密算法:DES、3DES,RC-5,IDEA
常见的非对称性加密算法:RSA、ECC、DSA
第 10 题
为说明某一问题,在学术论文中需要引用某些资料。以下叙述中,( )是不正确的。
- (A) 既可引用发表的作品,也可引用未发表的作品
- (B) 只能限于介绍、评论作品
- (C) 只要不构成自己作品的主要部分,可适当引用资料
- (D) 不必征得原作者的同意,不需要向他支付报酬
答案与解析
- 试题难度:一般
- 知识点:法律法规与标准化>侵权判断
- 试题答案:[['A']]
- 试题解析:
引用他人作品进行创作,是公民在创作中常用的手法。法律允许公民为了说明自己的观点,评论某部作品等目的,适当引用他人已经发表的作品。但引用要求客观准确,不能任意篡改和歪曲他人作品的原意。
对于引用他人已发表的作品,《著作权法实施条例》第二十七条规定,必须具备下列条件;
1)引用的目的仅限于介绍、评论某一作品或者说明某一问题。
2)所引用部分不能构成引用作品的主要部分或者实质部分。这主要是一个引用适量的问题,例如某人写了部法学专著,为使内容更充实、有趣、具有吸引力,该作者将一部案例专著中的案例引用于作品文中,作品完成以后计算为80万字,其中案例专著中案例就占了50万字,这样引用他人作品,不仅在量上不符合法律规定,而且其引用的目的也不符合法律的要求。
3)引用作品不得损害被引用作品著作权人的利益。这里主要是指引用作品的风格、意图和表现手法,不能任意歪曲、篡改、割裂原作品,并应按《著作权法》的规定,在作品中指明作者的姓名,作品的名称。不能借引用为名达到剽窃和抄袭他人作品的目的,更不能借引用作品而擅自公开他人未发表的作品,从而侵犯作者的著作发表人身权。
第 11 题
以下作品中,不适用或不受著作权法保护的是 ( )。
- (A) 某教师在课堂上的讲课
- (B) 某作家的作品《红河谷》
- (C) 最高人民法院组织编写的《行政诉讼案例选编》
- (D) 国务院颁布的《计算机软件保护条例》
答案与解析
- 试题难度:一般
- 知识点:法律法规与标准化>知识产权人确定
- 试题答案:[['D']]
- 试题解析:根据《中华人民共和国著作权法》的规定,有三种类型的作品不受法律保护。 第一种是依法禁止出版、传播的作品。 第二种是不适用于《著作权法》的作品。它们包括下列作品:
(1)法律、法规,国家的决议、决定、命令和其他具有立法、行政、司法性质的文件,极其官方正式译文;
(2)时事新闻;
(3)历法、通用数表、通用表格和公式。
国务院颁布的《计算机软件保护条例》属于法律法规,所以不受著作权法保护。
第 12 题
已知文法G: S—A0|B1,A- S1|1, B-*S0|0,其中S是开始符号。从S出发可以推导出( )。
- (A) 所有由0构成的字符串
- (B) 所有由1构成的字符串
- (C) 某些0和1个数相等的字符串
- (D) 所有0和1个数不同的字符串
答案与解析
- 试题难度:一般
- 知识点:程序设计语言>文法
- 试题答案:[['C']]
- 试题解析:对于文法可推导出的字符串分析,考试一般可对文法举例,然后总结规律。
以本题文法为例,可以产生的字符串包括:
(1)10
推导过程:S→A0;A→1。
(2)01
推导过程:S→B1;B→0。
(3)1010
推导过程:S→A0;A→S1:S→A0,A→1。
至此,可以了解到,选项A、B、D的描述都是不正确的。
第 13 题
算术表达式a+(b-c)d的后缀式是( ) (-、+、表示算术的减、加、乘运算, 运算符的优先级和结合性遵循惯例)
- (A) bc-d*a+
- (B) abc-d* +
- (C) ab + c- d*
- (D) abcd-* +
答案与解析
- 试题难度:一般
- 知识点:程序设计语言>后缀表达式
- 试题答案:[[B]]
- 试题解析:后缀表达式:又称逆波兰式
表示方法:以从左到右的顺序先写操作数,后写操作符,如果操作数本身是一个具有操作数据的操作,则对其施用同样的规则。如:(a + b)(a - b)后缀表达式为:a b + a b -
具体转换方法:(仅供参考)
第一步:按照运算符的优先级对所有的运算单位加括号:式子变成:(a+((b-c)d))
第二步:把运算符号移动到对应的括号后面:(a((bc) -d) )+
第三步:去掉括号:abc-d*+
第 14 题
将高级语言程序翻译为机器语言程序的过程中常引入中间代码,好处是( )。
- (A) 有利于进行反编译处理
- (B) 有利于进行与机器无关的优化处理
- (C) 尽早发现语法错误
- (D) 可以简化语法和语义分析
答案与解析
- 试题难度:一般
- 知识点:程序设计语言>编译与解释
- 试题答案:[[B]]
- 试题解析:从原理上讲,源程序在进行了语义分析之后就可以直接生成目标代码,但由于源程序与目标代码的逻辑结构往往差别很大,特别是考虑到具体机器指令系统的特点,要使翻译一次到位很困难。另外,用语法制导方式机械生成的目标代码往往是烦琐和低效的,因此有必要设计一种中间代码,将源程序首先翻译成中间代码形式,以利于进行与机器无关的优化处理。由于中间代码实际上也起着编译器前端和后端分水岭的作用,使用中间代码后也有助于提高编译程序的可移植性。
第 15 题
假设某公司营销系统有营销点关系S (营销点,负责人姓名,联系方式)、商品关系P (商品名,条形码,型号,产地,数量,价格),其中,营销点唯一标识S中的每一个元组。每个营销点可以销售多种商品,每一种商品可以由不同的营销点销售。关系S和P的主键分别为( ), S和P的之间联系类型属于( )。
- (A) 营销点、商品名
- (B) 营销点、条形码
- (C) 负责人姓名、商品名
- (D) 负责人姓名、条形码
- (A) 1:1
- (B) 1: n
- (C) n: 1
- (D) n: m
答案与解析
- 试题难度:容易
- 知识点:数据库系统>ER模型
- 试题答案:[['B'],['D']]
- 试题解析:主码是能唯一标识关系中每一元组,并不含多余属性的属性或属性组。在关系S中营销点唯一标识S中的每一个元组,并且不含有多余的属性,而且其他的属性都不能唯一标识每一元组,所以关系S的主键为 营销点;在关系P中,条形码是唯一能标识一种商品的,而商品名则可能因有不同产地而导致重复,所以关系P中的主键应该为 条形码。
题干中:“每个营销点可以销售多种商品,每一种商品可以由不同的营销点销售”说明关系S和P之间应为多对多的关系。
第 16 题
若有关系R (A, B, C, D, E)和S(B,C, F, G),则R与S自然
连接 运算后的属性列有( )个,与表达式π1,3,6,7(σ3<6(R⋈S))等价的SQL语句如下:
SELECT () FROM ( ) WHERE ( ):
- (A) 5
- (B) 6
- (C) 7
- (D) 9
- (A) A, R.C, F, G
- (B) A, C,S.B, S.F
- (C) A, C, S.B,S.C
- (D) R.A, R.C, S.B, S.C
- (A) R
- (B) S
- (C) RS
- (D) R,S
- (A) R.B = S.B AND R.C = S.C AND R.C < S.B
- (B) R.B = S.B AND R.C = S.C AND R.C < S.F
- (C) R.B = S.B OR R.C = S.C OR R.C < S.B
- (D) R.B = S.B OR R.C = S.C OR R.C < S.F
答案与解析
- 试题难度:一般
- 知识点:数据库系统>关系代数
- 试题答案:[['C'],['A'],['D'],['B']]
- 试题解析:自然连接是一种特殊的等值连接;要求两个关系中进行比较的分量必须是相同的属性组;并且在结果集中将重复属性列去掉;在关R和S中存在B、C两列重复,R和S进行自然连接运算后要去除重复的列,所以结果集中的列应该为7列。
π1,3,6,7(σ3<6(R⋈S))表达式先进行连接运算(条件为R关系中B列的值要等于S关系B的值,并且R关系C列的值要等于S关系中C列的值),进行连接运算后的列应该为:A、R.B、R.C、D、E、F、G ,然后在连接运算的基础上进行选择运算,条件为第三列的值小于第六列的值,接下来在选择运算的基础上选取第1列,第3列,第6列,第7列。
所以第二空应该选A,第三空应选D,第四空应选B。
第 17 题
假设段页式存储管理系统中的地址结构如下图所示,则系统中( )。

- (A) 页的大小为4K,每个段的大小均为4096个页,最多可有256个段
- (B) 页的大小为4K,每个段最大允许有4096个页,最多可有256个段
- (C) 页的大小为8K,每个段的大小均为2048个页,最多可有128个段
- (D) 页的大小为8K,每个段最大允许有2048个页,最多可有128个段
答案与解析
- 试题难度:一般
- 知识点:操作系统>段页式存储
- 试题答案:[['B']]
- 试题解析:本题考查段页式存储管理,从题目给出的段号、页号、页内地址位数情况,可以推算出每一级寻址的寻址空间。
如:已知页内地址是从第0位到第11位,共12个位,所以一个页的大小为:212=4K。
页号是从第12位到第23位,共12个位,所以一个段中最多有212=4096个页。
段号是从第24位到第31位,共8个位,所以最多有28=256个段。
第 18 题
假设系统中有三类互斥资源R1、R2和R3,可用资源数分别为10、5和3。在T0 时刻系统中有P1、P2、P3、P4和P5五个进程,这些进程对资源的最大需求量和已分配 资源数如下表所示,此时系统剩余的可用资源数分别为( )。如果进程按( )序列执行,那么系统状态是安全的。 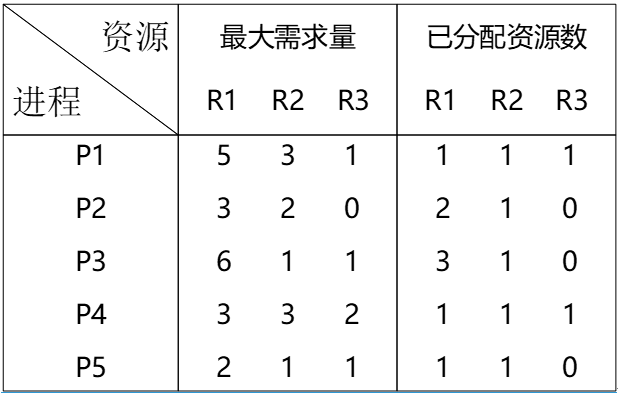
- (A) 1、1 和 0
- (B) 1、1 和 1
- (C) 2、1 和 0
- (D) 2、0 和 1
- (A) P1→P2→P4→P5→P3
- (B) P5→P2→P4→P3→P1
- (C) P4→P2→P1→P5→P3
- (D) P5→P1→P4→P2→P3
答案与解析
- 试题难度:一般
- 知识点:操作系统>银行家算法
- 试题答案:[['D'],['B']]
- 试题解析:首先需要求系统剩余资源,计算方法是将总资源数逐一减去已分配资源数。
R1剩余的可用资源数为:10-1-2-3-1-1=2;
R2剩余的可用资源数为:5-1-1-1-1-1=0;
R3剩余的可用资源数为:3-1-1=1;
接下来分析按什么样的序列执行,系统状态是安全的,所谓系统状态安全是指不产生死锁。在进行该分析时,需要先了解每个进程各类资源还需要多少个,此信息可以通过最大需求量-已分配资源数获得,情况如表所示。
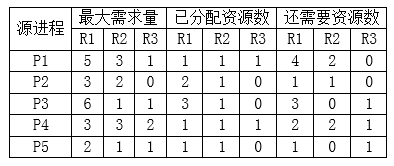
从表可以看出,当前情况下,能运行的唯有P5,除了P5,其他进程所需要的资源系统均不能满足,所以先执行P5。当P5执行完成时,不仅会释放当前分配给他的资源,还会将原来已分配资源数一并释放,所以此时系统剩余资源变为:3,1,1。这个资源数,可以运行P2,但不能运行P1,所以本题选B。
第 19 题
某文件管理系统采用位示图(bitmap)记录磁盘的使用情况。如果系统的字长为32位,磁盘物理块的大小为4MB,物理块依次编号为:0、1、2、位示图字依次编号为:0、1、2、那么16385号物理块的使用情况在位示图中的第( )个字中描述;如果磁盘的容量为1000GB,那么位示图需要( )个字来表示。
- (A) 128
- (B) 256
- (C) 512
- (D) 1024
- (A) 1200
- (B) 3200
- (C) 6400
- (D) 8000
答案与解析
- 试题难度:一般
- 知识点:操作系统>位示图
- 试题答案:[['C'],['D']]
- 试题解析:由于物理块是从0开始编号的,所以16385号物理块是第16386块。16386/32=512.0625,所以16385号物理块的使用情况在位示图中的第513个字中描述。由于字从0开始编号,所以对应的字的编号为512
磁盘的容量为1000GB,物理块的大小为4MB,则磁盘共1000×1024/4个物理块,一个字对应32个物理块,位示图的大小为1000×1024/(32×4) =8000个字。
第 20 题
某单位局域网配置如下图所示,PC2发送到Internet上的报文的源IP地址为 ( )。
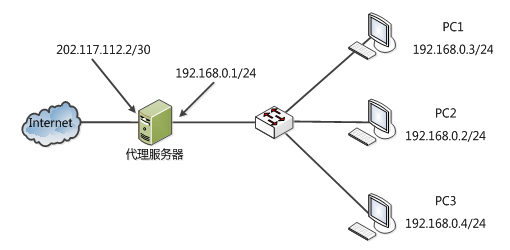
- (A) 192.168.0.2
- (B) 192.168.0.1
- (C) 202.117.112.1
- (D) 202.117.112.2
答案与解析
- 试题难度:一般
- 知识点:计算机网络>IP地址与子网划分
- 试题答案:[[D]]
- 试题解析:代理服务器(Proxy Server)的工作原理是:当客户在浏览器中设置好Proxy Server后(以Web为例),如使用浏览器访问所有WWW站点的请求都不会直接发给目的主机,而是先发给代理服务器,代理服务器接受了客户的请求以后,由代理服务器向目的主机发出请求,并接受目的主机的数据,存于代理服务器的硬盘中,然后再由代理服务器将客户要求的数据发给客户。这时数据包是由代理服务器带客户端向服务器发送的数据包,所以该数据包的源地址应该为代理服务器与Internet连接的IP地址。
如果代理使用NAT技术,内网通过代理服务器与外界通讯时,数据包的源地址将会被代理服务器的外部网卡IP地址替换。
第 21 题
在IPv4向IPv6的过渡期间,如果要使得两个IPv6结点可以通过现有的IPv4网络进行通信,则应该使用( );如果要使得纯IPv6结点可以与纯IPv4结点进行通信,则需要使用( )。
- (A) 堆栈技术
- (B) 双协议栈技术
- (C) 隧道技术
- (D) 翻译技术
- (A) 堆栈技术
- (B) 双协议栈技术
- (C) 隧道技术
- (D) 翻译技术
答案与解析
- 试题难度:一般
- 知识点:计算机网络>IPV6
- 试题答案:[['C'],['D']]
- 试题解析:IPv4和IPv6的过渡期间,主要采用三种基本技术。
(1)双协议栈:主机同时运行IPv4和IPv6两套协议栈,同时支持两套协议
(2)隧道技术:这种机制用来在IPv4网络之上连接IPv6的站点,站点可以是一台主机,也可以是多个主机。隧道技术将IPv6的分组封装到IPv4的分组中,封装后的IPv4分组将通过IPv4的路由体系传输,分组报头的“协议”域设置为41,指示这个分组的负载是一个IPv6的分组,以便在适当的地方恢复出被封装的IPv6分组并传送给目的站点。
(3)NAT-PT :利用转换网关来在IPv4和IPv6网络之间转换IP报头的地址,同时根据协议不同对分组做相应的语义翻译,从而使纯IPv4和纯IPv6站点之间能够透明通信。
第1小题由于两个IPv6的结点通信需要经过IPv4的网络:两个结点之间通信使用的是IPv6的数据报文,但需要经过IPv4的网络,可以使用隧道机制将Ipv6的数据报文封装在一个IPv4的报文中,作为IPv4的数据载荷部分,从而 实现在IPv4网络中传输Ipv6。
第2小题由于两个结点一个是纯Ipv6,另一个是IPv4,由于IPv4和IPv6是两种不同地址长度和报头格式的协议,因此它们之间的通信需要使用翻译技术进行地址转换。
第 22 题
POP3协议采用( )模式进行通信,当客户机需要服务时,客户端软件与POP3 服务器建立( )连接
- (A) Browser/Server
- (B) Client/Server
- (C) Peer to Peer
- (D) Peer to Server
- (A) TCP
- (B) UDP
- (C) PHP
- (D) IP
答案与解析
- 试题难度:一般
- 知识点:计算机网络>TCP/IP协议族
- 试题答案:[['B'],['A']]
- 试题解析:POP3(Post Office Protocol 3)即邮局协议的第3个版本,它是规定个人计算机如何连接到互联网上的邮件服务器接收邮件的协议。它是因特网电子邮件的第一个离线协议标准,POP3协议允许用户从服务器上把邮件存储到本地主机(即自己的计算机)上,同时根据客户端的操作删除或保存在邮件服务器上的邮件,而POP3服务器则是遵循POP3协议的接收邮件服务器,用来接收电子邮件的。POP3协议是TCP/IP协议族中的一员,由RFC 1939 定义。本协议主要用于支持使用客户端远程管理在服务器上的电子邮件。
POP3协议采用的是C/S结构,同时该协议基于传输层TCP协议,所以客户端软件与POP3服务器会建立可靠的连接——TCP连接。
第 23 题
采用插入排序算法对n个整数排序,其基本思想是:在插入第i个整数时,前i-1个整数已经排好序,将第i个整数依次和第i-1, i-2, …个整数进行比较,找到应该插入的位置。现采用插入排序算法对6个整数{5.2.4.6.1.3}进行从小到大排序,则需要进行( )次整数之间的比较。对于该排序算法,输入数据具有( )特点时,对整数进行从小到大排序,所需的比较次数最多。
- (A) 9
- (B) 10
- (C) 12
- (D) 13
- (A) 从小到大
- (B) 从大到小
- (C) 所有元素相同
- (D) 随机分布
答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>排序与查找
- 试题答案:[['C'],['B']]
- 试题解析:一般来说,插入排序都采用in-place在数组上实现。具体算法描述如下:
⒈ 从第一个元素开始,该元素可以认为已经被排序
⒉ 取出下一个元素,在已经排序的元素序列中从后向前扫描
⒊ 如果该元素(已排序)大于新元素,将该元素移到下一位置
⒋ 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
⒌ 将新元素插入到下一位置中
⒍ 重复步骤2~5
对于本题:{5.2.4.6.1.3}
第一趟:第一次比较,5大于2(新元素),元素5向后位移一位,而5之前无数据,即将2插入到1位,2,5
第二趟:第一次比较,5大于4(新元素),元素5向后移一位,再进行第二次比较,2小于4(新元素),即将4插入2之后的一位,即 2,4,5
依次类推…
所以比较的次数为1+2+1+4+4=12
如果目标是把n个元素的序列升序排列,那么采用插入排序存在最好情况和最坏情况。最好情况就是,序列已经是升序排列了,在这种情况下,需要进行的比较操作需(n-1)次即可。最坏情况就是,序列是降序排列,那么此时需要进行的比较共有n(n-1)/2次。插入排序的赋值操作是比较操作的次数加上 (n-1)次。平均来说插入排序算法的时间复杂度为O(n^2)。
第 24 题
软件工程的基本目标是( ) 。
- (A) 消除软件固有的复杂性
- (B) 开发高质量的软件
- (C) 努力发挥开发人员的创造性潜能
- (D) 推动软件理论和技术的发展
答案与解析
- 试题难度:一般
- 知识点:软件工程>其它
- 试题答案:[[B]]
- 试题解析:软件工程是指应用计算机科学、数学及管理科学等原理,以工程化的原则和方法来解决软件问题的工程,其目的是提高软件生产率、提高软件质量、降低软件成本。
第 25 题
( )过程模型明确地考虑了开发中的风险。
- (A) 瀑布
- (B) 快速原型
- (C) V
- (D) 螺旋
答案与解析
- 试题难度:一般
- 知识点:软件工程>开发模型
- 试题答案:[[D]]
- 试题解析:螺旋模型将瀑布模型和演化模型结合起来,加入了两种模型均忽略的风险分析,弥补了这两种模型的不足。螺旋模型将开发过程分为几个螺旋周期,每个螺旋周期大致和瀑布模型相符合。在每个螺旋周期分为如下4个工作步。
1、制定计划。确定软件的目标,选定实施方案,明确项目开发的限制条件
2、风险分析。分析所选的方案,识别风险,消除风险
3、实施工程。实施软件开发,验证阶段性产品
4、用户评估。评价开发工作,提出修正建议,建立下一个周期的开发计划
第 26 题
在开发一个字处理软件时,首先快速发布了一个提供基本文件管理、编辑和文档生成功能的版本,接着发布提供更完善的编辑和文档生成功能的版本,最后发布提供拼写和语法检查功能的版本,这里采用了( )过程模型。
- (A) 瀑布
- (B) 快速原型
- (C) 增量
- (D) 螺旋
答案与解析
- 试题难度:一般
- 知识点:软件工程>开发模型
- 试题答案:[[C]]
- 试题解析:增量模型:允许客户的需求可以逐步提出来;软件产品被增量式的一块块开发,每一个增量均发布一个可操作产品
第 27 题
在各种不同的软件需求中,( )描述了用户使用产品必须要完成的任务,可以用UML建模语言的( )表示。
- (A) 功能需求
- (B) 非功能需求
- (C) 过程约束
- (D) 设计约束
- (A) 用例图
- (B) 类图
- (C) 状态图
- (D) 序列图
答案与解析
- 试题难度:一般
- 知识点:面向对象>UML
- 试题答案:[['A'],['A']]
- 试题解析:功能需求:也称行为需求;规定了开发人员必须在系统中实现的软件功能;通常是通过系统特性的描述表现出来的;特性:指一组逻辑上相关的功能需求,表示系统为用户提供某项功能(服务),使用户的业务目标得以满足。
非功能需求:指系统必须具备的属性和品质;可细分为: 软件质量属性(如:可维护性、可靠性、效率等)和其他的非功能需求。
设计约束:限制条件或补充规约;通常是对系统的一些约束说明;如:必须采用国有自主知识产权的数据库系统,必须运行在UNIX操作系统之下等。
用例图:从用户角度描述系统功能,并指出各功能的操作者。
类图:描述系统中类的静态结构。
状态图:描述类的对象所有可能的状态以及事件发生时状态的转移条件。
序列图:显示对象之间的动态合作关系,强调对象之间消息发生的顺序,同时显示对象之间的交互。
第 28 题
在结构化分析方法中,数据流图描述数据在系统中如何被传送或变换,反映系统必须完成的逻辑功能,用于( )建模。在绘制数据流图时,( )。
- (A) 数据
- (B) 功能
- (C) 结构
- (D) 行为
- (A) 每个加工至少有一个输入数据流,可以没有输出数据流
- (B) 不允许一个加工有多条数据流流向另一个加工
- (C) 不允许一个加工有两个相同的输出数据流流向两个不同的加工
- (D) 必须保持父图与子图平衡
答案与解析
- 试题难度:一般
- 知识点:软件工程>需求分析
- 试题答案:[[B],[D]]
- 试题解析:数据流图(DFD)是结构化分析中的重要方法和工具,是表达系统内数据的流动并通过数据流描述系统功能的一种方法。
DFD从数据传递和加工的角度,利用图形符号通过逐层细化地描述系统内各个部件的功能和数据在它们之间传递的情况,来说明系统所完成的功能。
数据流图设计注意事项:
自外向内,自顶向下,逐层细化,完善求精
保持父图与子图的平衡
保持数据守恒
加工细节隐藏
简化加工间的关系
均匀分解
适当取名,避免空洞的名字
表现的是数据流而不是控制流
每个加工必须既有输入数据流,又有输出数据流
第 29 题
确定采用哪种软件体系结构是在( )阶段进行的。
- (A) 需求分析
- (B) 概要设计
- (C) 详细设计
- (D) 软件实现
答案与解析
- 试题难度:一般
- 知识点:软件工程>软件设计
- 试题答案:[[B]]
- 试题解析:软件体系结构:是对子系统、软件系统组件以及它们之间相互关系的描述。
系统分析阶段的主要任务之一就是确定系统逻辑模型,形成系统分析报告:在调查和分析中得出新系统的功能需求,并给出明确地描述。根据需要与实现可能性,确定新系统的功能,用一系列图表和文字给出新系统功能的逻辑描述,进而形成系统的逻辑模型。
概要设计:主要任务是完成对系统总体结构和基础框架的设计
软件设计:是以系统的软件体系结构为目标的软件开发者所执行的活动,是在功能属性和非功能属性内指定软件系统的组件和组件之间的关系;软件设计可分为概要设计和详细设计两个阶段。
第 30 题
以下关于模块化的叙述中,正确的是( )。
- (A) 每个模块的规模越小越好,这样开发每个模块的成本就可以降低了
- (B) 每个模块的规模越大越好,这样模块之间的通信开销就会降低了
- (C) 应具有高内聚和低耦合的性质
- (D) 仅适用于结构化开发方法
答案与解析
- 试题难度:容易
- 知识点:软件工程>软件设计
- 试题答案:[['C']]
- 试题解析:模块化是将系统划分为若干模块的工作。模块化设计可以使整个系统设计简单,结构清晰,可维护性增强。模块化设计的目标是:每个模块完成一个相对独立的特定功能;模块之间的结构简单。简而言之就是要保证模块之间的独立性,提高每个模块的独立程度。
模块的独立程度可以使用聚合和耦合两个定性标准度量。聚合衡量模块内部各元素结合的紧密程度。耦合度量不同模块间相互依赖的程度。
功能模块设计原则:
提高聚合程度,降低模块之间的耦合程度是模块设计应该遵循的最重要的两个原则。
除此之外,系统模块设计的过程中,还应该考虑其他方面的一些要求,遵循如下原则。
1、系统分解有层次:首先从系统的整体出发,根据系统的目标以功能划分模块。各个模块即互相配合,又各自具有独立功能,共同实现整个系统的目标。然后,对每个子模块再进一步逐层向下分解,直到分解到最小的模块为止。
2、适宜的系统深度和宽度比例:系统深度是指系统结构中的控制层次。宽度表示控制的总分布,即统一层次的模块总数的最大值。系统的深度和宽度之间往往有一个较为适宜的比例。深度过大说明系统划分过细,宽度过大可能会导致系统管理难度的加大。
3、模块大小适中:模块的大小一般使用模块中所包含的语句的数量多少来衡量。有这样一个参考数字即模块的语句行数在50行~100行为最好,最多不超过500行。
4、适度控制模块的扇入扇出:模块的扇入指模块直接上级模块的个数,模块的直属下级模块个数即为模块的扇出。模块的扇入数一般来说越大越好,说明该模块的通用性较强。对于扇出而言,过大可能导致系统控制和协调比较困难,过小则可能说明该模块本身规模过大。经验证明,扇出的个数最好是3或4,一般不要超过7。
5、较小的数据冗余:如果模块分解不当,会造成大量的数据冗余,这可能引起相关数据分布在不同的模块中,大量原始数据需要调用,大量的中间结果需要保存和传递,以及大量计算工作将要重复进行的情况,可能会降低系统的工作效率。
第 31 题
当一个模块直接使用另一个模块的内部数据,或者通过非正常入口转入另一个模块内部,这种模块之间的耦合为( ) 。
- (A) 数据耦合
- (B) 标记耦合
- (C) 公共耦合
- (D) 内容耦合
答案与解析
- 试题难度:一般
- 知识点:软件工程>软件设计
- 试题答案:[['D']]
- 试题解析:非直接耦合:两个模块之间没有直接关系,它们的联系完全是通过主模块的控制和调用来实现的。
数据耦合:两个模块彼此间通过数据参数交换信息。
标记耦合:一组模块通过参数表传递记录信息,这个记录是某一个数据结构的子结构,而不是简单变量。
控制耦合:两个模块彼此间传递的信息中有控制信息。
外部耦合:一组模块都访问同一全局简单变量而不是同一全局数据结构,而且不是通过参数表传递该全局变量的信息。
公共耦合:两个模块之间通过一个公共的数据区域传递信息。
内容耦合:一个模块需要涉及到另一个模块的内部信息。
第 32 题
在面向对象技术中,( )是一组具有相同结构、相同服务、共同关系和共同语义的( )集合,其定义包括名称、属性和操作。
- (A) 类
- (B) 对象
- (C) 实例
- (D) 属性
- (A) 类
- (B) 对象
- (C) 实例
- (D) 属性
答案与解析
- 试题难度:一般
- 知识点:面向对象>UML
- 试题答案:[['A'],['B']]
- 试题解析:对象:对象是基本的运行时的实体,它既包括数据(属性),也包括作用于数据的操作(行为)。所以,一个对象把属性和行为封装为一个整体。一个对象通常可由对象名、属性和操作三部分组成。
类:一个类定义了一组大体上相似的对象。一个类所包含的方法和数据描述一组对象的共同行为和属性,把一组对象的共同特征加以抽象并存储在一个类中的能力,是面向对象技术最重要的一点。是否建立了一个丰富的类库,是衡量一个面向对象程序设计语言成熟与否的重要标志。
第 33 题
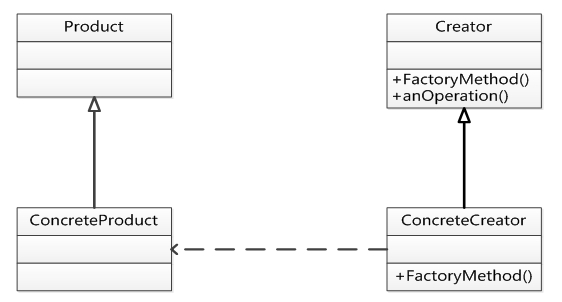
下图中,类 Product 和 ConcreteProduct 的关系是( ) 类ConcreteCreator 和ConceteProduct 的关系是( )
- (A) 继承
- (B) 关联
- (C) 组合
- (D) 依赖
- (A) 继承
- (B) 关联
- (C) 组合
- (D) 依赖
答案与解析
- 试题难度:一般
- 知识点:面向对象>UML
- 试题答案:[['A'],['D']]
- 试题解析:继承:是父类和子类之间共享数据和方法的机制。这是类之间的一种关系,在定义和实现一个类的时候,可以在一个已经存在的类的基础上来进行,把这个已经存在的类所定义的内容作为自己的内容,并加入若干新的内容。
链:表示实例对象间的物理或概念上的连接。
关联描述具有公共结构和公共语义的一组链。实际上链是关联的一个实例。聚集是一种特殊的关联,它描述了整体和部分之间的结构关系。组合也是关联关系的一种特例,他体现的是一种contains-a的关系,这种关系比聚合更强,也称为强聚合;他同样体现整体与部分间的关系,但此时整体与部分是不可分的,整体的生命周期结束也就意味着部分的生命周期结束;比如你和你的大脑;表现在代码层面,和关联关系是一致的,只能从语义级别来区分
泛化是一个类与它的一个或多个细化种类之间的关系,即一般与特殊的关系。被细化的类称为父类,每个细化的种类称为子类,子类可以继承父类的性质。
实现是类元之间的语义关系,其中一个类元指定了由另一个类元保证执行的锲约;在两种地方要遇到实现关系:一种是在接口和实现它们的类或构件之间;另一种是在用例和实现它们的写作之间
依赖是两个事物之间的语义关系,其中一个事物(独立事物)发生变化会影响另一个事物(依赖事物)的语义。
第 34 题
以下关于建立良好的程序设计风格的叙述中,不正确的是( )。
- (A) 程序应简单、清晰、可读性好
- (B) 变量的命名要符合语法
- (C) 充分考虑程序的执行效率
- (D) 程序的注释可有可无
答案与解析
- 试题难度:容易
- 知识点:软件工程>软件设计
- 试题答案:[['D']]
- 试题解析:编码的原则:
总的要求:程序简单、清晰、可读性好。程序设计风格:
(1)标识符的命名
(2)程序中的注释
(3)程序的布局格式
(4)数据说明
(5)程序语句的结构
(6)输入和输出
(7)程序的运行效率
第 35 题
由于硬件配置的变化,如机型、终端或打印机等导致软件系统需要进行修改维护,这类维护属于( )。
- (A) 改正性
- (B) 适应性
- (C) 完善性
- (D) 预防性
答案与解析
- 试题难度:容易
- 知识点:软件工程>软件维护类型
- 试题答案:[['B']]
- 试题解析:本考题考查的知识点为适应性维护基础知识。
改正性维护:是指在使用过程中发现了隐蔽的错误后,为了诊断和改正这些隐蔽错误而修改软件的活动。
适应性维护:是指为了适用变化了的环境而修改软件的活动。
完善性维护:是指为了扩充或完善原有软件的功能或性能而修改软件的活动。
预防性维护:是指为了提高软件的可维护性和可靠性、为未来的进一步改进打下 基础而修改软件的活动。
本题是由于环境变化了而需要适用变化而进行的维护,应该输入适应性维护。
第 36 题
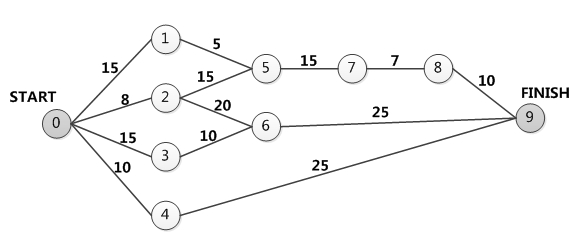
下图是一个软件项目的活动图,其中顶点表示项目里程碑,连接顶点的边表示包含的活动,则里程碑( )没有按时完成会影响整个项目的进度。若活动0+2完成后,停止3天才开始活动2+6,则完成整个项目的最少时间是( )天。
- (A) 1
- (B) 2
- (C) 3
- (D) 4
- (A) 53
- (B) 55
- (C) 56
- (D) 57
答案与解析
- 试题难度:容易
- 知识点:项目管理>Gant图与Pert图
- 试题答案:[['B'],['C']]
- 试题解析:从开始顶点到结束顶点的最长路径为关健路径(临界路径),关键路径上的活动为关键活动。
0→1→5→7→8→9:15+5+15+7+10=52
0→2→5→7→8→9:8+15+15+7+10=55
0→2→6→9:8+20+25=53
0→3→6→9:15+10+25=50
0→4→9:10+25=35
因此0→2→5→7→8→9为关键路径。因此如果该路径上的一个里程碑没有完成,就会影响整个项目进度,结合选项,只有选项B的2在关键路径上。
活动0+2完成后,停止3天才开始活动2+6,则会影响路径0→2→6→9,该路径的长度为53+3=56 大于原来的关键路径,由于0→3→6→9路径需要等待里程碑6完成,所以该路径也将发生变化即由原来的50变为53天,仍然要小于0→2→6→9的56天,而其他路径则不受影响,所以关键路径变为0→2→6→9共计56天。
第 37 题
某软件系统无需在线容错,也不能采用冗余设计,如果对可靠性要求较高,故障有可能导致严重后果,一般采用( )。
- (A) 恢复块设计
- (B) N版本程序设计
- (C) 检错技术
- (D) 降低复杂度设计
答案与解析
- 试题难度:一般
- 知识点:可靠性测试>软件可靠性设计
- 试题答案:[[C]]
- 试题解析:在软件系统中,无需在线容错的地方,或不能采用冗余设计技术的部分,如果对可靠性要求较高,故障有可能导致严重的后果,一般采用检错技术,在软件出现故障后能及时发现并报警,提醒维护人员进行处理。检错技术实现的代价一般低于容错技术和冗余技术,但其有一个明显的缺点,就是不能自动解决故障,出现故障后如果不进行人工干预,将最终导致软件系统不能正常运行。采用检错技术设计要着重考虑:检测对象、检测延时、实现方式、处理方式等要素。
第 38 题
软件可靠性管理把软件可靠性活动贯穿于软件开发的全过程,成为软件工程管理的一部分。确定软件可靠性度量活动属于( )阶段。
- (A) 需求分析
- (B) 概要设计
- (C) 详细设计
- (D) 测试阶段
答案与解析
- 试题难度:一般
- 知识点:可靠性测试>软件可靠性管理(软件生命周期各阶段)
- 试题答案:[[B]]
- 试题解析:软件可靠性管理是软件工程管理的一部分,它以全面提高和保证软件可靠性为目标,以软件可靠性活动为主要对象,是把现代管理理论用于软件生命周期中的可靠性保障活动的一种管理形式。
1、需求分析阶段
确定软件的可靠性目标
分析可能影响可靠性的因素
确定可靠性的验收标准
制定可靠性管理框架
制定可靠性文档编写规范
制定可靠性活动初步计划
确定可靠性数据收集规范
2、概要设计阶段
确定可靠性度量
制定详细的可靠性验收方案
可靠性设计
收集可靠性数据
调整可靠性活动计划
明确后续阶段的可靠性活动的详细计划
编制可靠性文档
3、详细设计阶段
可靠性设计
可靠性预测(确定可靠性度量估计值)
调整可靠性活动计划
收集可靠性数据
明确后续阶段的可靠性活动的详细计划
编制可靠性文档
4、编码阶段
可靠性测试(含单元测试)
排错
调整可靠性活动计划
收集可靠性数据
明确后续阶段的可靠性活动的详细计划
编制可靠性文档
5、测试阶段
可靠性测试(含于集成测试、系统测试)
排错
可靠性建模
可靠性评价
调整可靠性活动计划
收集可靠性活动计划
收集可靠性数据
明确后续阶段的可靠性活动的详细计划
编制可靠性文档
6、实施阶段
可靠性测试(含于验收测试)
排错
收集可靠性数据
调整可靠性模型
可靠性评价
编制可靠性文档
第 39 题
软件测试的对象不包括( )。
- (A) 软件代码
- (B) 软件开发过程
- (C) 文档
- (D) 数据
答案与解析
- 试题难度:容易
- 知识点:软件测试基础>软件测试的对象
- 试题答案:[['B']]
- 试题解析:根据软件定义,软件包括程序、数据和文档,所以软件测试的对象也应该为程序、数据、文档。
第 40 题
以下关于测试计划的叙述中,不正确的是( )。
- (A) 测试计划能使测试工作顺利进行
- (B) 测试计划能使项目参与人员沟通顺畅
- (C) 测试计划无益于提高软件质量
- (D) 测试计划是软件过程规范化的要求
答案与解析
- 试题难度:容易
- 知识点:软件测试基础>其他
- 试题答案:[[C]]
- 试题解析:测试计划详细规定测试的要求,包括测试的目的、内容、方法、步骤以及测试的准则等,以用来验证软件需求规格说明书中的需求是否已由软件设计说明书描述的设计实现。
测试时严格地按照测试计划可以保证进度,使各方面都得以协调进行。
第 41 题
以下关于软件测试原则的叙述中,正确的是( ) 。
- (A) 测试用例只需选用合理的输入数据,不需要选择不合理的输入数据
- (B) 应制定测试计划并严格执行,排除随意性
- (C) 穷举测试是可能的
- (D) 程序员应尽量测试自己的程序
答案与解析
- 试题难度:容易
- 知识点:软件测试基础>软件测试的原则
- 试题答案:[[B]]
- 试题解析:软件测试的原则:
所有的软件测试都应追溯到用户的需求
尽早地和不断地进行软件测试
完全测试是不可能的,测试需要终止:
输入量太大
输出结果太多
路径组合太多
测试无法显示软件潜在的缺陷
充分注意测试中的群集现象
程序员应避免检查自己的程序(除单元测试以外)
尽量避免测试的随意性
第 42 题
以下关于测试时机的叙述中,不正确的是( )。
- (A) 应该尽可能早地进行测试
- (B) 软件中的错误暴露得越迟,则修复和改正错误所花费的代价就越高
- (C) 应该在代码编写完成后开始测试
- (D) 项目需求分析和设计阶段需要测试人员参与
答案与解析
- 试题难度:容易
- 知识点:软件测试基础>软件测试的原则
- 试题答案:[[C]]
- 试题解析:测试应尽早并不断地进行:由于原始问题的复杂性、开发各阶段的多样性,以及参加人员之间的协调等因素,使得在开发各个阶段都有可能出现错误。有的时候表现在程序中的错误,并不一定是由于编码产生的,很有可能是设计阶段,甚至是由需求分析的问题所引起的,而且开发各阶段是连续的,早期出现的小问题到后期而会 扩散,最后需要花费不必要的人力物力来修改错误。尽早进行测试,可以尽快地发现问题,将错误的影响缩小到最小范围。因此,测试应该贯穿在开发的各界的,坚持各阶段的技术评审,这样才能尽早发现错误和纠正错误、消除隐患、提高整个系统的开发质量。
第 43 题
以下不属于软件测试工具的是( )。
- (A) JMeter
- (B) LoadRunner
- (C) JTest
- (D) JBuilder
答案与解析
- 试题难度:容易
- 知识点:软件测试基础>自动化测试(优势、缺点、工具)
- 试题答案:[['D']]
- 试题解析:JMeter:是一个性能测试工具,同loadrunner类似,他功能较多,我们常用的功能是用jmeter模拟多浏览器对网站做压力测试。
LoadRunner:是一种预测系统行为和性能的负载测试工具。通过以模拟上千万用户实施并发负载及实时性能监测的方式来确认和查找问题,LoadRunner能够对整个企业架构进行测试。通过使用 LoadRunner,企业能最大限度地缩短测试时间,优化性能和加速应用系统的发布周期。 LoadRunner是一种适用于各种体系架构的自动负载测试工具,它能预测系统行为并评估系统性能。
JTest:是一个综合的发展广泛的实践证明,以提高开发团队的工作效率和软件质量的自动化测试解决方案。侧重于实践验证的Java代码和应用程序,无缝集成Parasoft的SOAtest以使最终结束今天的复杂的,分布式的应用和交易的功能和负载测试。
JBuilder:是一个可视化JAVA开发工具。它是在Java2平台上开发商业应用程序、数据库、发布程序的优秀工具。
第 44 题
软件的易用性包括( )。
①易理解性 ②易学习性 ③易操作性 ④吸引性 ⑤依从性
- (A) ①②
- (B) ①②③
- (C) ①②③④
- (D) ①②③④⑤
答案与解析
- 试题难度:一般
- 知识点:软件质量与评价>软件质量模型
- 试题答案:[['D']]
- 试题解析:易用性是指在指定条件下使用时,软件产品被理解、学习、使用和吸引用户的能力。包括:易理解性,易学性,易操作性,吸引性,易用性依从性。
易理解性:是指软件产品使用用户能理解软件是否合适以及如何能将软件用于特定的任务和使用环境的能力。
易学性:是指软件产品使用户能学习它的能力。
易操作性:是指软件产品使用户能操作和控制它的能力。
吸引性:是指软件产品吸引用户的能力。
易用性依从性:是指软件产品依附于同易用性相关的标准、约定、风格指南或规定的能力。
第 45 题
黑盒测试不能发现( )。
- (A) 功能错误或者遗漏
- (B) 输入输出错误
- (C) 执行不到的代码
- (D) 初始化和终止错误
答案与解析
- 试题难度:容易
- 知识点:黑盒测试>黑盒测试能发现的问题
- 试题答案:[[C]]
- 试题解析:黑盒测试是以用户的角度,从输入数据与输出数据的对应关系出发进行测试的。
黑盒测试法注重于测试软件的功能需求,主要试图发现下列几类错误:
功能不正确或遗漏
界面错误
数据库访问错误
性能错误
初始化和终止错误等
第 46 题
以下关于边界值测试法的叙述中,不正确的是( )。
- (A) 边界值分析法不仅重视输入域边界,而且也必须考虑输出域边界
- (B) 边界值分析法是对等价类划分方法的补充
- (C) 发生在输入输出边界上的错误比发生在输入输出范围的内部的错误要少
- (D) 测试数据应尽可能选取边界上的值,而不是等价类中的典型值或任意值
答案与解析
- 试题难度:容易
- 知识点:黑盒测试>边界值分析法错误推测法
- 试题答案:[[C]]
- 试题解析:边界值分析是一种补充等价划分的测试用例设计技术,它不是选择等价类的任意元素,而是选择等价类边界的测试用例。实践证明,为检验边界附近的处理专门设计测试用例,常常取得良好的测试效果。边界值分析法不仅重视输入条件边界,而且也适用于输出域测试用例。人们长期的测试工作经验得知:大量的错误是发生在输入或输出范围的边界上的,而不是在输入范围的内部。因此针对各种边界情况设计测试用例,可以查出更多地错误
第 47 题
白盒测试不能发现( )。
- (A) 代码路径中的错误
- (B) 死循环
- (C) 逻辑错误
- (D) 功能错误
答案与解析
- 试题难度:容易
- 知识点:白盒测试>白盒测试概念
- 试题答案:[['D']]
- 试题解析:白盒测试也称结构测试或逻辑驱动测试,它是按照程序内部的结构测试程序,通过测试来检测产品内部动作是否按照设计规格说明书的规定正常进行,检验程序中的每条通路是否都能按预定要求正确工作。这一方法是把测试对象看作一个打开的盒子,测试人员依据程序内部逻辑结构相关信息,设计或选择测试用例,对程序所有逻辑路径进行测试,通过在不同点检查程序的状态,确定实际的状态是否与预期的状态一致。
白盒测试并不对软件功能进行确认和检查。
第 48 题
对于逻辑表达式((a&&b)||c),需要( )个测试用例才能完成条件组合覆盖。
- (A) 2
- (B) 4
- (C) 8
- (D) 16
答案与解析
- 试题难度:一般
- 知识点:白盒测试>逻辑覆盖法
- 试题答案:[['C']]
- 试题解析:多条件覆盖也称为条件组合覆盖,其含义是:设计足够的测试用例,使得每个判断中条件的各种可能组合都至少出现一次。
在本题中,判定语句中有三个逻辑条件,每个逻辑条件有两种可能取值,因此共有23=8种可能组合。
第 49 题
为检测系统在长时间运行下是否存在性能瓶颈,应进行( )。
- (A) 负载测试
- (B) 压力测试
- (C) 疲劳强度测试
- (D) 大数据量测试
答案与解析
- 试题难度:一般
- 知识点:负载压力测试>疲劳强度测试
- 试题答案:[['C']]
- 试题解析:负载测试:是通过逐步增加系统负载,测试系统性能的变化,并最终确定在满足性能指标的情况下,系统所能承受的最大负载量的测试。
压力测试:是通过逐步增加系统负载,测试系统性能的变化,并最终确定在什么负载条件下系统性能处于失效状态,并以此来获得系统能提供最大服务级别的测试。
疲劳强度测试:是采用系统稳定运行情况下能够支持的最大并发用户数,或者日常运行用户数,持续执行一段时间业务,保证达到系统疲劳强度需求的业务量,通过综合分析交易执行指标和资源监控指标,来确定系统处理最大工作量强度性能的过程。
大数据量测试包括独立的数据量测试和综合数据量测试两类。独立的数据量测试指针对某些系统存储、传输、统计、查询等业务进行的大数据量测试。综合数据量测试指和压力性能测试、负载性能测试、疲劳性能测试相结合的综合测试。
本题是检查系统在长时间运行下是否存在瓶颈,应该采用疲劳强度测试。
第 50 题
以下关于负载压力测试的叙述中,不正确的是( )。
- (A) 负载压力测试用于确认系统是否支持性能需求
- (B) 负载压力测试能得到系统可承受的业务量增长
- (C) 负载压力测试是在一定约束条件下测试系统所能承受的最大负载压力
- (D) 负载压力测试不用于发现不同负载场景下的速度变慢、内存泄露等问题
答案与解析
- 试题难度:容易
- 知识点:负载压力测试>基础概念
- 试题答案:[['D']]
- 试题解析:负载压力测试是指在一定约束条件下测试系统所能承受的并发用户量、运行时间、数据量,以确定系统所能承受的最大负载压力。
负载压力测试有助于确认被测系统是否能够支持性能需求,以及预期的负载增长等。负载压力测试不只是关注不同负载场景下的响应时间等指标,它也要通过测试来发现在不同负载场景下会出现的,例如:速度变慢、内存泄漏等问题的原因。因此,应该在开发过程中尽可能早地进行负载压力测试。
第 51 题
测试过程中,正确的测试顺序应该是( )。
①单元测试 ②集成测试 ③系统测试
- (A) ①②③
- (B) ③①②
- (C) ②③①
- (D) ③②①
答案与解析
- 试题难度:容易
- 知识点:软件测试基础>软件开发与软件测试
- 试题答案:[['A']]
- 试题解析:测试过程按4个步骤进行,即单元测试、集成(组装)测试、确认测试和系统测试。开始是单元测试,集中对用源代码实现的每一个程序单元进行测试,检查各个程序模块是否正确地实现了规定的功能。然后,把已测试过的模块组装起来,进行集成测试(组装测试),主要对与设计相关的软件体系结构的构造进行测试。为此,在将一个个实施了单元测试并确保无误的程序模块组装成软件系统的过程中,对正确性和程序结构等方面进行检查。确认测试则是要检查已实现的软件是否满足了需求规格说明中确定了的各种需求,以及软件配置是否完全、正确。最后是系统测试,把已经经过确认的软件纳入实际运行环境中,与其他系统成分组合在一起进行测试
第 52 题
以下属于静态测试方法的是( )。
- (A) 分支覆盖率分析
- (B) 复杂度分析
- (C) 系统压力测试
- (D) 路径覆盖分析
答案与解析
- 试题难度:一般
- 知识点:白盒测试>代码检查法
- 试题答案:[['B']]
- 试题解析:在静态结构分析中,测试者通过使用测试工具分析程序源代码的系统结构、数据结构、数据接口、内部控制逻辑等内部结构,生成函数调用关系图、模块控制流图、内部文件调用关系图、子程序表、宏和函数参数等各类图形图表,可以清晰地标识整个软件系统的组成结构、使其便于阅读与理解,然后可以通过分析这些图表,检查软件有没有存在缺陷或错误。
第 53 题
以下关于集成测试的叙述中,不正确的是( )。
- (A) 在完成软件的概要设计后,即开始制定集成测试计划
- (B) 实施集成测试时需要设计所需驱动和桩
- (C) 桩函数是所测函数的主程序,它接收测试数据并把数据传送给所测试函数
- (D) 常见的集成测试方法包括自顶向下、自底向上、Big-Bang等
答案与解析
- 试题难度:一般
- 知识点:软件测试基础>软件测试策略(开发阶段)
- 试题答案:[[C]]
- 试题解析:驱动模块:相当于所测模块的主程序。它接收测试数据,把这些数据传送给所测模块,最后再输出实测结果。
桩模块:也叫存根模块。用以代替所测模块调用的子模块。桩模块可以做少量的数据操作,不需要把子模块的所有功能都带进来,但不允许什么事情也不做。
第 54 题
对一段信息生成消息摘要是防止信息在网络传输及存储过程中被篡改的基本手 段,( )不属于生成消息摘要的基本算法。
- (A) MD5
- (B) RSA
- (C) SHA-1
- (D) SHA-256
答案与解析
- 试题难度:一般
- 知识点:信息安全>信息摘要与数字签名
- 试题答案:[['B']]
- 试题解析:RSA是一种非对称性加密算法。
第 55 题
软件系统的安全性是信息安全的一个重要组成部分,针对程序和数据的安全性测试与评估是软件安全性测试的重要内容,( )不属于安全性测试与评估的基本内容。
- (A) 用户认证机制
- (B) 加密机制
- (C) 系统能承受的并发用户量
- (D) 数据备份与恢复手段
答案与解析
- 试题难度:容易
- 知识点:安全测试与评估>安全测试与评估的内容
- 试题答案:[['C']]
- 试题解析:负载压力测试是指在一定约束条件下测试系统所能承受的并发用户量、运行时间、数据量,以确定系统所能承受的最大负载压力。
软件安全性是与防止对程序及数据的非授权的故意或意外访问的能力有关的软件属性。其测试和评估包括:用户认证机制;加密机制;安全防护策略;数据备份与恢复手段;防病毒系统等。
第 56 题
模拟攻击试验是一种基本的软件安全性测试方法,以下关于模拟攻击试验的叙述中,正确的是( )。
- (A) 模拟攻击试验必须借助于特定的漏洞扫描器才能完成
- (B) 对安全测试来说,模拟攻击试验是一组特殊的白盒测试案例,必须在充分了解系统安全机制的软件组成基础上,才能进行相应攻击试验的设计与试验
- (C) 缓冲区溢出攻击是一种常见的模拟攻击试验,此类攻击者通常通过截获含有身份鉴别信息或授权请求的有效消息,将该消息进行重演
- (D) 服务拒绝攻击是一种常见的模拟攻击试验,此类攻击者通常通过向服务器发送大量虚假请求,使得服务器功能不能正常执行
答案与解析
- 试题难度:一般
- 知识点:安全测试与评估>安全性测试方法
- 试题答案:[['D']]
- 试题解析:选项A:像伪造电子邮件攻击,口令猜测等都无需特定的漏洞扫描器就能完成。
对于安全测试来说,模拟攻击试验是一组特殊的黑盒测试案例,以模拟攻击来验证软件或信息系统的安全防护能力。
缓冲区溢出:由于在很多的服务程序中使用不进行有效位检查的函数,最终可能导致恶意的用户编写一小段程序来进一步打开安全缺口,然后将该代码放在缓冲区有效载荷的末尾,这样,当发生缓冲区溢出时,返回指针指向恶意代码,执行恶意指令,就可以得到系统的控制权。
服务拒绝:当一个实体不能执行它的正常功能,或它的动作妨碍了别的实体执行它们的正常功能的时候,便发生服务拒绝。
第 57 题
There is nothing in this world constant but inconstancy. —SWIFT Project after project designs a set of algorithms and then plunges into construction of customer-deliverable software on a schedule that demands delivery of the first thing built.
In most projects, the first system built is ( ) usable. It may be too slow, too big, awkward to use, or all three. There is no ( ) but to start again, smarting but smarter, and build a redesigned version in which these problems are solved. The discard and ( ) may be done in one lump, or it may be done piece-by-piece. But all large-system experience shows that it will be done. Where a new system concept or new technology is used, one has to build a system to throw away, for even the best planning is not so omniscient (全知的) as to get it right the first time.
The management question, therefore, is not whether to build a pilot system and throw it away. You will do that. The only question is whether to plan in advance to build a ( ) , or to promise to deliver the throwaway to customers. Seen this way, the answer is much clearer. Delivering that throwaway to customers buys time, but it does so only at the ( ) of agony (极大痛苦)for the user, distraction for the builders while they do the redesign, and a bad reputation for the product that the best redesign will find hard to live down.
Hence plan to throw one away; you will, anyhow.
- (A) almost
- (B) often
- (C) usually
- (D) barely
- (A) alternative
- (B) need
- (C) possibility
- (D) solution
- (A) design
- (B) redesign
- (C) plan
- (D) build
- (A) throwaway
- (B) system
- (C) software
- (D) product
- (A) worth
- (B) value
- (C) cost
- (D) invaluable
答案与解析
- 试题难度:一般
- 知识点:专业英语>专业英语
- 试题答案:[['D'],['A'],['B'],['A'],['C']]
- 试题解析:
世界上没有一成不变的东西— — 斯威夫特项目组设计了一套项目算法,在按照约定交付给客户时发现了该软件存在结构性的问题。
在大多数项目中,建立的第一套系统几乎是不可用的,它可能运行太慢、数据太大、使用不方便等,或者这三者都有。除了重新开始之外我们别无选择,虽然很痛苦但是我们可以更加睿智地构建一个重新设计的版本,解决掉存在的问题。可以一次全部丢弃和重构,也可以分批进行。但是从过往的经验来看,所有的大型系统都必然经历这样的过程。
在使用时系统研究新概念或新技术,就必须建立一个系统并抛弃,因为即使最好的规划也不能保证考虑到方方面面,使第一次便获得让人满意的结果。
因此,管理并不是考虑是否需要建立一项试验系统然后又把它扔了,因为这是必须的。问题仅在于是否要计划提前打造产品,或作出承诺,为客户提供这种必然会被替换的产品。如果这样来考虑,答案是很清楚的。为客户提供这类产品需要花费时间,但对用户来说痛苦的代价是巨大的,会使建设者他们重新设计时分心,坏的声誉也会导致最好的重新设计难以落实。所以将舍弃写进你的计划;无论怎样,你都会的。