深入理解Kafka副本机制
一、Kafka集群
Kafka 使用 Zookeeper 来维护集群成员 (brokers) 的信息。每个 broker 都有一个唯一标识 broker.id,用于标识自己在集群中的身份,可以在配置文件 server.properties 中进行配置,或者由程序自动生成。下面是 Kafka brokers 集群自动创建的过程:
- 每一个 broker 启动的时候,它会在 Zookeeper 的
/brokers/ids路径下创建一个临时节点,并将自己的broker.id写入,从而将自身注册到集群; - 当有多个 broker 时,所有 broker 会竞争性地在 Zookeeper 上创建
/controller节点,由于 Zookeeper 上的节点不会重复,所以必然只会有一个 broker 创建成功,此时该 broker 称为 controller broker。它除了具备其他 broker 的功能外,还负责管理主题分区及其副本的状态。 - 当 broker 出现宕机或者主动退出从而导致其持有的 Zookeeper 会话超时时,会触发注册在 Zookeeper 上的 watcher 事件,此时 Kafka 会进行相应的容错处理;如果宕机的是 controller broker 时,还会触发新的 controller 选举。
二、副本机制
为了保证高可用,kafka 的分区是多副本的,如果一个副本丢失了,那么还可以从其他副本中获取分区数据。但是这要求对应副本的数据必须是完整的,这是 Kafka 数据一致性的基础,所以才需要使用 controller broker 来进行专门的管理。下面将详解介绍 Kafka 的副本机制。
2.1 分区和副本
Kafka 的主题被分为多个分区 ,分区是 Kafka 最基本的存储单位。每个分区可以有多个副本 (可以在创建主题时使用 replication-factor 参数进行指定)。其中一个副本是首领副本 (Leader replica),所有的事件都直接发送给首领副本;其他副本是跟随者副本 (Follower replica),需要通过复制来保持与首领副本数据一致,当首领副本不可用时,其中一个跟随者副本将成为新首领。
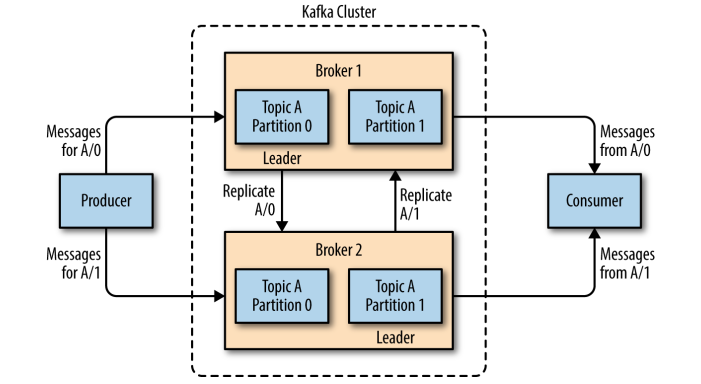
2.2 ISR机制
每个分区都有一个 ISR(in-sync Replica) 列表,用于维护所有同步的、可用的副本。首领副本必然是同步副本,而对于跟随者副本来说,它需要满足以下条件才能被认为是同步副本:
- 与 Zookeeper 之间有一个活跃的会话,即必须定时向 Zookeeper 发送心跳;
- 在规定的时间内从首领副本那里低延迟地获取过消息。
如果副本不满足上面条件的话,就会被从 ISR 列表中移除,直到满足条件才会被再次加入。
这里给出一个主题创建的示例:使用 --replication-factor 指定副本系数为 3,创建成功后使用 --describe 命令可以看到分区 0 的有 0,1,2 三个副本,且三个副本都在 ISR 列表中,其中 1 为首领副本。

2.3 不完全的首领选举
对于副本机制,在 broker 级别有一个可选的配置参数 unclean.leader.election.enable,默认值为 fasle,代表禁止不完全的首领选举。这是针对当首领副本挂掉且 ISR 中没有其他可用副本时,是否允许某个不完全同步的副本成为首领副本,这可能会导致数据丢失或者数据不一致,在某些对数据一致性要求较高的场景 (如金融领域),这可能无法容忍的,所以其默认值为 false,如果你能够允许部分数据不一致的话,可以配置为 true。
2.4 最少同步副本
ISR 机制的另外一个相关参数是 min.insync.replicas , 可以在 broker 或者主题级别进行配置,代表 ISR 列表中至少要有几个可用副本。这里假设设置为 2,那么当可用副本数量小于该值时,就认为整个分区处于不可用状态。此时客户端再向分区写入数据时候就会抛出异常 org.apache.kafka.common.errors.NotEnoughReplicasExceptoin: Messages are rejected since there are fewer in-sync replicas than required。
2.5 发送确认
Kafka 在生产者上有一个可选的参数 ack,该参数指定了必须要有多少个分区副本收到消息,生产者才会认为消息写入成功:
- acks=0 :消息发送出去就认为已经成功了,不会等待任何来自服务器的响应;
- acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应;
- acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
三、数据请求
3.1 元数据请求机制
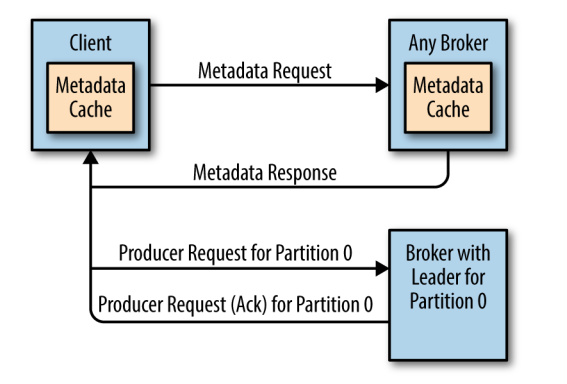
在所有副本中,只有领导副本才能进行消息的读写处理。由于不同分区的领导副本可能在不同的 broker 上,如果某个 broker 收到了一个分区请求,但是该分区的领导副本并不在该 broker 上,那么它就会向客户端返回一个 Not a Leader for Partition 的错误响应。 为了解决这个问题,Kafka 提供了元数据请求机制。
首先集群中的每个 broker 都会缓存所有主题的分区副本信息,客户端会定期发送发送元数据请求,然后将获取的元数据进行缓存。定时刷新元数据的时间间隔可以通过为客户端配置 metadata.max.age.ms 来进行指定。有了元数据信息后,客户端就知道了领导副本所在的 broker,之后直接将读写请求发送给对应的 broker 即可。
如果在定时请求的时间间隔内发生的分区副本的选举,则意味着原来缓存的信息可能已经过时了,此时还有可能会收到 Not a Leader for Partition 的错误响应,这种情况下客户端会再次求发出元数据请求,然后刷新本地缓存,之后再去正确的 broker 上执行对应的操作,过程如下图:
3.2 数据可见性
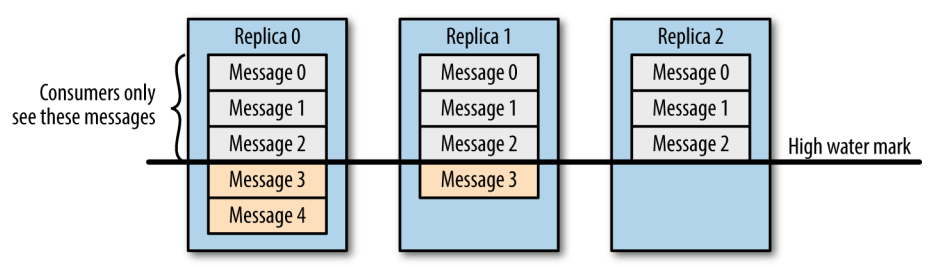
需要注意的是,并不是所有保存在分区首领上的数据都可以被客户端读取到,为了保证数据一致性,只有被所有同步副本 (ISR 中所有副本) 都保存了的数据才能被客户端读取到。
3.3 零拷贝
Kafka 所有数据的写入和读取都是通过零拷贝来实现的。传统拷贝与零拷贝的区别如下:
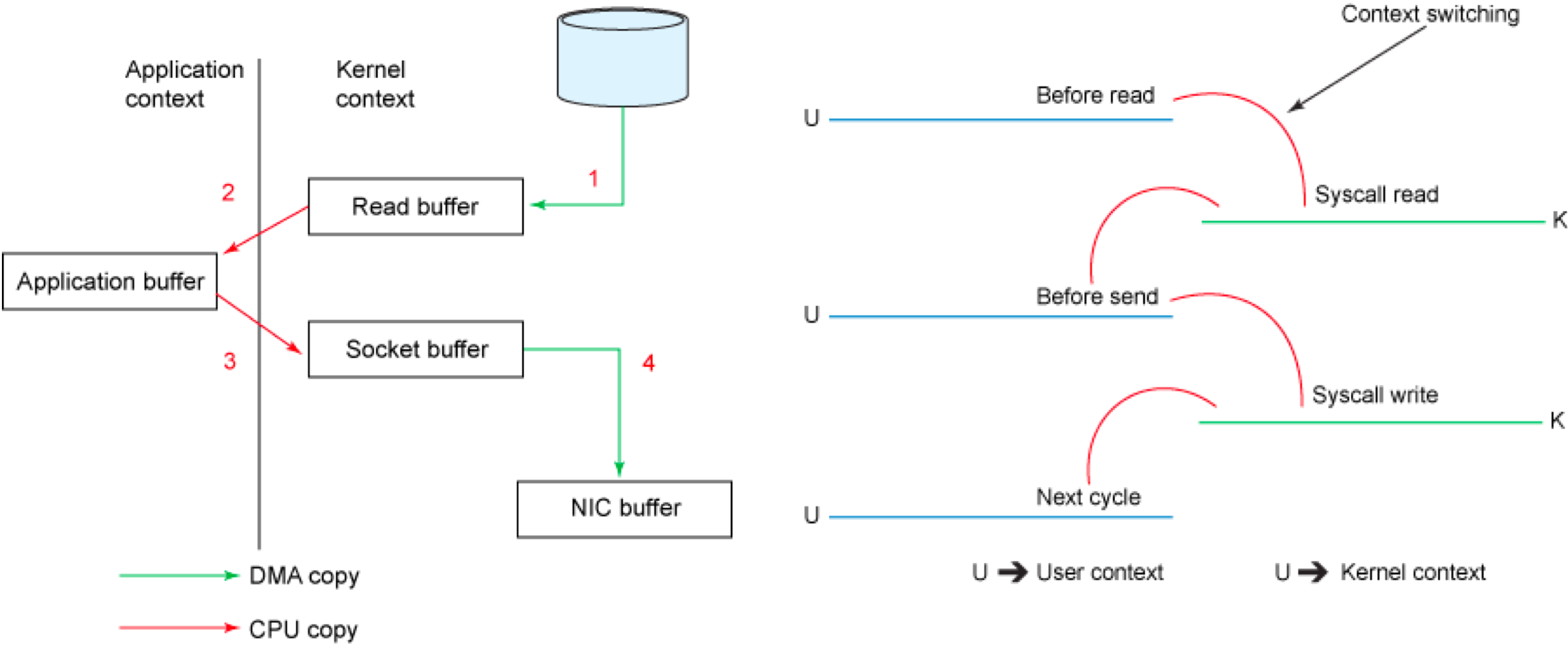
传统模式下的四次拷贝与四次上下文切换
以将磁盘文件通过网络发送为例。传统模式下,一般使用如下伪代码所示的方法先将文件数据读入内存,然后通过 Socket 将内存中的数据发送出去。
buffer = File.read
Socket.send(buffer)
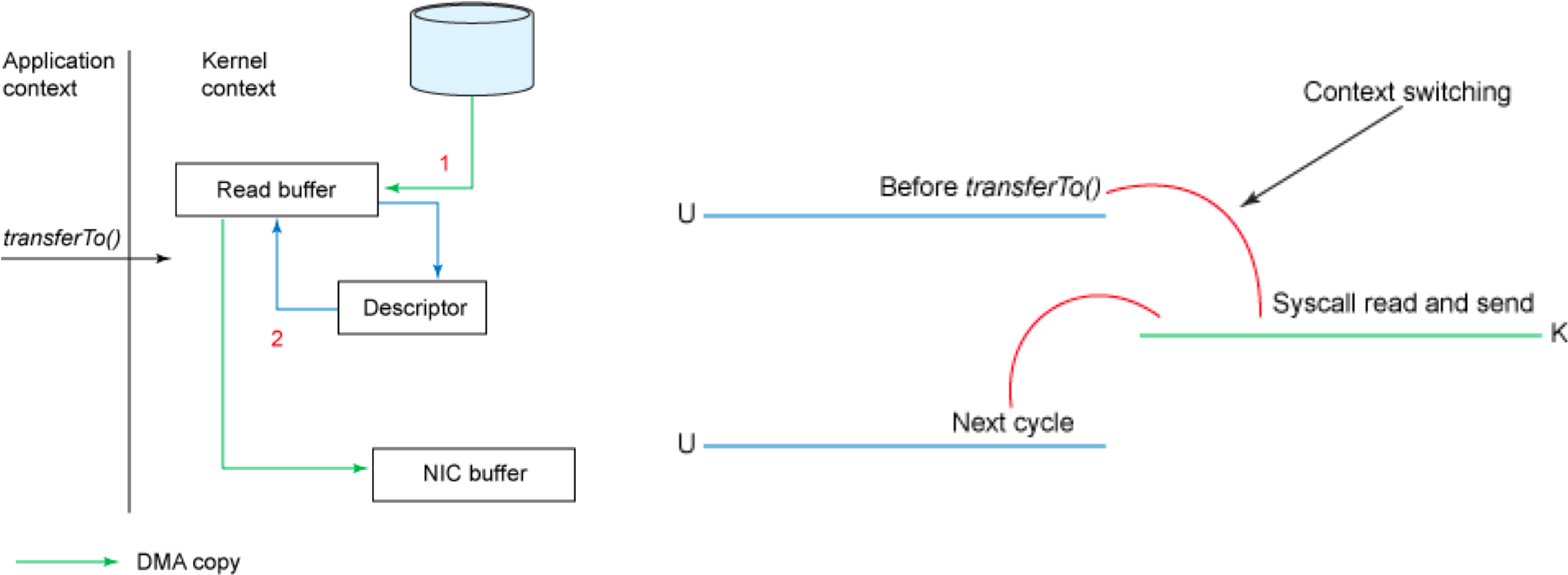
这一过程实际上发生了四次数据拷贝。首先通过系统调用将文件数据读入到内核态 Buffer(DMA 拷贝),然后应用程序将内存态 Buffer 数据读入到用户态 Buffer(CPU 拷贝),接着用户程序通过 Socket 发送数据时将用户态 Buffer 数据拷贝到内核态 Buffer(CPU 拷贝),最后通过 DMA 拷贝将数据拷贝到 NIC Buffer。同时,还伴随着四次上下文切换,如下图所示:
sendfile和transferTo实现零拷贝
Linux 2.4+ 内核通过 sendfile 系统调用,提供了零拷贝。数据通过 DMA 拷贝到内核态 Buffer 后,直接通过 DMA 拷贝到 NIC Buffer,无需 CPU 拷贝。这也是零拷贝这一说法的来源。除了减少数据拷贝外,因为整个读文件到网络发送由一个 sendfile 调用完成,整个过程只有两次上下文切换,因此大大提高了性能。零拷贝过程如下图所示:
从具体实现来看,Kafka 的数据传输通过 TransportLayer 来完成,其子类 PlaintextTransportLayer 的 transferFrom 方法通过调用 Java NIO 中 FileChannel 的 transferTo 方法实现零拷贝,如下所示:
@Override
public long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}
注: transferTo 和 transferFrom 并不保证一定能使用零拷贝。实际上是否能使用零拷贝与操作系统相关,如果操作系统提供 sendfile 这样的零拷贝系统调用,则这两个方法会通过这样的系统调用充分利用零拷贝的优势,否则并不能通过这两个方法本身实现零拷贝。
四、物理存储
4.1 分区分配
在创建主题时,Kafka 会首先决定如何在 broker 间分配分区副本,它遵循以下原则:
- 在所有 broker 上均匀地分配分区副本;
- 确保分区的每个副本分布在不同的 broker 上;
- 如果使用了
broker.rack参数为 broker 指定了机架信息,那么会尽可能的把每个分区的副本分配到不同机架的 broker 上,以避免一个机架不可用而导致整个分区不可用。
基于以上原因,如果你在一个单节点上创建一个 3 副本的主题,通常会抛出下面的异常:
Error while executing topic command : org.apache.kafka.common.errors.InvalidReplicationFactor
Exception: Replication factor: 3 larger than available brokers: 1.
4.2 分区数据保留规则
保留数据是 Kafka 的一个基本特性, 但是 Kafka 不会一直保留数据,也不会等到所有消费者都读取了消息之后才删除消息。相反, Kafka 为每个主题配置了数据保留期限,规定数据被删除之前可以保留多长时间,或者清理数据之前可以保留的数据量大小。分别对应以下四个参数:
log.retention.bytes:删除数据前允许的最大数据量;默认值-1,代表没有限制;log.retention.ms:保存数据文件的毫秒数,如果未设置,则使用log.retention.minutes中的值,默认为 null;log.retention.minutes:保留数据文件的分钟数,如果未设置,则使用log.retention.hours中的值,默认为 null;log.retention.hours:保留数据文件的小时数,默认值为 168,也就是一周。
因为在一个大文件里查找和删除消息是很费时的,也很容易出错,所以 Kafka 把分区分成若干个片段,当前正在写入数据的片段叫作活跃片段。活动片段永远不会被删除。如果按照默认值保留数据一周,而且每天使用一个新片段,那么你就会看到,在每天使用一个新片段的同时会删除一个最老的片段,所以大部分时间该分区会有 7 个片段存在。
4.3 文件格式
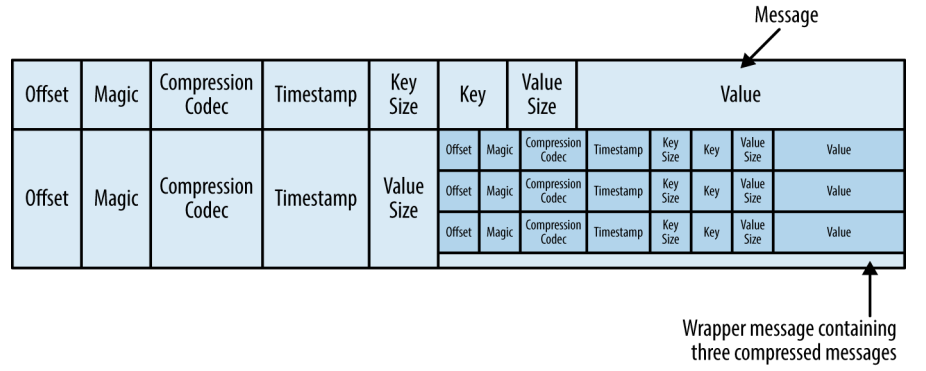
通常保存在磁盘上的数据格式与生产者发送过来消息格式是一样的。 如果生产者发送的是压缩过的消息,那么同一个批次的消息会被压缩在一起,被当作“包装消息”进行发送 (格式如下所示) ,然后保存到磁盘上。之后消费者读取后再自己解压这个包装消息,获取每条消息的具体信息。
参考资料
- Neha Narkhede, Gwen Shapira ,Todd Palino(著) , 薛命灯 (译) . Kafka 权威指南 . 人民邮电出版社 . 2017-12-26
- Kafka 高性能架构之道