HBase简介
一、Hadoop的局限
HBase 是一个构建在 Hadoop 文件系统之上的面向列的数据库管理系统。
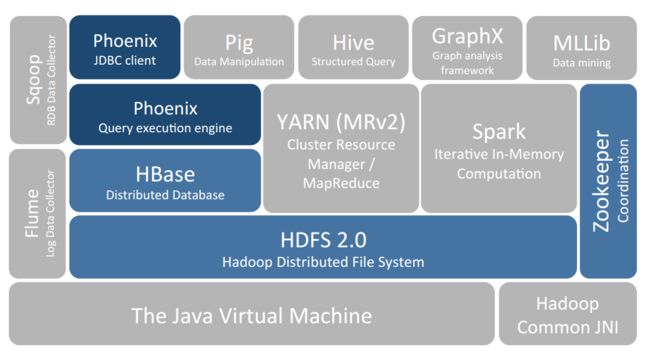
要想明白为什么产生 HBase,就需要先了解一下 Hadoop 存在的限制?Hadoop 可以通过 HDFS 来存储结构化、半结构甚至非结构化的数据,它是传统数据库的补充,是海量数据存储的最佳方法,它针对大文件的存储,批量访问和流式访问都做了优化,同时也通过多副本解决了容灾问题。
但是 Hadoop 的缺陷在于它只能执行批处理,并且只能以顺序方式访问数据,这意味着即使是最简单的工作,也必须搜索整个数据集,无法实现对数据的随机访问。实现数据的随机访问是传统的关系型数据库所擅长的,但它们却不能用于海量数据的存储。在这种情况下,必须有一种新的方案来解决海量数据存储和随机访问的问题,HBase 就是其中之一 (HBase,Cassandra,couchDB,Dynamo 和 MongoDB 都能存储海量数据并支持随机访问)。
注:数据结构分类:
- 结构化数据:即以关系型数据库表形式管理的数据;
- 半结构化数据:非关系模型的,有基本固定结构模式的数据,例如日志文件、XML 文档、JSON 文档、Email 等;
- 非结构化数据:没有固定模式的数据,如 WORD、PDF、PPT、EXL,各种格式的图片、视频等。
二、HBase简介
HBase 是一个构建在 Hadoop 文件系统之上的面向列的数据库管理系统。
HBase 是一种类似于 Google’s Big Table 的数据模型,它是 Hadoop 生态系统的一部分,它将数据存储在 HDFS 上,客户端可以通过 HBase 实现对 HDFS 上数据的随机访问。它具有以下特性:
- 不支持复杂的事务,只支持行级事务,即单行数据的读写都是原子性的;
- 由于是采用 HDFS 作为底层存储,所以和 HDFS 一样,支持结构化、半结构化和非结构化的存储;
- 支持通过增加机器进行横向扩展;
- 支持数据分片;
- 支持 RegionServers 之间的自动故障转移;
- 易于使用的 Java 客户端 API;
- 支持 BlockCache 和布隆过滤器;
- 过滤器支持谓词下推。
三、HBase Table
HBase 是一个面向 列 的数据库管理系统,这里更为确切的而说,HBase 是一个面向 列族 的数据库管理系统。表 schema 仅定义列族,表具有多个列族,每个列族可以包含任意数量的列,列由多个单元格(cell )组成,单元格可以存储多个版本的数据,多个版本数据以时间戳进行区分。
下图为 HBase 中一张表的:
- RowKey 为行的唯一标识,所有行按照 RowKey 的字典序进行排序;
- 该表具有两个列族,分别是 personal 和 office;
- 其中列族 personal 拥有 name、city、phone 三个列,列族 office 拥有 tel、addres 两个列。
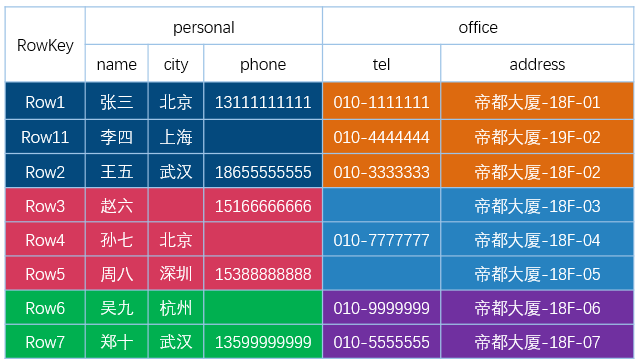
图片引用自 : HBase 是列式存储数据库吗 https://www.iteblog.com/archives/2498.html
Hbase 的表具有以下特点:
容量大:一个表可以有数十亿行,上百万列;
面向列:数据是按照列存储,每一列都单独存放,数据即索引,在查询时可以只访问指定列的数据,有效地降低了系统的 I/O 负担;
稀疏性:空 (null) 列并不占用存储空间,表可以设计的非常稀疏 ;
数据多版本:每个单元中的数据可以有多个版本,按照时间戳排序,新的数据在最上面;
存储类型:所有数据的底层存储格式都是字节数组 (byte[])。
四、Phoenix
Phoenix 是 HBase 的开源 SQL 中间层,它允许你使用标准 JDBC 的方式来操作 HBase 上的数据。在 Phoenix 之前,如果你要访问 HBase,只能调用它的 Java API,但相比于使用一行 SQL 就能实现数据查询,HBase 的 API 还是过于复杂。Phoenix 的理念是 we put sql SQL back in NOSQL,即你可以使用标准的 SQL 就能完成对 HBase 上数据的操作。同时这也意味着你可以通过集成 Spring Data JPA 或 Mybatis 等常用的持久层框架来操作 HBase。
其次 Phoenix 的性能表现也非常优异,Phoenix 查询引擎会将 SQL 查询转换为一个或多个 HBase Scan,通过并行执行来生成标准的 JDBC 结果集。它通过直接使用 HBase API 以及协处理器和自定义过滤器,可以为小型数据查询提供毫秒级的性能,为千万行数据的查询提供秒级的性能。同时 Phoenix 还拥有二级索引等 HBase 不具备的特性,因为以上的优点,所以 Phoenix 成为了 HBase 最优秀的 SQL 中间层。