201105数据库下午真题
第 1 题
【说明】
某医院欲开发病人监控系统。该系统通过各种设备监控病人的生命体征,并在生命体征异常时向医生和护理人员报警。该系统的主要功能如下:
(1)本地监控:定期获取病人的生命体征,如体温、血压、心率等数据。
(2)格式化生命体征:对病人的各项重要生命体征数据进行格式化,然后存入日志文件并检查生命体征。
(3)检查生命体征:将格式化后的生命体征与生命体征范围文件中预设的正常范围进行比较。如果超出了预设范围,系统就发送一条警告信息给医生和护理人员。
(4)维护生命体征范围:医生在必要时(如,新的研究结果出现时)添加或更新生命体征值的正常范围。
(5)提取报告:在医生或护理人员请求病人生命体征报告时,从日志文件中获取病人生命体征生成体征报告,并返回给请求者。
(6)生成病历:根据日志文件中的生命体征,医生对病人的病情进行描述,形成病历存入病历文件。
(7)查询病历:根据医生的病历查询请求,查询病历文件,给医生返回病历报告。
(8)生成治疗意见:根据日志文件中的生命体征和病历,医生给出治疗意见,如处方等,并存入治疗意见文件。
(9)查询治疗意见:医生和护理人员查询治疗意见,据此对病人进行治疗。
现采用结构化方法对病人监控系统进行分析与设计,获得如图1-1所示的顶层数据流图和图1-2所示的0层数据流图。
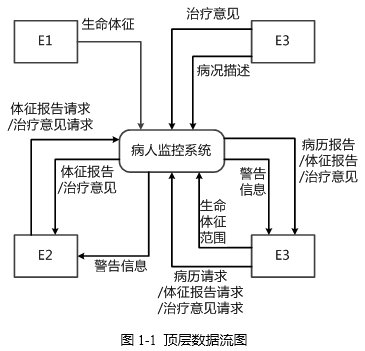

【问题1】(3分)
使用说明中的词语,给出图1-1中的实体E1~E3的名称。
【问题2】(4分)
使用说明中的词语,给出图1-2中的数据存储D1~D4的名称。
【问题3】 (6分)
图1-2中缺失了4条数据流,使用说明、图1-1和图1-2中的术语,给出数据流的名称及其起点和终点。
【问题4】(2分)
说明实体E1和E3之间可否有数据流,并解释其原因。
答案与解析
- 试题难度:较难
- 知识点:软件工程>DFD与数据字典
- 试题答案:
【问题1】(3分,各1分)
E1:病人 E2:护理人员 E3:医生
【问题2】(4分,各1分)
D1:生命体征范围文件 D2:日志文化
D3:病历文件 D4:治疗意见文件
【问题3】(6分)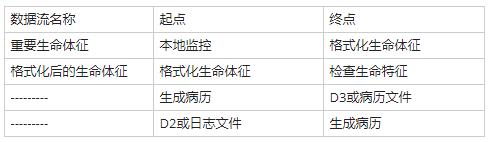
注:上表中各行次序无关,但每行的数据流名称、(….表示不计分)、起点、终点必须相对应
【问题4】(2分)
E1和E3之间不可以有数据流,因为数据的起点和终点必须有一个是加工(处理)。 - 试题解析:
本题考查数据流图(DFD)的应用,是一种比较传统的题目,要求考生细心分析题目中所描述的内容。DFD是一种便于用户理解、分析系统数据流程的图形工具。是系统逻辑模型的重要组成部分。
解答这类问题,有以下两个原则:
(1)紧扣试题的系统说明部分,数据流图与系统说明有着严格的对应关系,系统说明部分的每一句话都能对应到图中,解题时可以一句一句地对照着图来分析。
(2)数据的平衡原则,这一点在解题过程中也是至关重要的。数据平衡原则有两方面的意思:一方面是分层数据流图中父子图之间的数据流平衡原则;另一方面是每张数据流图中输入与输出数据流的平衡原则。
【问题1】
本问题要求我们给出图1-1中的实体E1~E3的名称。这个需要我们从题目中的描述和该图来获得。题目中有信息描述:定期获取病人的生命体征,如体温、血压、心率等数据,我们结合顶层数据流图可知,E1为实体病人;另外,根据题目描述“将格式化后的生命体征与生命体征范围文件中预设的正常范围进行比较。如果超出了预设范围,系统就发送一条警告信息给医生和护理人员”,我们可以知道E2和E3它们分别可能是护理人员或医生,再结合描述“医生在必要时添加或更新生命体征值的正常范围”和顶层数据流图可知,E3是医生,那么E2就是护理人员。
【问题2】
本问题考查数据存储的确定。根据题目的描述“对病人的各项重要生命体征数据进行格式化,然后存入日志文件并检查生命体征”,结合0层数据流图我们可知D2为日志文件;根据题目描述“根据日志文件中的生命体征,医生对病人的病情进行描述,形成病历存入病历文件”,再结合0层数据流图我们可知D3为病历文件,并且缺少生成病历至病历文件的数据流和日志文件至生成病历的数据流;根据题目描述“根据日志文件中的生命体征和病历,医生给出治疗意见,如处方等,并存入治疗意见文件”,再结合0层数据流图我们可知D4为治疗意见文件。在确定了上面三个文件后,题目中还剩下生命体征范围文件,很显然,D1就是生命体征范围文件。
【问题3】
本题主要考查数据流的查找,即要求我们找出0层数据流图中缺失的4条数据流。在问题2中,我们已经找到了生成病历至病历文件的数据流和日志文件至生成病历的数据流。
另外,根据数据流图的原则,即每个加工必须有输入流和输出流,我们可以找到加工本地监控只有输入数据流,而没有输出数据流,那么它肯定缺少一个输出数据流,而根据题目描述“对病人的各项重要生命体征数据进行格式化”我们可知,0层数据流图中应该缺少从本地监控至格式化生命体征的数据流重要生命体征,这样就是加工格式化生命体征也有了输入数据流。
最后一条缺失的数据流是从格式化生命体征至检查生命体征的数据流,这个可以根据题目描述“对病人的各项重要生命体征数据进行格式化,然后存入日志文件并检查生命体征”找出,在这个描述中明显的说到要将生命体征数据格式化后进行检查。这个数据流名称就为格式化后的生命体征。
【问题4】
根据上面的分析,我们已经知道E1和E3分别为病人和医生。显然它们都是实体,因此它们之间不能有数据流,因为数据流的起点和终点中必须有一个是加工。
第 2 题
【说明】
某法院要开发一个诉讼案件信息处理系统,该信息系统的部分关系模式如下:
职工(职工编号,姓名,岗位)
律师(律师编号,姓名)
被告(被告编号,姓名,地址)
案件(案件编号,案件类型,案件描述,被告,律师,主审法官,立案日期,状态,
结案日期,结案摘要)
审理(审理编号,案件编号,审理日期,摘要)
有关关系模式的属性及相关说明如下:
(1)职工关系模式的岗位有“法官”、“书记员”和“其他”。
(2)诉讼立案后,即在案件关系中插入一条相应记录。案件关系模式的状态有“待处理”、“审理中”、“结案”和“撤销”,一个案件开始立案时其案件状态为“待处理”。
(3)案件关系模式的案件类型有“偷窃”、“纵火”等。
(4) 一个案件自立案到结案的整个过程由一位法官和一位律师负责,一个案件通常经过一次到多次审理。
【问题1】
假设案件编号唯一标识一个案件,且立案日期小于等于结案日期。请将如下创建案件关系的SQL语句的空缺部分补充完整。
CREATE TABLE案件(
案件编号CHAR(6) (a) ,
案件类型VARCHAR(10),
案件描述VARCHAR (200),
立案日期DATE
被告VARCHAR (6) REFERENCES被告(被告编号),
律师VARCHAR (6) REFERENCES律师(律师编号),
主审法官VARCHAR (6) (b) ,
状态VARCHAR (6) (c) DEFAULT‘待处理’,
结案日期DATE,
结案摘要VARCHAR (200),
(d) );
【问题2】
请完成下列查询的SQL语句。
(1)查询当前待处理的诉讼案件,显示案件的案件编号、立案日期、被告姓名、被告地址、案件描述、律师姓名和主审法官姓名。
SELECT案件编号,立案日期,被告.姓名AS被告姓名,地址AS被告地址,案件描述,律师.姓名AS律师姓名, (e)
FROM (f)
WHERE案件.被告=被告.被告编号AND案件.律师=律师.律师编号AND
(g) ;
(2)查询2009年立案的各类案件数,并按案件数降序排序。(日期格式举例:2009年1月1日表示为01-JAN-2009,2009年12月31日表示为31-DEC-2009)
SELECT类型,count(*) AS案件数
FROM案件
WHERE (h)
GROUP BY案件类型
(i) ;
(3)查询立案次数超过5次的被告姓名和地址。
SELECT姓名,地址,count(*)
FROM案件,被告
WHERE (j)
GROUP BY (k)
(l) ;
【问题3】
当插入一个审理记录时,检查案件的状态,若状态为“未处理”,则将其修改为“审理中”。下面是用触发器实现该需求的SQL语句,请将空缺部分补充完整。
CREATE TRIGGER 审理TRIGGER AFTER (m) ON审理
REFERENCING new row AS nrow
FOR EACH row
WHEN‘未处理’=(SELECT状态
FROM案件
WHERE案件编号- nrow.案件编号)
BEGIN
UPDATE案件 (n)
WHERE (o) ;
END
答案与解析
- 试题难度:较难
- 知识点:SQL语言>SELECT语句
- 试题答案:
【问题1】
(a) PRIMARY KEY或NOT NULL UNIQUE
(b) REFERENCES职工(职工编号)
(c) CHECK VALUES IN(‘待处理’,‘审理中’,‘结案’,‘撤销’)
(d) CHECK(立案日期<=结案日期)
【问题2】
(1)(e)职工.姓名AS主审法官姓名
(f)案件,被告,律师,职工(关系模式的顺序无关)
(g)案件.主审法官=职工.职工编号 AND案件.案件状态=‘待处理’
(2)(h)立案日期BETWEEN ’OI-JAN-2009’ AND ‘31_DEC_2009’或者立案日期>=
‘Ol-JAN-2009’AND立案日期<=‘31-DEC-2009’
(i) ORDER BY案件数DESC
(3)(j)案件.被告=被告.被告编号
(k)姓名,地址
(l) HAVING count(*)>5
【问题3】
(m) INSERT
(n) SET状态=’审理中’
(o)案件编号=nrow.案件编号 - 试题解析:
本题考查SQL语句的基本语法与结构知识。
此类题目要求考生掌握SQL语句的基本语法和结构,认真阅读题目给出的关系模式,针对题目的要求具体分析并解答。
【问题1】
由于问题1中“案件编号唯一标识一个案件”可案件编号为案件关系的主键,即不能为空且唯一标识一条账户信息,因此需要用PRIMARY KEY对该属性进行主键约束,当然,用NOT NULL UNIQUE也可以实现;(b)空处是要给主审法官这个属性进行约束,根据题目意思,我们可以知道主审法官的属性值应该是员工编号,因此主审法官应该属于外键,因此该空应填:REFERENCES职工(职工编号);(c)空是要为案件选择其状态,由于题目高位我们案件状态有“待处理”、“审理中”、“结案”和“撤销”四种,因此该空应填:CHECK VALUES IN(‘待处理’,‘审理中’,‘结案’,‘撤销’)。
另外,根据问题一的要求,要求立案日期小于等于结案日期,而这一功能在前面很显然没有实现,因此(d)空应该用来实现这一功能,因此本空应填:CHECK(立案日期<=结案日期)。
【问题2】
SQL查询通过SELECT语句实现。
(1)根据题目要求,即显示案件的案件编号、立案日期、被告姓名、被告地址、案件描述、律师姓名和主审法官姓名。而在本小题给出的查询语句中,很明显主审法官姓名没有体现,而主审法官的姓名实际就是职工关系模式中的姓名属性,是因此空(e)应该填:职工.姓名AS主审法官姓名。而空(f)是要给出需要查询的表名,在本题中,需查询案件,被告,律师,职工表,因此本空应填:案件,被告,律师,职工。根据本小题的题目要求,应该要查询当前待处理的诉讼案件,而且需要查找4个表,因此要将各表联系起来,而在题目中给出了案件表与律师和被告表的联系,那么接着应该给出案件表与职工表的联系及定义查找的案件为待处理状态的案件。因此(g)空需要填写:案件.主审法官=职工.职工编号 AND案件.案件状态=‘待处理’。
(2)本小题要求查询2009年立案的各类案件数,并按案件数降序排序。空(h)是WHERE后面缺失的内容,WHERE后面的内容应该是查询的条件,那么这里应该要求查找2009年立案的各类案件,换句话说,就是要查找在2009年1月1号至2009年12月31号之间立案的各类案件,因此该空应填:立案日期BETWEEN ‘OI-JAN-2009’ AND ‘31_DEC_2009’。接下来的语言“GROUP BY类型”实现了将查询结果按案件类型进行分类,那么最后的工作就是要统计各类案件的数量并按案件数降序排序,因此空(i)处应填:ORDER BY案件数DESC。
(3)本小题要求查询立案次数超过5次的被告姓名和地址。从前面的SQL语句我们可以看出,该次查询要对案件和被告表进行查询,因此需要将这两个表进行关联,因此空(j)的功能就是要将这两个表进行关联,因此该空应填:案件.被告=被告.被告编号。空(k)处很显然是要填按什么分组,根据题目意思,是要按姓名和地址来进行分组统计,所以本空应填:姓名,地址。在进行统计分组后,我们应该筛选出满足题目要求的项,因此空(l)应填:HAVING count(*)>5。
【问题3】
本题要求我们掌握创建触发器的基本语法结构。本题要求当插入一个审理记录时,检查案件的状态,若状态为“未处理”,则将其修改为“审理中”。根据触发器的创建格式我们可知空(m)处是要指明该触发器要侦测的数据操作事件,根据题目意思,侦测的数据操作事件是插入一个审理记录。因此本空应填:INSERT。而这个触发器要完成的功能题目已经描述得很清楚,是要将状态从“未处理”修改为“审理中”,因此空(n)处就是要更新状态为审理中,因此本空应填:SET状态=‘审理中’,那么具体更新的是那条记录,应该通过WHERE语句来指定,而每条记录都是通过案件编号来唯一标识的,因此空(o)处应填:案件编号=nrow.案件编号。
CREATE TRIGGER 审理TRIGGER AFTER INSERT ON审理
REFERENCING new row AS nrow
FOR EACH row
WHEN‘未处理’=(SELECT状态
FROM案件
WHERE案件编号- nrow.案件编号)
BEGIN
UPDATE案件SET状态=‘审理中’
WHERE案件编号=nrow.案件编号;
END
第 3 题
【说明】
某服装销售公司拟开发一套服装采购管理系统,以方便对服装采购和库存进行管理。
【需求分析】
(1)采购系统需要维护服装信息及服装在仓库中的存放情况。系统按服装的销售种类记录服装信息。服装信息主要包括:服装编码、服装描述、服装类型、销售价格、尺码和面料,其中,服装类型为销售分类,服装按销售分类编码。仓库信息主要包括:仓库编码、仓库位置、仓库容量和库管员。系统记录库管员的库管员编码、姓名和级别。一个库管员可以管理多个仓库,每个仓库有一名库管员。一个仓库中可以存放多类服装,一类服装可能存放在多个仓库中。
(2)当库管员发现有一类或者多类服装缺货时,需要生成采购订单。一个采购订单可以包含多类服装。每类服装可由多个不同的供应商供应,但具有相同的服装编码。采购订单主要记录订单编码、订货日期和应到货日期,并需详细记录所采购的每类服装的数量、采购价格和对应的多个供应商。
(3)系统需记录每类服装的各个供应商信息和供应情况。供应商信息包括:供应商编码、供应商名称、地址、企业法人和联系电话。供应情况记录供应商所供应服装的服装类型和服装质量等级。一个供应商可以供应多类服装,一类服装可由多个供应商供应。库管员根据入库时的服装质量情况,设定或修改每个供应商所供应的每类服装的服装质量等级,用以作为后续采购服装时,选择供应商的参考标准。
【概念模型设计】
根据需求阶段收集的信息,设计的实体联系图(不完整)如图1-1所示。
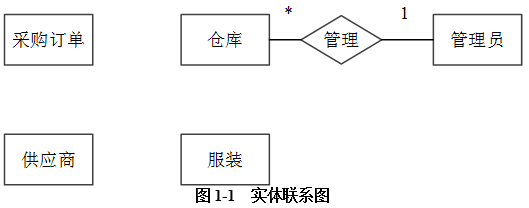
【逻辑结构设计】
根据概念模型设计阶段完成的实体联系图,得出如下关系模式(不完整):
库管员( (1) ,姓名,级别)
仓库信息( (2) ,仓库位置,仓库容量)
服装(服装编码,服装描述,服装类型,尺码,面料,销售价格)
供应商( (3) ,供应商名称,地址,联系电话,企业法人)
供应情况( (4) ,服装质量等级)
采购订单( (5) )
采购订单明细( (6) )
【问题1】(6分)
补充图1-1中的联系和联系的类型。
【问题2】(6分)
根据图1-1,将逻辑结构设计阶段生成的关系模式中的空(1)~(6)补充完整。对所有关系模式,用下划线指出各关系模式的主键。
【问题3】(3分)
如果库管员定期需要轮流对所有仓库中的服装质量进行抽查,对每个仓库中的每一类被抽查服装需要记录一条抽查结果,并且需要记录抽查的时间和负责抽查的库管员。请根据该要求,对图1-1进行修改,画出修改后的实体间联系和联系的类型
答案与解析
- 试题难度:较难
- 知识点:数据库技术基础>E-R模型
- 试题答案:【问题1】(6分)
(联系各1分,联系的类型各一分)【问题2】(6分)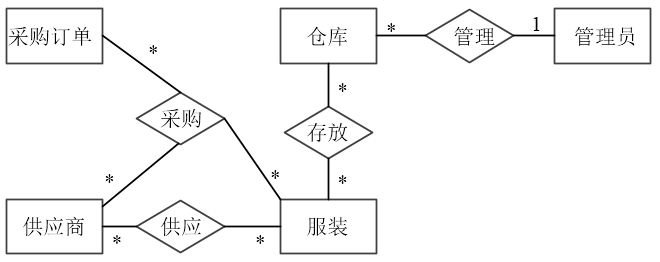
(每个空1分,主键各0.5分)
(1)库管理员编码
(2)仓库编码,库管理员编码
(3)供应商编码
(4)供应商编码,服装编码
(5)订单编码,到货日期,应到货日期
(6)订单编码,服装编码,供应商编码
,数量,采购价格
【问题3】(3分)
(联系“抽查”2分,联系的类型1分)

- 试题解析:
本题考查数据库概念结构设计、概念至逻辑结构转换等内容。
此类题目要求考生认真阅读题目,根据题目的需求描述,给出实体间的联系。
【问题1】
本题主要考查根据题目描述补充完整ER图。
在本题中,根据题目描述“一个仓库中可以存放多类服装,一类服装可能存放在多个仓库中”,我们可以知道服装与仓库间存在多对多的联系“存放”;根据题目描述“一个供应商可以供应多类服装,一类服装可由多个供应商供应。”我们可以知道,供应商与服装之间存在多对多的供应关系;然后我们根据题目描述“一个采购订单可以包含多类服装。每类服装可由多个不同的供应商供应”可知,在服装、供应商和采购订单之间存在一个采购联系,其中三端都是多端。
【问题2】
该问题要我们补充完整各关系模式中缺失的属性并给出各关系模式的主键。要补充各关系模式缺失的属性应该根据题目的描述来完成。
第1空是要我们补充仓库管员关系模式所缺失的属性,根据题目的描述,库管员的包括:库管员编码、姓名和级别。因此第1空应该填(库管员编码),其中库管员编码是库管员关系模式的主键。
第2空是要我们补充仓库信息关系模式所缺失的属性,根据题目的描述,仓库信息包括:仓库编码、仓库位置、仓库容量和库管员,因此第2空应该填(仓库编码,库管员编码),这里用库管员编码而不用库管员的原因是库管员编码是库管员关系模式的主键,而本关系模式的主键是仓库编码。
第3空是要我们补充供应商关系模式所缺失的属性,根据题目的描述,供应商信息包括:供应商编码、供应商名称、地址、企业法人和联系电话。因此第3空应该填(供应商编码,其主键为供应商编码)。
第4空是要我们补充供应情况所缺失的属性,供应是供应商与服装之间的联系,而这里是一个多对多的联系,多对多的联系在转换为单独的关系模式时,属性包括两端实体的主键其自身的一些属性,因此第4空应该填(供应商编码,服装编码),而该关系模式的主键为(供应商编码,服装编码)。
第5空要与第6空一起来考虑。第5空要我们补充采购订单关系模式所缺失的属性,根据题目的描述,采购订单主要记录订单编码、订货日期和应到货日期,并详细记录所采购的每类服装的数量、采购价格和对应的多个供应商。这里由于有关系模式采购订单明细,所以第5空应该填(订单编码,订货日期,应到货日期),而第6空应该填(订单编码,服装编码,供应商编码,数量,采购价格)。而采购订单的主键为订单编码,另外,由于题目描述“一个采购订单可以包含多类服装。每类服装可由多个不同的供应商供应”,可知采购订单明细的主键为(服装编码,供应商编码,订单编码)。
【问题3】
本题描述“如果库管员定期需要轮流对所有仓库中的服装质量进行抽查”,我们可以知道抽查与库管员、仓库及服装这三个实体有关系,而且三端都是多端。这样就很容易画E-R图(见试题答案)。
第 4 题
【说明】
某学校拟开发一套校友捐赠管理系统,以便对校友的捐赠资金进行管理。
【需求分析】
校友可以向学校提出捐赠申请,说明捐赠的金额、捐赠类型和使用方式。捐赠类型包括一次性捐赠和周期性捐赠。捐赠的使用方式分为两种:一种用于资助个人,即受益人为多名学生或老师,主要用于奖学金、奖教金和助学金等;另一种用于资助捐赠项目,即资助已有的捐赠项目和设立新的捐赠项目,主要用于改善教学设施、实验室建设和设备购买等。一个捐赠项目可以涉及校内的多个受益单位,每个单位在该项目中有确定的受益比例。每个单位的受益比例是指在一个捐赠项目中的每个单位所应得的金额占该捐赠项目总受益金额的比例。一个捐赠项目可以由多个捐赠来资助,一个捐赠也可以资助多个捐赠项目。系统需记录一个捐赠给所资助的每个捐赠项目的具体的捐赠金额,即每个捐赠项目能从一个捐赠中受益的金额。
初步设计了校友捐赠信息数据库,其关系模式如图1-1所示。

关系模式的主要属性、含义及约束如表1-1所示。
【问题1】(5分)
对关系“校友信息”,请回答以下问题:
(1)列举出所有候选键的属性。
(2)它可达到第几范式,用60字以内文字简要叙述理由。
【问题2】(6分)
对关系“捐赠信息”,请回答以下问题:
(1)用100字以内文字简要说明它会产生什么问题。
(2)将其分解为第三范式,分解后的关系名依次为:捐赠信息1,捐赠信息2,……
(3)列出其被修正后的各关系模式的主键。
【问题3】(4分)
对关系“项目受益情况”,请回答以下问题:
(1)它是否是第四范式,用100字以内文字叙述理由。
(2)将其分解为第四范式,分解后的关系名依次为:项目受益情况l,项目受益情2,……
答案与解析
- 试题难度:较难
- 知识点:关系数据库>1NF至4NF
- 试题答案:
【问题1】 (5分)
(1)“校友编号”和“身份证号”(2分)
(2)“校友信息”关系模式可以达到第二范式,不满足第三范式。(2分)
由于“校友信息”关系模式的主键是“校友编号”,但义包含函数依赖:
班级一院系,入学年份
不满足第三范式的要求,即:存在非主属性对码的传递依赖。(1分)
【问题2】 (6分)
(1)“捐赠信息”关系不满足第二范式,即:非主属性不完全依赖于码。
会造成:插入异常、删除异常和修改复杂(或修改异常)。(2分)
(2)分解后的关系模式如下:(2分)
捐赠信息1(捐赠编号,捐赠校友,捐赠时间,捐赠金额,捐赠类型,使用方式)
捐赠信息2(受益人身份证号,受益人姓名,受益人所在单位,受益人类型)
捐赠信息3(捐赠编号,受益人身份证号,受益金额,使用说明)
(3)修正后的主键如下:(2分)
捐赠信息1(捐赠编号,捐赠校友,捐赠时间,捐赠金额,捐赠类型,使用方式)
捐赠信息2(受益人身份证号,受益人姓名,受益人所在单位,受益人类型)
捐赠信息3(捐赠编号,受益人身份证号,受益金额,使用说明)
【问题3】 (4分)
(1)“项目受益情况”关系模式,不满足第四范式。(2分)
答出该关系模式存在多值依赖,给1分;
若答出如下原因,给1分:
项目编号→→受益单位,受益比例
或项目编号→→捐赠编号,项目受益金额
(2)分解后的关系模式如下:(2分)
项目受益情况l(项目编号,受益单位,受益比例)
项目受益情况2(项目编号,捐赠编号,项目受益金额) - 试题解析:
本题考查数据库理论的规范化,主要包括码和范式的确定及关系模式的分解。
【问题1】
本问题考查候选键及范式的判断。
在校友信息关系模式中,显然,校友编号和身份证号都能唯一标识一条记录,因此它们都应该是候选键,而其他的属性不能唯一标识一条记录。
由于该关系模式的候选键是单个属性,因此该关系模式中不存在部分依赖,所以满足第2NF,但由于“校友信息”关系模式的主键是“校友编号”,但义包含函数依赖:班级→院系,入学年份,因此存在非主属性对码的传递依赖,因此不满足第三范式。因此“校友信息”关系模式可以达到第2NF。
【问题2】
本问题考查范式的判断及关系模式的分解。
在捐赠信息关系中,由于一个捐赠可以有多个受益人,因此捐赠信息关系的主键并不是捐赠编号,而应该是(捐赠编号,受益人身份证号)。因此,该关系模式中存在部分依赖,所以捐赠信息关系模式不满足第2NF,而是第1NF,因此存在插入异常、删除异常和修改异常等问题。
要将该关系模式分解成第3NF,那么首先我们就应该清楚,第3范式消除了非主属性对码的传递依赖和部分依赖。根据题目意思,在本关系模式中应该存在函数依赖:(捐赠编号→捐赠金额,捐赠校友,捐赠类型,使用方式,捐赠时间),(受益人身份证号→受益人姓名,受益人所在单位,受益人类型),这些函数依赖集应该很好确定,另外,就是受益金额和使用说明该怎么确定呢,根据题目意思是要根据捐赠和受益人情况来确定,因此还存在函数依赖(捐赠编号,受益人身份证号)→(受益金额,使用说明)。在清楚了这些依赖关系后,分解就变得容易了,如果要将该关系模式分解成第3范式,那么可以将3个函数依赖中的所有属性分别组合在一起形成一个关系模式,得到关系模式后,我们再来验证,是否有属性被遗漏,如果没有遗漏,在验证分解的结果是否都满足第三范式,如果满足,那么就得到了正确的分解结果,在一般情况下,这么做是成立的。通过验证,很显然分解后的三个关系模式都满足第3NF,它们的主键分别是捐赠编号,受益人编号和(捐赠编号,受益人身份证号)。
【问题3】
本问题考查第四范式的理解和应用。
在题目中我们可以看出,项目受益情况关系模式包括项目编号,受益单位,受益比例,捐赠编号,项目受益金额等属性。而题目告诉我们一个捐赠项目可以涉及校内的多个受益单位,每个单位在该项目中有确定的受益比例,那么我们就可以存在多值依赖项目编号→→受益单位,受益比例。
另外,根据题目描述“一个捐赠项目可以由多个捐赠来资助,一个捐赠也可以资助多个捐赠项目。系统需记录一个捐赠给所资助的每个捐赠项目的具体的捐赠金额,即每个捐赠项目能从一个捐赠中受益的金额”,我们可以知道存在多值依赖项目编号→→捐赠编号,项目受益金额。
而且存在的这些多值依赖都是非平凡的多值依赖,根据第四范式的要求:如果关系中存在非平凡的多值依赖X→→Y,X包含码,则该关系模式为第四范式,我们可以知道该关系模式不是第四范式,因为项目编号显然不是该关系模式的主键,它不能唯一确定一条记录。
要将该关系模式分解,也可以采用第二个问中描述的方法,即将该关系模式分解为(项目编号,受益单位,受益比例)和(项目编号,捐赠编号,项目受益金额),很显然,项目受益情况关系模式的属性都包含在分解的两个关系模式中了,分解得到的两个关系模式也都满足第四范式的要求。
第 5 题
【说明】
某网上商品销售系统的业务流程如下:
(1)将客户的订单记录(订单号,客户ID,商品ID,购买数量)写入订单表;
(2)将库存表(商品ID,库存量)中订购商品的库存量减去该商品的购买数量。
针对上述业务流程,完成下列问题:
【问题1】(3分)
假设库存量有大于等于0的约束,可能出现如下情况:当订单记录写入订单表后,修改库存表时因违反约束而无法执行,应如何处理?(100字以内)
【问题2】(6分)
引入如下伪指令:将商品A的订单记录插入订单表记为I(A);读取商品A的库存量到变量x,记为x=R(A);变量x值写入商品A中的库存量,记为W(A,x)。则客户i的销售业务伪指令序列为:Ii(A),xi=Ri (A),xi=xi-ai,Wi (A,Xi)。其中ai为商品的购买数量。
假设当前库存量足够,不考虑发生修改后库存量小于0的情况。若客户1、客户2同时购买同一种商品时,可能出现的执行序列为:I1(A),I2 (A),X1=R1 (A),X2= R2 (A),x1= x1-a1 , W1 (A, xi), X2 =X2- a2, W2(A,X2)。
(1)此时会出现什么问题(100字以内)?
(2)为了解决上述问题,引入共享锁指令SLock(A)和独占锁指令XLock(A)对数据A进行加锁,解锁指令Unlock(A)对数据A进行解锁,客户i的加锁指令用SLocki(A)表示,其他类同。插入订单表的操作不需要引入锁指令。请补充上述执行序列,使其满足2PL协议,并使持有锁的时间最短。
【问题3】(6分)
下面是用E-SQL实现的销售业务程序的一部分,请补全空缺处的代码。
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
INSERT INTO 订单表VALUES(:OID,:CID,:MID,:qty);
If error then {ROLLBACK; (a) ;}
UPDATE库存表
SET库存量=库存量-:qty
WHERE (b) ;
If error then {ROLLBACK; return;}
(c)
答案与解析
- 试题难度:较难
- 知识点:事务管理>并发操作设计
- 试题答案:
【问题1】(3分)
将写订单记录和修改库存表作为一个完整的事务来处理,当修改库存表无法执行时,回滚事务,则会撤销写入的订单记录,数据库保持一致。
【问题2】(6分)
(1)出现问题:客户购买后写入的库存量值被覆盖,库存量不能体现客户1已购买,属于丢失修改造成的数据库不一致性。(3分)
(2)重写后的序列:(3分)
I1(A), I2(A), XLock1 (A), x1 = R1 (A), x1=x1- a1, W1 (A, x1), Unlock1 (A),XLock2(A),
X2 = R2 (A), x2=x2-a2, W2 (A, X2), Unlock2 (A)。
注:若锁持续时间不是最短,可扣1分。
【问题3】 (6分,各2分)(a) return
(b) 商品ID=:MID
(c) COMMIT - 试题解析:
本题考查的是并发控制的概念和应用,属于比较传统的题目,考查点也与往年类似。
【问题1】
在本问题中,根据题目的描述,是完全有可能存在库存量小于购买数量的情况的,为了避免写入订单操作已做,而修改库存表因违反约束而无法执行的情况,可以将写订单记录和修改库存表作为一个完整的事务来处理,当修改库存表无法执行时,回滚事务,则会撤销写入的订单记录,数据库保持一致。
【问题2】
本问题考查对事务并发控制的相关知识的理解掌握。
在本题中,根据题目给出的执行序列:I1(A),I2 (A),X1=R1 (A),X2= R2 (A),x1= x1—a1 , W1 (A, xi), X2 =X2- a2, W2(A,X2)来执行,那么首先就是客户1和客户2都将商品A的订单记录插入订单表记录,然后分别读取库存量的值,接着就是将库存量减去客户1的购买数量,并将做差的结果写入商品A中的库存,然后又将读取到的原来的库存量值减去客户2的购买数量,并将做差的结果写入商品A中的库存,这样整个程序执行结束后,商品A中的库存量数值只等于原来的库存量值减去客户2的购买数量,而丢失了客户1对商品A库存量值的修改。这种情况属于丢失修改造成的数据库不一致性。
对于这类问题,可以采用加锁的方式使执行序列满足2PL协议,这里大家需要注意,共享锁只允许读,而不允许写,独占锁才即允许读又允许写,当然,共享锁是可以升级为独占锁的,但为了节约时间,应该在一开始就加独占锁。加锁后的正确序列为:I1(A), I2(A), XLock1 (A), x1 = R1 (A), x1=x1- a1, W1 (A, x1), Unlock1 (A), XLock2(A), X2 = R2 (A), x2=x2-a2, W2 (A, X2), Unlock2 (A)。【问题3】
本地给出的空缺(a)处是在产生错误时,应该执行的语句,这是将客户的订单记录写入订单表时产生错误,如果产生错误就应该回滚并返回,因此(a)空应填:return。而(b)空处是指出需要修改的表的记录,根据题目意思,这里是修改库存表(商品ID,库存量),其主键是商品ID,因此本空应填:商品ID=:MID。而空(c)是给出的最后一条语句,并且是在不发生错误的情况下执行的,在操作完成后就应该提交。因此该空应填:COMMIT。