Spark Streaming与流处理
一、流处理
1.1 静态数据处理
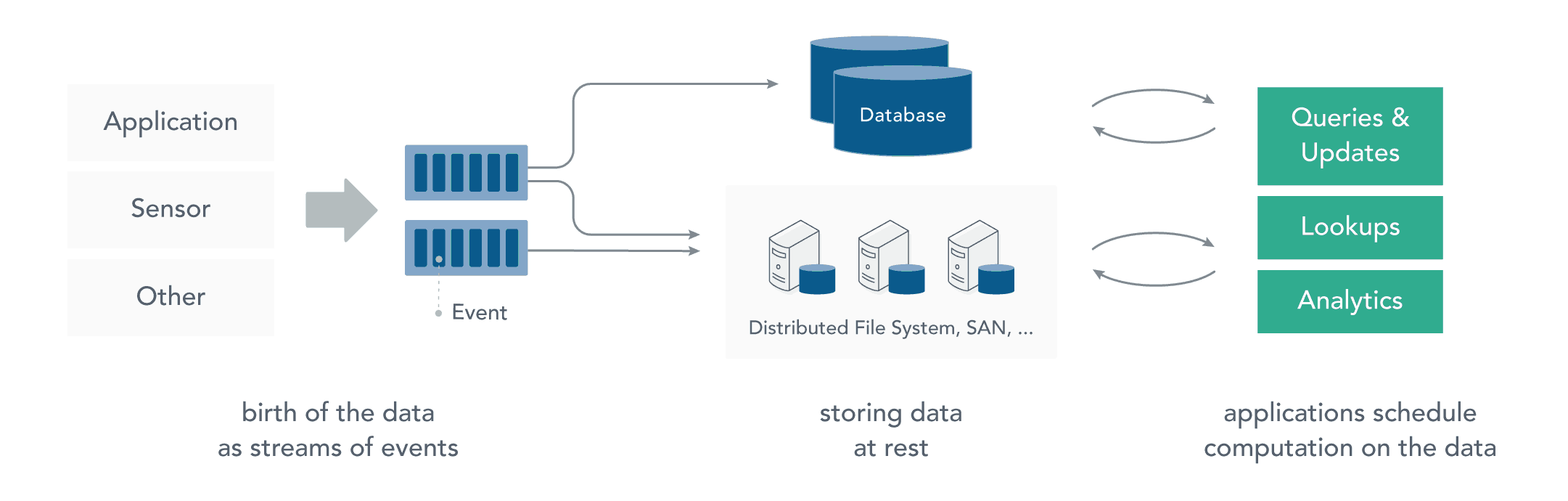
在流处理之前,数据通常存储在数据库,文件系统或其他形式的存储系统中。应用程序根据需要查询数据或计算数据。这就是传统的静态数据处理架构。Hadoop 采用 HDFS 进行数据存储,采用 MapReduce 进行数据查询或分析,这就是典型的静态数据处理架构。
1.2 流处理
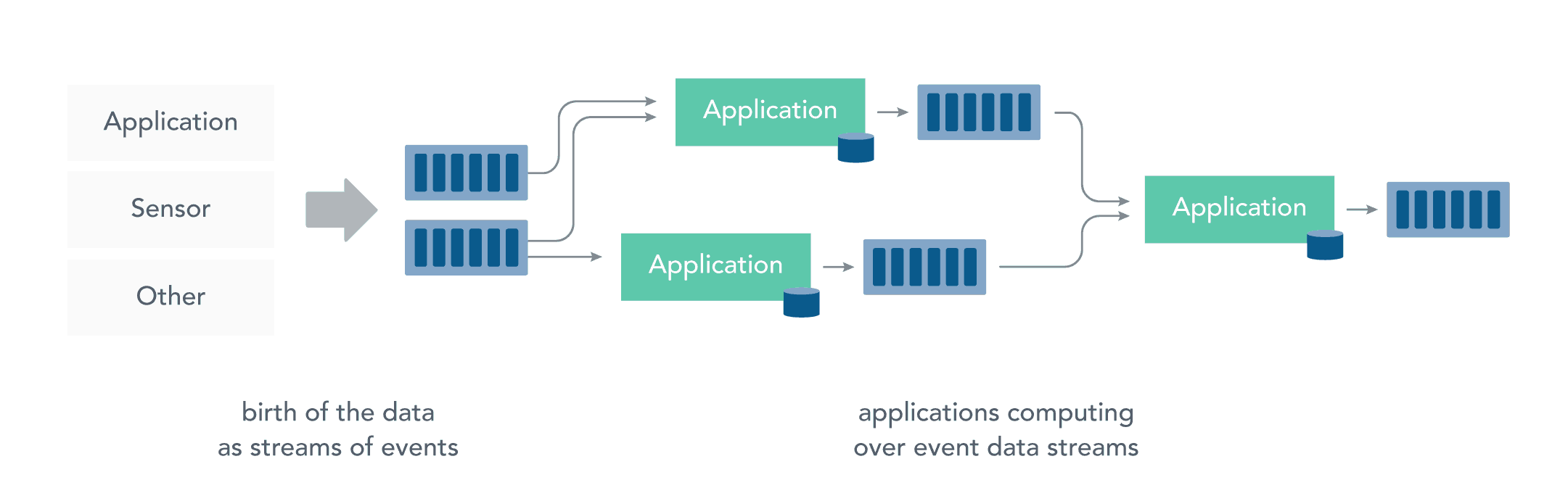
而流处理则是直接对运动中的数据的处理,在接收数据时直接计算数据。
大多数数据都是连续的流:传感器事件,网站上的用户活动,金融交易等等 ,所有这些数据都是随着时间的推移而创建的。
接收和发送数据流并执行应用程序或分析逻辑的系统称为流处理器。流处理器的基本职责是确保数据有效流动,同时具备可扩展性和容错能力,Storm 和 Flink 就是其代表性的实现。
流处理带来了静态数据处理所不具备的众多优点:
- 应用程序立即对数据做出反应:降低了数据的滞后性,使得数据更具有时效性,更能反映对未来的预期;
- 流处理可以处理更大的数据量:直接处理数据流,并且只保留数据中有意义的子集,并将其传送到下一个处理单元,逐级过滤数据,降低需要处理的数据量,从而能够承受更大的数据量;
- 流处理更贴近现实的数据模型:在实际的环境中,一切数据都是持续变化的,要想能够通过过去的数据推断未来的趋势,必须保证数据的不断输入和模型的不断修正,典型的就是金融市场、股票市场,流处理能更好的应对这些数据的连续性的特征和及时性的需求;
- 流处理分散和分离基础设施:流式处理减少了对大型数据库的需求。相反,每个流处理程序通过流处理框架维护了自己的数据和状态,这使得流处理程序更适合微服务架构。
二、Spark Streaming
2.1 简介
Spark Streaming 是 Spark 的一个子模块,用于快速构建可扩展,高吞吐量,高容错的流处理程序。具有以下特点:
- 通过高级 API 构建应用程序,简单易用;
- 支持多种语言,如 Java,Scala 和 Python;
- 良好的容错性,Spark Streaming 支持快速从失败中恢复丢失的操作状态;
- 能够和 Spark 其他模块无缝集成,将流处理与批处理完美结合;
- Spark Streaming 可以从 HDFS,Flume,Kafka,Twitter 和 ZeroMQ 读取数据,也支持自定义数据源。

2.2 DStream
Spark Streaming 提供称为离散流 (DStream) 的高级抽象,用于表示连续的数据流。 DStream 可以从来自 Kafka,Flume 和 Kinesis 等数据源的输入数据流创建,也可以由其他 DStream 转化而来。在内部,DStream 表示为一系列 RDD。

2.3 Spark & Storm & Flink
storm 和 Flink 都是真正意义上的流计算框架,但 Spark Streaming 只是将数据流进行极小粒度的拆分,拆分为多个批处理,使得其能够得到接近于流处理的效果,但其本质上还是批处理(或微批处理)。