Zookeeper Java 客户端 ——Apache Curator
一、基本依赖
Curator 是 Netflix 公司开源的一个 Zookeeper 客户端,目前由 Apache 进行维护。与 Zookeeper 原生客户端相比,Curator 的抽象层次更高,功能也更加丰富,是目前 Zookeeper 使用范围最广的 Java 客户端。本篇文章主要讲解其基本使用,项目采用 Maven 构建,以单元测试的方法进行讲解,相关依赖如下:
<dependencies>
<!--Curator 相关依赖-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.13</version>
</dependency>
<!--单元测试相关依赖-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
完整源码见本仓库: https://github.com/heibaiying/BigData-Notes/tree/master/code/Zookeeper/curator
二、客户端相关操作
2.1 创建客户端实例
这里使用 @Before 在单元测试执行前创建客户端实例,并使用 @After 在单元测试后关闭客户端连接。
public class BasicOperation {
private CuratorFramework client = null;
private static final String zkServerPath = "192.168.0.226:2181";
private static final String nodePath = "/hadoop/yarn";
@Before
public void prepare() {
// 重试策略
RetryPolicy retryPolicy = new RetryNTimes(3, 5000);
client = CuratorFrameworkFactory.builder()
.connectString(zkServerPath)
.sessionTimeoutMs(10000).retryPolicy(retryPolicy)
.namespace("workspace").build(); //指定命名空间后,client 的所有路径操作都会以/workspace 开头
client.start();
}
@After
public void destroy() {
if (client != null) {
client.close();
}
}
}
2.2 重试策略
在连接 Zookeeper 时,Curator 提供了多种重试策略以满足各种需求,所有重试策略均继承自 RetryPolicy 接口,如下图:
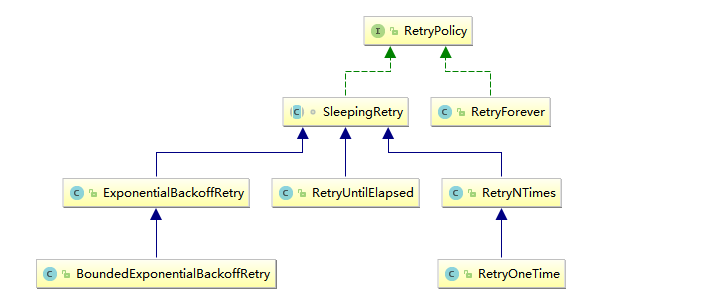
这些重试策略类主要分为以下两类:
- RetryForever :代表一直重试,直到连接成功;
- SleepingRetry : 基于一定间隔时间的重试。这里以其子类
ExponentialBackoffRetry为例说明,其构造器如下:
/**
* @param baseSleepTimeMs 重试之间等待的初始时间
* @param maxRetries 最大重试次数
* @param maxSleepMs 每次重试间隔的最长睡眠时间(毫秒)
*/
ExponentialBackoffRetry(int baseSleepTimeMs, int maxRetries, int maxSleepMs)
2.3 判断服务状态
@Test
public void getStatus() {
CuratorFrameworkState state = client.getState();
System.out.println("服务是否已经启动:" + (state == CuratorFrameworkState.STARTED));
}
三、节点增删改查
3.1 创建节点
@Test
public void createNodes() throws Exception {
byte[] data = "abc".getBytes();
client.create().creatingParentsIfNeeded()
.withMode(CreateMode.PERSISTENT) //节点类型
.withACL(ZooDefs.Ids.OPEN_ACL_UNSAFE)
.forPath(nodePath, data);
}
创建时可以指定节点类型,这里的节点类型和 Zookeeper 原生的一致,全部类型定义在枚举类 CreateMode 中:
public enum CreateMode {
// 永久节点
PERSISTENT (0, false, false),
//永久有序节点
PERSISTENT_SEQUENTIAL (2, false, true),
// 临时节点
EPHEMERAL (1, true, false),
// 临时有序节点
EPHEMERAL_SEQUENTIAL (3, true, true);
....
}
2.2 获取节点信息
@Test
public void getNode() throws Exception {
Stat stat = new Stat();
byte[] data = client.getData().storingStatIn(stat).forPath(nodePath);
System.out.println("节点数据:" + new String(data));
System.out.println("节点信息:" + stat.toString());
}
如上所示,节点信息被封装在 Stat 类中,其主要属性如下:
public class Stat implements Record {
private long czxid;
private long mzxid;
private long ctime;
private long mtime;
private int version;
private int cversion;
private int aversion;
private long ephemeralOwner;
private int dataLength;
private int numChildren;
private long pzxid;
...
}
每个属性的含义如下:
| 状态属性 | 说明 |
|---|---|
| czxid | 数据节点创建时的事务 ID |
| ctime | 数据节点创建时的时间 |
| mzxid | 数据节点最后一次更新时的事务 ID |
| mtime | 数据节点最后一次更新时的时间 |
| pzxid | 数据节点的子节点最后一次被修改时的事务 ID |
| cversion | 子节点的更改次数 |
| version | 节点数据的更改次数 |
| aversion | 节点的 ACL 的更改次数 |
| ephemeralOwner | 如果节点是临时节点,则表示创建该节点的会话的 SessionID;如果节点是持久节点,则该属性值为 0 |
| dataLength | 数据内容的长度 |
| numChildren | 数据节点当前的子节点个数 |
2.3 获取子节点列表
@Test
public void getChildrenNodes() throws Exception {
List<String> childNodes = client.getChildren().forPath("/hadoop");
for (String s : childNodes) {
System.out.println(s);
}
}
2.4 更新节点
更新时可以传入版本号也可以不传入,如果传入则类似于乐观锁机制,只有在版本号正确的时候才会被更新。
@Test
public void updateNode() throws Exception {
byte[] newData = "defg".getBytes();
client.setData().withVersion(0) // 传入版本号,如果版本号错误则拒绝更新操作,并抛出 BadVersion 异常
.forPath(nodePath, newData);
}
2.5 删除节点
@Test
public void deleteNodes() throws Exception {
client.delete()
.guaranteed() // 如果删除失败,那么在会继续执行,直到成功
.deletingChildrenIfNeeded() // 如果有子节点,则递归删除
.withVersion(0) // 传入版本号,如果版本号错误则拒绝删除操作,并抛出 BadVersion 异常
.forPath(nodePath);
}
2.6 判断节点是否存在
@Test
public void existNode() throws Exception {
// 如果节点存在则返回其状态信息如果不存在则为 null
Stat stat = client.checkExists().forPath(nodePath + "aa/bb/cc");
System.out.println("节点是否存在:" + !(stat == null));
}
三、监听事件
3.1 创建一次性监听
和 Zookeeper 原生监听一样,使用 usingWatcher 注册的监听是一次性的,即监听只会触发一次,触发后就销毁。示例如下:
@Test
public void DisposableWatch() throws Exception {
client.getData().usingWatcher(new CuratorWatcher() {
public void process(WatchedEvent event) {
System.out.println("节点" + event.getPath() + "发生了事件:" + event.getType());
}
}).forPath(nodePath);
Thread.sleep(1000 * 1000); //休眠以观察测试效果
}
3.2 创建永久监听
Curator 还提供了创建永久监听的 API,其使用方式如下:
@Test
public void permanentWatch() throws Exception {
// 使用 NodeCache 包装节点,对其注册的监听作用于节点,且是永久性的
NodeCache nodeCache = new NodeCache(client, nodePath);
// 通常设置为 true, 代表创建 nodeCache 时,就去获取对应节点的值并缓存
nodeCache.start(true);
nodeCache.getListenable().addListener(new NodeCacheListener() {
public void nodeChanged() {
ChildData currentData = nodeCache.getCurrentData();
if (currentData != null) {
System.out.println("节点路径:" + currentData.getPath() +
"数据:" + new String(currentData.getData()));
}
}
});
Thread.sleep(1000 * 1000); //休眠以观察测试效果
}
3.3 监听子节点
这里以监听 /hadoop 下所有子节点为例,实现方式如下:
@Test
public void permanentChildrenNodesWatch() throws Exception {
// 第三个参数代表除了节点状态外,是否还缓存节点内容
PathChildrenCache childrenCache = new PathChildrenCache(client, "/hadoop", true);
/*
* StartMode 代表初始化方式:
* NORMAL: 异步初始化
* BUILD_INITIAL_CACHE: 同步初始化
* POST_INITIALIZED_EVENT: 异步并通知,初始化之后会触发 INITIALIZED 事件
*/
childrenCache.start(StartMode.POST_INITIALIZED_EVENT);
List<ChildData> childDataList = childrenCache.getCurrentData();
System.out.println("当前数据节点的子节点列表:");
childDataList.forEach(x -> System.out.println(x.getPath()));
childrenCache.getListenable().addListener(new PathChildrenCacheListener() {
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) {
switch (event.getType()) {
case INITIALIZED:
System.out.println("childrenCache 初始化完成");
break;
case CHILD_ADDED:
// 需要注意的是: 即使是之前已经存在的子节点,也会触发该监听,因为会把该子节点加入 childrenCache 缓存中
System.out.println("增加子节点:" + event.getData().getPath());
break;
case CHILD_REMOVED:
System.out.println("删除子节点:" + event.getData().getPath());
break;
case CHILD_UPDATED:
System.out.println("被修改的子节点的路径:" + event.getData().getPath());
System.out.println("修改后的数据:" + new String(event.getData().getData()));
break;
}
}
});
Thread.sleep(1000 * 1000); //休眠以观察测试效果
}