201705数据库上午真题
第 1 题
- (A) 程序计数器 (PC)
- (B) 累加器 (AC)
- (C) 指令寄存器 (IR)
- (D) 地址寄存器 (AR)
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>运算器与控制器
- 试题答案:[['B']]
- 试题解析:寄存器是CPU中的一个重要组成部分,它是CPU内部的临时存储单元。寄存器既可以用来存放数据和地址,也可以存放控制信息或CPU工作时的状态。在CPU中增加寄存器的数量,可以使CPU把执行程序时所需的数据尽可能地放在寄存器件中,从而减少访问内存的次数,提高其运行速度。但是寄存器的数目也不能太多,除了增加成本外,由于寄存器地址编码增加也会增加指令的长度。CPU中的寄存器通常分为存放数据的寄存器、存放地址的寄存器、存放控制信息的寄存器、存放状态信息的寄存器和其他寄存器等类型。程序计数器用于存放指令的地址。当程序顺序执行时,每取出一条指令,PC内容自动增加一个值,指向下一条要取的指令。当程序出现转移时,则将转移地址送入PC,然后由PC指向新的程序地址。
程序状态寄存器用于记录运算中产生的标志信息,典型的标志位有进位标志位、零标志位、符号标志位、溢出标志位、奇偶标志等。
地址寄存器包括程序计数器、堆栈指示器、变址寄存器、段地址寄存器等,用于记录各种内存地址。
累加寄存器通常简称为累加器,它是一个通用寄存器。其功能是当运算器的算术逻辑单元执行算术或逻辑运算时,为ALU提供一个工作区。例如,在执行一个减法运算前,先将被减数取出放在累加器中,再从内存储器取出减数,然后同累加器的内容相减,所得的结果送回累加器中。累加器在运算过程中暂时存放被操作数和中间运算结果,累加器不能用于长时间地保存一个数据。
指令寄存器:一般用来保存当前正在执行的一条指令。
地址寄存器:一般用来保存当前CPU所访问的内存单元的地址,以方便对内存的读写操作。
第 2 题
- (A) 将 a 与 0x000F 进行"逻辑与"运算,然后判断运算结果是否等于 0
- (B) 将 a 与 0x000F 进行"逻辑或"运算,然后判断运算结果是否等于 F
- (C) 将 a 与 0xFFF0 进行"逻辑或"运算,然后判断运算结果是否等于0
- (D) 将 a 与 0xFFF0 进行"逻辑与"运算,然后判断运算结果是否等于 F
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>数据的表示
- 试题答案:[['A']]
- 试题解析:要判断数的最后四位是否都为0,应该将最后四位与1进行逻辑与运算,其他数位与0做逻辑与运算,最后判定最终的结果是否为0;因此得出与a进行逻辑与运算的数:前12位为0最后4位为1,即0x000F逻辑或运算:0 或 0 = 0;1 或 0 = 1;0 或 1 = 1;1 或 1 = 1;
逻辑与运算:0 与 0 = 0;1 与 0 = 0;0 与 1 = 0;1 与 1 = 1;
第 3 题
- (A) 中断
- (B) 程序查询
- (C) 无条件传送
- (D) DMA
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>I/O控制方式
- 试题答案:[['D']]
- 试题解析:直接程序控制(无条件传送/程序查询方式):无条件传送:在此情况下,外设总是准备好的,它可以无条件地随时接收CPU发来的输出数据,也能够无条件地随时向CPU提供需要输入的数据
程序查询方式:在这种方式下,利用查询方式进行输入输出,就是通过CPU执行程序查询外设的状态,判断外设是否准备好接收数据或准备好了向CPU输入的数据,
中断方式:由程序控制I/O的方法,其主要缺点在于CPU必须等待I/O系统完成数据传输任务,在此期间CPU需要定期地查询I/O系统的恶状态,以确认传输是否完成。因此整个系统的性能严重下降。
直接主存存取(Direct Memory Access,DMA)是指数据在主存与I/O设备间的直接成块传送,即在主存与I/O设备间传送数据块的过程中,不需要CPU作任何干涉,只需在过程开始启动(即向设备发出“传送一块数据”的命令)与过程结束(CPU通过轮询或中断得知过程是否结束和下次操作是否准备就绪)时由CPU进行处理,实际操作由DMA硬件直接完成,CPU在传送过程中可做别的事情。
第 4 题
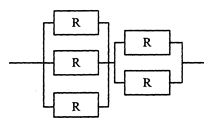
>- (A) (1-R³)(1-R²) >- (B) (1-(1-R)³)( 1-(1-R)²) >- (C) (1-R³) + (1-R²) >- (D) (1-(1-R)³) + ( 1-(1-R)²) **答案与解析** - 试题难度:容易 - 知识点:计算机组成与体系结构>可靠性 - 试题答案:[['B']] - 试题解析:
在本题中,既有并联又有串联,计算时首先我们要分别计算图中两个并联后的可靠度,它们分别为(1-(1-R)3)和(1-(1-R)2)。,然后是两者串联,根据串联的计算公式,可得系统的可靠度为(1-(1-R)3)(1-(1-R)2)。因此本题答案选B。
### 第 5 题
- (A) 3
- (B) 4
- (C) 5
- (D) 6
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>校验码
- 试题答案:[['C']]
- 试题解析:设数据位是n位,校验位是k位,则海明码n和k必须满足以关系:2k−1≥n+k将数值代入公公式,k应等于5。
第 6 题
- (A) Cache的设置扩大了主存的容量
- (B) Cache的内容是主存部分内容的拷贝
- (C) Cache 的命中率并不随其容量增大线性地提高
- (D) Cache 位于主存与 CPU 之间
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>Cache
- 试题答案:[['A']]
- 试题解析:高速缓存是用来存放当前最活跃的程序和数据的,作为主存局部域的副本,其特点是:容量一般在几KB到几MB之间;速度一般比主存快5到10倍,由快速半导体存储器构成;其内容是主存局部域的副本,对程序员来说是透明的。高速缓存的组成如下图所示:Cache由两部分组成:控制部分和Cache部分。Cache部分用来存放主存的部分拷贝(副本)信息。控制部分的功能是:判断CPU要访问的信息是否在Cache中,若在即为命中,若不在则没有命中。命中时直接对Cache存储器寻址。未命中时,要按照替换原则,决定主存的一块信息放到Cache的哪一块里面。
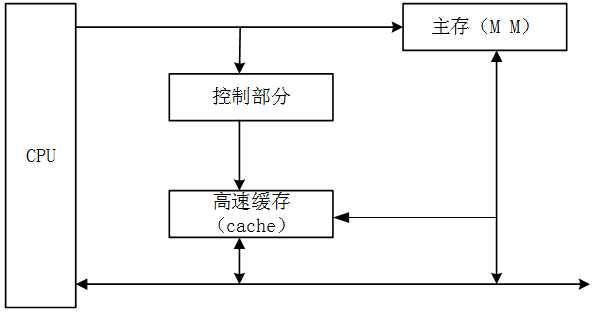
第 7 题
- (A) SSH
- (B) SSL
- (C) SHA-1
- (D) SET
答案与解析
- 试题难度:一般
- 知识点:信息安全>网络安全协议
- 试题答案:[['B']]
- 试题解析:HTTPS(全称:Hyper Text Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。
第 8 题
- (A) RSA
- (B) SHA-1
- (C) MD5
- (D) RC5
答案与解析
- 试题难度:一般
- 知识点:信息安全>对称加密与非对称加密
- 试题答案:[['D']]
- 试题解析:加密技术中对称性加密技术的算法效率比较高,适合于大量数据的加密,在本题中属于对称性加密算法的只有RC5。
第 9 题
- (A) A、B 互换私钥
- (B) A、B 互换公钥
- (C) I1、I2 互换私钥
- (D) I1、I2 互换公钥
答案与解析
- 试题难度:一般
- 知识点:信息安全>数字证书
- 试题答案:[['D']]
- 试题解析:由于密钥对中的私钥只有持有者才拥有,所以私钥是不可能进行交换的。可以排除A、C两个选项。A、B要互信,首先其颁发机构必须能相互信任,所以可以排除B选项。
第 10 题
- (A) 甲
- (B) 乙
- (C) 甲与乙共同
- (D) 软件设计师
答案与解析
- 试题难度:一般
- 知识点:法律法规与标准化>知识产权人确定
- 试题答案:[['A']]
- 试题解析:对于委托开发的作品,如果有合同约束著作权的归属,按合同约定来判定;如果合同没有约定,则著作权归创造方。
第 11 题
- (A) 医疗仪器
- (B) 墙壁涂料
- (C) 无糖食品
- (D) 烟草制品
答案与解析
- 试题难度:一般
- 知识点:法律法规与标准化>其它
- 试题答案:[['D']]
- 试题解析:《商标法实施细则》规定,必须使用注册商标的商品范围包括:1、国家规定并由国家工商行政管理局公布的人用药品和烟草制品;
2、国家规定并由国家工商行政管理局公布的其他商品。商标法规定,必须使用注册商标的商品在商标未经核准注册时不得在市场上销售。
第 12 题
- (A) 甲、乙作为共同申请人
- (B) 甲或乙一方放弃权利并从另一方得到适当的补偿
- (C) 甲、乙都不授予专利权
- (D) 甲、乙都授予专利权
答案与解析
- 试题难度:一般
- 知识点:法律法规与标准化>知识产权人确定
- 试题答案:[['D']]
- 试题解析:软件专利权是指通过申请专利对软件的设计思想进行保护的一种方式,而非对软件本身进行的保护,我国在专利保护上,实行先申请制度,即谁申请在先,谁就享有该专利权。同时申请则协商归属,协商不成则同时驳回双方的专利申请。
第 13 题
- (A) 语音信号定义的频率最高值为 4 kHz
- (B) 语音信号定义的频率最高值为 8 kHz
- (C) 数字语音传输线路的带宽只有8 kHz
- (D) 一般声卡采样频率最高为每秒 8k 次
答案与解析
- 试题难度:一般
- 知识点:多媒体基础>音频数字化
- 试题答案:[['A']]
- 试题解析:音频数字化过程中采样频率应为声音最高频率2倍。本题采样频率为8KHz,所以其语音的最高频率应不超过4KHz。
第 14 题
- (A) 300×300
- (B) 300×400
- (C) 900×4
- (D) 900×1200
答案与解析
- 试题难度:容易
- 知识点:多媒体基础>图像数字化
- 试题答案:[['D']]
- 试题解析:图像分辨率是指组成一幅图像的像素密度;也是水平和垂直的像素表示;即用每英寸多少点(dpi)表示数字化图像的大小。
用300dpi来扫描一幅3×4英寸的彩色照片,那么得到一幅900×1200个像素点的图像
第 15 题
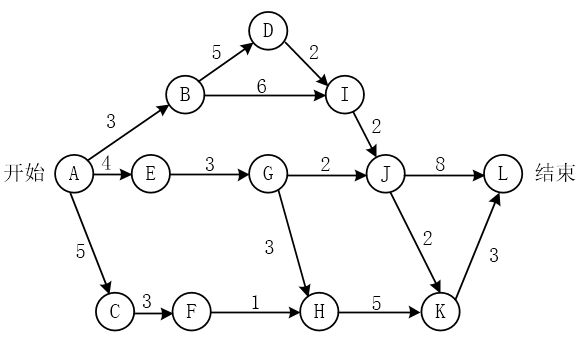 >- (A) 17
>- (B) 18
>- (C) 19
>- (D) 20
>- (A) 3 和 10
>- (B) 4 和 11
>- (C) 3 和 9
>- (D) 4 和 10
**答案与解析**
- 试题难度:一般
- 知识点:项目管理>Gant图与Pert图
- 试题答案:[['D'],['B']]
- 试题解析:
>- (A) 17
>- (B) 18
>- (C) 19
>- (D) 20
>- (A) 3 和 10
>- (B) 4 和 11
>- (C) 3 和 9
>- (D) 4 和 10
**答案与解析**
- 试题难度:一般
- 知识点:项目管理>Gant图与Pert图
- 试题答案:[['D'],['B']]
- 试题解析:有任务A→B需要3天,所以B→D应在第4天开始;由于H点最早结束的时间为10后(A→E→G→H),所以H→K应在第11天开始。
### 第 16 题
- (A) 数据流图
- (B) E-R 图
- (C) 状态-迁移图
- (D) 加工规格说明
- (A) 定义软件的主要结构元素及其之间的关系
- (B) 确定软件涉及的文件系统的结构及数据库的表结构
- (C) 描述软件与外部环境之间的交互关系,软件内模块之间的调用关系
- (D) 确定软件各个模块内部的算法和数据结构
答案与解析
- 试题难度:一般
- 知识点:软件工程>软件设计
- 试题答案:[['A'],['C']]
- 试题解析:软件设计必须依据对软件的需求来进行,结构化分析的结果为结构化设计提供了最基本的输入信息。从分析到设计往往经历以下流程:(1)研究、分析和审查数据流图。根据穿越系统边界的信息流初步确定系统与外部接口。
(2)根据数据流图决定问题的类型。数据处理问题通常有两种类型:变换型和事务型。针对两种不同的类型分别进行分析处理。
(3)由数据流图推导出系统的初始结构图。
(4)利用一些启发式原则来改进系统的初始结构图,直到得到符合要求的结构图为止。
(5)根据分析模型中的实体关系图和数据字典进行数据设计,包括数据库设计或数据文件的设计。
(6)在设计的基础上,依旧分析模型中的加工规格说明、状态转换图进行过程设计。
所以接口设计应该为需求分析阶段的数据流图,即选项A。
接口设计的主要任务为:描述软件与外部环境之间的交互关系,软件内模块之间的调用关系。
第 17 题
- (A) 32和8
- (B) 32和7
- (C) 28和8
- (D) 28和7
答案与解析
- 试题难度:一般
- 知识点:项目管理>其它
- 试题答案:[['D']]
- 试题解析:程序设计小组的组织形式一般有主程序员组,无主程序员组和层次式程序员组。其中无主程序员组中的成员之间相互平等,工作目标和决策都由全体成员民主讨论。对于项目规模较小、开发人员少、采用新技术和确定性较小的项目比较合适,而对大规模项目不适宜采用,所以其沟通路径的数量为(8×7)/2=28。而主程序员制则有主程序员负责决策,其他成员与主程序员沟通即可,所以其沟通路径数量为8-1=7。
第 18 题
>- (A) ①②③ >- (B) ②③④ >- (C) ①③⑤ >- (D) ②④⑤ **答案与解析** - 试题难度:一般 - 知识点:程序设计语言>程序语言的基本成分 - 试题答案:[['B']] - 试题解析:
第 19 题
- (A) (b|ab)*b
- (B) (ab)b
- (C) abb
- (D) (a|b)*b
答案与解析
- 试题难度:一般
- 知识点:程序设计语言>其它
- 试题答案:[['D']]
- 试题解析:正规式(a|b)*对应的正规集为{ε,a,b,aa,ab,…,所有由a和b组成的字符串},结尾为b。
第 20 题
- (A) 词法分析
- (B) 语法分析
- (C) 语义分析
- (D) 代码生成
答案与解析
- 试题难度:一般
- 知识点:程序设计语言>编译过程的6个阶段
- 试题答案:[['B']]
- 试题解析:词法分析阶段是编译过程的第一阶段,其任务是对源程序从前到后(从左到右)逐个字符扫描,从中识别出一个个“单词”符号。
词法分析过程的依据是语言的词法规则,即描述“单词”结构的规则。
语法分析阶段
其任务是在词法分析的基础上,根据语言的语法规则将单词符号序列分解成各类语法单位。
通常语法分析是确定整个输入串是否构成一个语法上正确的程序。
一般来说,通过编译的程序,不存在语法上的错误。
语义分析阶段
其任务主要检查源程序是否包含静态语义错误,并收集类型信息供后面的代码生成阶段使用。
语义分析的一个主要工作是进行类型分析和检查。
中间代码生成
其任务是根据语义分析的输出生成中间代码。
目标代码生成
是编译器工作的最后一个阶段。其任务是把中间代码变换成特定机器上的绝对指令代码、可重定位的指令代码或汇编指令代码。本阶段与具体机器密切相关。
第 21 题
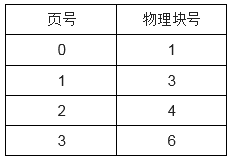
>- (A) 2048H >- (B) 4096H >- (C) 4D16H >- (D) 6D16H **答案与解析** - 试题难度:容易 - 知识点:操作系统>段页式存储 - 试题答案:[['C']] - 试题解析:
第 22 题
- (A) 12
- (B) 13
- (C) 14
- (D) 15
答案与解析
- 试题难度:一般
- 知识点:操作系统>死锁
- 试题答案:[['B']]
- 试题解析:给每个进程分配其所需的最大资源数少一个资源(本题3*4个),如果还有一个资源剩余,则不会发生死锁。因为将这个剩余资源分配给任意一个进程,该进程就会得到满足运行,其运行后,将其所释放的资源再分配给其他进程,这样所有的进程都可以执行完成。
第 23 题
- (A) 允许合理的划分三层的功能,使之在逻辑上保持相对独立
- (B) 允许各层灵活地选用平台和软件
- (C) 各层可以选择不同的开发语言进行并行开发
- (D) 系统安装、修改和维护均只在服务器端进行
答案与解析
- 试题难度:容易
- 知识点:软件工程>软件设计
- 试题答案:[['D']]
- 试题解析:C/S(客户机/服务器)体系结构由于在客户端需要安装相关的客户端软件,当客户端软件需要安装、修改和维护时,需要到每个客户端进行维护操作。
第 24 题
- (A) 尽量减少高扇出结构
- (B) 模块的大小适中
- (C) 将具有相似功能的模块合并
- (D) 完善模块的功能
答案与解析
- 试题难度:一般
- 知识点:软件工程>软件设计
- 试题答案:[['C']]
- 试题解析:将具有相似功能的模块合并,会导致模块的聚合程度变低,可维护性下降。在结构化设计中,系统由多个逻辑上相对独立的模块组成,在模块划分时需要遵循如下原则:
(1)模块的大小要适中。系统分解时需要考虑模块的规模,过大的模块可能导致系统分解不充分,其内部可能包括不同类型的功能,需要进一步划分,尽量使得各个模块的功能单一;过小的模块将导致系统的复杂度增加,模块之间的调用过于频繁,反而降低了模块的独立性。一般来说,一个模块的大小使其实现代码在1~2页纸之内,或者其实现代码行数在50~200行之间,这种规模的模块易于实现和维护。
(2)模块的扇入和扇出要合理。一个模块的扇出是指该模块直接调用的下级模块的个数;扇出大表示模块的复杂度高,需要控制和协调过多的下级模块。扇出过大一般是因为缺乏中间层次,应该适当增加中间层次的控制模块;扇出太小时可以把下级模块进一步分解成若干个子功能模块,或者合并到它的上级模块中去。一个模块的扇入是指直接调用该模块的上级模块的个数;扇入大表示模块的复用程度高。设计良好的软件结构通常顶层扇出比较大,中间扇出较少,底层模块则有大扇入。一般来说,系统的平均扇入和扇出系数为3或4,不应该超过7,否则会增大出错的概率。
(3)深度和宽度适当。深度表示软件结构中模块的层数,如果层数过多,则应考虑是否有些模块设计过于简单,看能否适当合并。宽度是软件结构中同一个层次上的模块总数的最大值,一般说来,宽度越大系统越复杂,对宽度影响最大的因素是模块的扇出。在系统设计时,需要权衡系统的深度和宽度,尽量降低系统的复杂性,减少实施过程的难度,提高开发和维护的效率。
第 25 题
- (A) 客户类无需知道所调用方法的特定子类的实现
- (B) 对象动态地修改类
- (C) 一个对象对应多张数据库表
- (D) 子类只能够覆盖父类中非抽象的方法
答案与解析
- 试题难度:一般
- 知识点:软件工程>面向对象
- 试题答案:[['A']]
- 试题解析:多态:同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果。在运行时,可以通过指向基类的指针,来调用实现派生类中的方法。也就是说客户类其实在调用方法时,并不需要知道特定子类的实现,都会用统一的方式来调用。
第 26 题
- (A) 程序的逻辑独立性
- (B) 程序的物理独立性
- (C) 数据的逻辑独立性
- (D) 数据的物理独立性
答案与解析
- 试题难度:一般
- 知识点:数据库技术基础>数据库的三级模式结构与两级映像
- 试题答案:[['C']]
- 试题解析:外模式/模式:保证了数据与程序的逻辑独立性,简称数据的逻辑独立性。模式/内模式:保证了数据与应用程序的物理独立性,简称数据的物理独立性。
外模式对应关系数据库的视图。
第 27 题
- (A) 逻辑设计
- (B) 需求分析
- (C) 物理设计
- (D) 运行维护
答案与解析
- 试题难度:一般
- 知识点:数据库设计>概念结构设计
- 试题答案:[['B']]
- 试题解析:数据库的设计阶段分为四个阶段:需求分析阶段、概念结构设计阶段、逻辑结构设计阶段、和物理结构设计阶段。数据库概念结构设计阶段是在需求分析的基础上,依照用户需求对信息进行分类、聚集和概括,建立概念模型。
第 28 题
- (A) 网状模型、关系模型、面向对象模型
- (B) 数据结构、网状模型、关系模型
- (C) 数据结构、数据操纵、关系模型
- (D) 数据结构、数据操纵、完整性约束
答案与解析
- 试题难度:一般
- 知识点:数据库技术基础>数据模型
- 试题答案:[['D']]
- 试题解析:数据模型的三要素数据结构:是所研究的对象类型的集合,是对系统静态特性的描述。
数据操作:对数据库中各种对象(型)的实例(值)允许执行的操作的集合,包括操作及操作规则。是对系统动态特性的描述。
数据的约束:是一组完整性规则的集合。也就是说,对于具体的应用数据必须遵循特定的语义约束条件,以保证数据的正确、有效、相容。
第 29 题
- (A) 若 wx →y , y →Z 成立,则 X →Z 成立
- (B) 若 wx →y ,y →Z 成立,则 W →Z 成立
- (C) 若 X →y ,WY →z 成立,则 xw →Z 成立
- (D) 若 X →y ,Z ⊆ U 成立,则 X →YZ 成立
答案与解析
- 试题难度:容易
- 知识点:关系数据库>Armstrong
- 试题答案:[['C']]
- 试题解析:
函数依赖的公理系统(Armstrong)
设关系模式R<U , F> , U是关系模式R的属性全集,F是关系模式R的一个函数依赖集。对于R<U,F>来说有以下的:
自反律:若Y⊆X⊆U,则X→Y为F所逻辑蕴含
增广律:若X→Y为F所逻辑蕴含,且Z⊆U,则XZ→YZ为F所逻辑蕴含
传递律:若X→Y和Y→Z为F所逻辑蕴含,则X→Z为F所逻辑蕴含
合并规则:若X→Y,X→Z,则X→YZ为F所蕴涵
伪传递率:若X→Y,WY→Z,则XW→Z为F所蕴涵
分解规则:若X→Y, Z⊆Y , 则X→Z为F所蕴涵
第 30 题
在关系R(A1,A2 ,A3) 和 S(
A2,A3 ,A4 ) 上进行 关系运算,与该关系表达式等价的是( )
关系运算,与该关系表达式等价的是( )
- (A)
- (B)
- (C)
- (D)

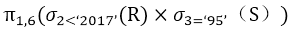
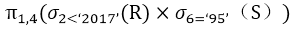
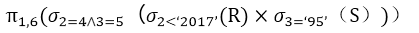
答案与解析
- 试题难度:一般
- 知识点:关系数据库>关系代数运算
- 试题答案:[['D']]
- 试题解析:题干的关系代数运算的含义是 R 与 S 先进行自然连接运算,然后在自然连接的基础上进行选择运算,最后做投影运算。自然连接运算,可以转化为R 与S先进行笛卡尔积运算,在笛卡尔积运算的基础上,进行选择运算,选择运算的条件为:R.A2=S.A2 AND R.A3=S.A3,然后在选择运算的结果集上,进行投影运算,投影运算是消除重复的列。
将表达式综合起来,进行优化可以转换成选项D的表达式。
第 31 题
- (A) CD
- (B) ABD
- (C) ACD
- (D) ADE
- (A) 具有无损连接性,且保持函数依赖
- (B) 不具有无损连接性,但保持函数依赖
- (C) 具有无损连接性,但不保持函数依赖
- (D) 不具有无损连接性,也不保持函数依赖
答案与解析
- 试题难度:一般
- 知识点:关系数据库>模式分解
- 试题答案:[['A'],['D']]
- 试题解析:本题中由于C和D只出现在左边,必为候选码的成员。当选择属性CD时,由于D→A,A→E;可以得出D→AE;由于D→A ,AC→B利用伪传递率得出 CD→B;由于D→AE和CD→B利用增广率和合并率得出CD→ABCDE。因此CD属性为候选码。利用无损连接性的判断定理:不存在R1∩R2→R1−R2或R1R2→R2−R1 被F逻辑蘊含的情况,所以分解不具有 无损连接性;同时F1∪F2≠F,所以分解也不保持函数依赖。
第 32 题
并发执行的三个事务T1 、T2 和T3,事务T1 对数据 D1 加了共享锁,事务T2、 T3分别对数据 D2 、D3 加了排 它锁,之后事务T1 对数据( );事务T2对数据( )。
- (A) D2 、D3 加排它锁都成功
- (B) D2 、D3 加共享锁都成功
- (C) D2 加共享锁成功 ,D3 加排它锁失败
- (D) D2 、D3 加排它锁和共享锁都失败
- (A) D1、D3 加共享锁都失败
- (B) D1 、D3 加共享锁都成功
- (C) D1 加共享锁成功 ,D3 加排它锁失败
- (D) D1 加排它锁成功 ,D3 加共享锁失败
答案与解析
- 试题难度:容易
- 知识点:事务管理>封锁协议
- 试题答案:[['D'],['C']]
- 试题解析:并发事务如果对数据读写时不加以控制,会破坏事务的隔离性和一致性。控制的手段就是加锁,在事务执行时限制其他事务对数据的读取。在并发控制中引入两种锁:排它锁(Exclusive Locks,简称X 锁)和共享锁(Share Locks,简称S 锁)。排它锁又称为写锁,用于对数据进行写操作时进行锁定。如果事务 T 对数据 A 加上X 锁后,就只允许事务 T 读取和修改数据 A ,其他事务对数据A 不能再加任何锁,从而 也不能读取和修改数据 A ,直到事务T 释放 A 上的锁。
共享锁又称为读锁,用于对数据进行读操作时进行锁定。如果事务 T 对数据 A 加上 了 S 锁后,事务 T 就只能读数据 A 但不可以修改,其他事务可以再对数据 A 加 S 锁来读取,只要数据 A 上有 S 锁,任何事务都只能再对其加 S 锁读取而不能加 X 锁修改。
第 33 题
- (A) 设计局部视图→抽象→修改重构消除冗余→合并取消冲突
- (B) 设计局部视图→抽象→合并取消冲突→修改重构消除冗余
- (C) 抽象→设计局部视图→修改重构消除冗余→合并取消冲突
- (D) 抽象→设计局部视图→合并取消冲突→修改重构消除冗余
答案与解析
- 试题难度:一般
- 知识点:数据库设计>概念结构设计
- 试题答案:[['D']]
- 试题解析:先划分好各个局部应用之后,使用抽象机制,确定局部应用中的实体、实体的属性、实体的标识符及实体间的联系及其类型,然后绘制局部E-R图,根据局部应用设计好各局部E-R图之后,就可以对各分E-R图进行合并。在合并过程中解决分E-R图中相互间存在的冲突,消除分E-R图之间存在的信息冗余使之成为能够被全系统所有用户共同理解和接受的统一的、精炼的全局概念模型。
第 34 题
- (A) 用户标识与鉴别
- (B) 存取控制
- (C) 数据加密
- (D) 审计
答案与解析
- 试题难度:容易
- 知识点:数据库运行与管理>数据库安全机制
- 试题答案:[['C']]
- 试题解析:使用数据加密技术,可以保障数据在传输过程是机密的。
第 35 题
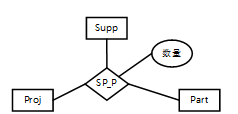
Supp (供应商号,供应商名,地址,电话) //供应商号唯一标识Supp中的每一个元组
Proj (项目号,项目名,负责人,电话) //项目号唯一标识 Proj 中的每一个元组
Part (零件号,零件名) //零件号唯一标识 Part 中的每一个元组
>- (A) *:*:* >- (B) 1:*:* >- (C) 1:1:* >- (D) 1:1:1 >- (A) 不需要生成一个独立的关系模式 >- (B) 需要生成一个独立的关系模式,该模式的主键为(项目号,零件号,数量) >- (C) 需要生成一个独立的关系模式,该模式的主键为(供应商号,数量) >- (D) 需要生成一个独立关系模式,该模式的主键为(供应商号,项目号,零件号) **答案与解析** - 试题难度:容易 - 知识点:数据库技术基础>E-R模型 - 试题答案:[['A'],['D']] - 试题解析:
题干中:“每个供应商可以为多个项目供应多种零件,每个项目可以由多个供应商供应多种零件,每种零件可以由多个供应商供应给多个项目”,说明三个实体间的联系类型应为:多对多对多。
对于多对多的联系在转关系时,应该转为一个独立的关系模式,该关系的主键,应为多方实体码的属性组成。
第 36 题
FROM <表名|视图名> [,· · · n]
[WHERE <条件表达式>]
[GROUP BY <列名> [ HAVNG <条件表达式>] ]
[ORDER BY <列名>[ASC|DESC] [,· · · n] ]
本题中,需要进行分组,分组的依据为供应商号;同时在分组的基础上需要指定条件,这时需使用HAVING子句,统计项目的个数大于,由于项目可能重复,因此在统计之前应该消除重复的项目,需使用DISTINCT关键字。
题干要求按供应商号进行降序排列,需使用ORDER BY子句和关键字DESC 。
### 第 37 题
- (A) 员工号, Emp 存在冗余以及插入异常和删除异常的问题
- (B) 员工号, Emp 不存在冗余以及插入异常和删除异常的问题
- (C) (员工号,岗位), Emp 存在冗余以及插入异常和删除异常的问题、
- (D) (员工号,岗位), Emp 不存在冗余以及插入异常和删除异常的问题
- (A) 存在传递依赖,故关系模式 Emp 最高达到 1NF
- (B) 存在传递依赖,故关系模式 Emp 最高达到 2NF
- (C) 不存在传递依赖,故关系模式 Emp 最高达到 3NF
- (D) 不存在传递依赖,故关系模式Emp最高达到4NF
答案与解析
- 试题难度:一般
- 知识点:关系数据库>1NF至4NF
- 试题答案:[['A'],['B']]
- 试题解析:由于员工号→(姓名,部门号,岗位,联系地址),岗位→薪资,利用传递率可以得出员工号→(姓名,部门号,岗位,联系地址,薪资),所以该关系的主码应该为员工号,由于存在传递函数依赖,所以不满足3NF的要求。
第 38 题
- (A) 允许属性对主键的部分依赖
- (B) 能够保证关系的实体完整性
- (C) 没有传递函数依赖
- (D) 可包含组合属性
答案与解析
- 试题难度:一般
- 知识点:关系数据库>1NF至4NF
- 试题答案:[['C']]
- 试题解析:若关系模式R∈1NF,若X→Y且Y⊊X时,X必含有码,则关系模式R属于第BC范式,记为:R∈BCNF。
BCNF是在3NF的基础要求消除键属性对码的部分和传递依赖。
第 39 题
- (A) 采用数据库方式管理数据是可见的,采用文件方式管理数据是不可见的
- (B) 采用数据库方式管理数据是不可见的,采用文件方式管理数据是可见
- (C) 采用数据障方式管理数据是可见的,采用文件方式管理数据是可见的
- (D) 采用数据库方式管理数据是不可见的,采用文件方式管理数据是不可见的
答案与解析
- 试题难度:一般
- 知识点:数据库技术基础>数据库管理系统(功能、特征)
- 试题答案:[['B']]
- 试题解析:通过DBMS管理数据有较高的数据独立性,数据独立性是指数据与程序独立,将数据的定义从程序中分离出去,由DBMS负责数据的存储,应用程序关心的只是数据的逻辑结构,无须了解数据在磁盘上的数据库中的存储形式,从而简化应用程序,大大减少应用程序编制的工作量。如果采用文件方式管理数据,应用程序得明确数据的定义等操作,也就是说程序员需要操作文件中的数据。
第 40 题
- (A) 只能通过数据库管理员授权
- (B) 可通过对象的所有者执行 GRANT 语句
- (C) 可通过自己执行 GRANT 语句
- (D) 可由任意用户授权
答案与解析
- 试题难度:一般
- 知识点:SQL语言>授权语句
- 试题答案:[['B']]
- 试题解析:在数据库中用户可以通过对象的所有者、拥有授予相关权限的权限的用户或者DBA执行GRANT语句获取对应的权限。
第 41 题
- (A) 原子性和一致性
- (B) 原子性和持久性
- (C) 隔离性和持久性
- (D) 隔离性和一致性
答案与解析
- 试题难度:一般
- 知识点:事务管理>事务的特性
- 试题答案:[['D']]
- 试题解析:原子性:事务是原子的,要么都做,要么都不做。一致性:事务执行的结果必须保证数据库从一个一致性状态变到另一个一致性状态。
隔离性:事务相互隔离。当多个事务并发执行时,任一事务的更新操作直到其成功提交的整个过程,对其他事物都是不可见的。
持久性:一旦事务成功提交,即使数据库崩溃,其对数据库的更新操作也永久有效。
串行调度:多个事务依次串行执行,且只有当一个事务的所有操作都执行完后才执行另一个事务的所有操作
可串行化保证了事务并行调度时,相互不破坏,同时保证了数据从一个一致性状态到另一个一致性状态。
第 42 题
- (A) 无死锁的调度
- (B) 可串行化调度
- (C) 可恢复调度
- (D) 可避免级联回滚的调度
答案与解析
- 试题难度:一般
- 知识点:事务管理>两段锁协议
- 试题答案:[['B']]
- 试题解析:两段锁协议是:对任何数据进行读写之前必须对该数据加锁,在释放了一个封锁之后,事务不再申请和获得任何其他封锁。这就缩短了持锁时间,提高了并发性,同时解决了数据的不一致性。两段封锁协议可以保证可串行化,它把每个事务分解为加锁和解锁两段。
第 43 题

>- (A) 可串行化调度 >- (B) 串行调度 >- (C) 非可串行化调度 >- (D) 产生死锁的调度 **答案与解析** - 试题难度:一般 - 知识点:事务管理>可串行化 - 试题答案:[['C']] - 试题解析:
- (A) 系统故障指软硬件错误导致的系统崩溃
- (B) 由于事务内部的逻辑错误造成该事务无法执行的故障属于事务故障
- (C) 可通过数据的异地备份来减少磁盘故障可能给数据库系统造成数据丢失
- (D) 系统故障一定会导致磁盘数据丢失
答案与解析
- 试题难度:容易
- 知识点:数据库运行与管理>故障分类与恢复
- 试题答案:[['D']]
- 试题解析:数据库故障主要分:事务故障、系统故障和介质故障。
事务故障
是指事务在运行至正常终点前被终止,此时数据库可能出现不正确的状态。
由于事务程序内部错误而引起的,有些可以预期,如金额不足等;有些不可以预期,如非法输入、运算溢出等
恢复过程
①反向(从后向前)扫描日志文件,查找该事务的更新操作。
②对该事务的更新操作执行逆操作,也就是将日志记录更新前的值写入数据库。
③继续反向扫描日志文件,查找该事务的其他更新操作,并作同样处理。
④如此处理下去,直到读到了此事务的开始标记,事务故障恢复就完成了。
事务故障的恢复由系统自动完成,对用户是透明的。
系统故障(通常称为软故障)
是指造成系统停止运转的任何事件,使得系统要重新启动。
特定类型的硬件错误、操作系统故障、DBMS代码错误、突然停电等。
恢复过程
①正向(从头到尾)扫描日志文件,找出故障发生前已经提交的事务(这些事务既有BEGIN TRANSACTION 记录,也有COMMIT记录),将其事务标识记入重做(REDO)队列。同时找出故障发生时尚未完成的事务(这些事务只有BEGIN TRANSACTION 记录,无相应的COMMIT记录),将其事务标识记入撤销(UNDO)队列。
②反向扫描日志文件,对每个UNDO事务的更新操作执行逆操作,也就是将日志记录中更新前的值写入数据库。
③正向扫描日志文件,对每个REDO事务重新执行日志文件登记的操作,也就是将日志记录中更新后的值写入数据库。
是在系统重启之后自动执行的。
介质故障(称为硬件故障)
是指外存故障,例如磁盘损坏、磁头碰撞,瞬时强磁场干扰等。
这类故障将破坏数据库或部分数据库,并影响正在存取这部分数据的所有事务,日志文件也被破坏
恢复过程。
①装入最新的数据库后备副本,使数据库恢复到最近一次转储时的一致性状态。
②转入相应的日志文件副本,重做已完成的事务。
介质故障的恢复需要DBA的介入,具体的恢复操作仍由DBMS完成。
恢复过程
①DBA只需要重装最近转储的数据库副本和有关的各日志文件副本。
②然后执行系统提供的恢复命令。
第 45 题
- (A) X(A,B,C,D,E,G)
- (B) X(A,B,C, D)
- (C) X(R.A,B,R.C,D,S.A,S.C,E,G)
- (D) X(B,D,E,G)
答案与解析
- 试题难度:容易
- 知识点:关系数据库>关系代数运算
- 试题答案:[['C']]
- 试题解析:R与S的笛卡尔积应该形成M+N元的关系,其中M表示来自关系R的列,N表示来自关系S列,如果列名存在重复的情况,则需要带上关系名,表示该列来自哪个关系如:R.A
第 46 题
- (A) A→AB
- (B) H→C
- (C) AEB→C
- (D) A→BH
答案与解析
- 试题难度:一般
- 知识点:关系数据库>其它
- 试题答案:[['D']]
- 试题解析:由于A→B,在加上A自身函数决定A,利用合并率,得出A→AB;由于H→E,E→C,利用传递率,得出H→C;
由于E→C,利用增广率和分解率,得出ABE→C;
函数依赖的公理系统(Armstrong)
设关系模式R<U,F>, U是关系模式R的属性全集,F是关系模式R的一个函数依赖集。对于R<U,F>来说有以下的:
自反律:若Y⊆X⊆U,则X→Y为F所逻辑蕴含
增广律:若X→Y为F所逻辑蕴含,且Z⊆U,则XZ→YZ为F所逻辑蕴含
传递律:若X→Y和Y→Z为F所逻辑蕴含,则X→Z为F所逻辑蕴含
合并规则:若X→Y,X→Z,则X→YZ为F所蕴涵
伪传递率:若X→Y,WY→Z,则XW→Z为F所蕴涵
分解规则:若X→Y, Z⊆Y , 则X→Z为F所蕴涵
第 47 题
- (A) 减少并发冲突
- (B) 提高一并故障恢复的效率
- (C) 避免级联回滚
- (D) 避免死锁
答案与解析
- 试题难度:容易
- 知识点:数据库运行与管理>日志文件
- 试题答案:[['B']]
- 试题解析:检查点将脏数据页从当前数据库的缓冲区高速缓存刷新到磁盘上。这最大限度地减少了数据库完整恢复时必须处理的活动日志部分。
第 48 题
- (A) 派生属性
- (B) 多值属性
- (C) 主属性
- (D) 复合属性
- (A) 参与约束
- (B) 参照完整性约束
- (C) 映射约束
- (D) 主键约束
答案与解析
- 试题难度:容易
- 知识点:关系数据库>完整性约束
- 试题答案:[['A'],['B']]
- 试题解析:简单属性:属性是原子的、不可再分的。复合属性:可以细分为更小的部分。例如:职工实体集的通信地址。
单值属性:一个属性对应一个值。
多值属性:一个属性对应多个值。例如:职工实体集的职工的亲属姓名。
NULL属性:表示无意义或不知道(属性没有值或属性值未知时)。
派生属性:可以从其他属性得来。例如:工龄可以从入职时间计算得出。
本题中年龄可以通过出生日期和系统时间计算出来。属于派生属性。
实体完整性:规定基本关系R的主属性A不能取空。
用户自定义完整性:就是针对某一具体关系数据库的约束条件,反映某一具体应用所涉及的数据必须满足的语义要求,由应用的环境决定。如:年龄必须为大于0小于150的整数。
参照完整性/引用完整性:规定,若F是基本关系R的外码,它与基本关系S的主码K,相对应(基本关系R和S不一定是不同的关系),则R中每个元组在F上的值必须为:或者取空值;或者等于S中某个元组的主码值。
本题中购买记录表中每条购买记录对应的客户必须在客户表中存在,应属于参照完整性或引用完整性。
第 49 题
- (A) 空集
- (B) 零值
- (C) 不存在或不知道
- (D) 无穷大
- (A) NULL
- (B) UNKNOWN
- (C) TRUE
- (D) FALSE
答案与解析
- 试题难度:一般
- 知识点:SQL语言>表及相关约束
- 试题答案:[['C'],['C']]
- 试题解析:NULL属性:表示无意义或不知道(属性没有值或属性值未知时)。逻辑运算UNKNOWN OR TRU 由于是逻辑或运算,OR之前非布尔值,结果为FALSE,OR之后为TRUE,所以逻辑运算的结果为TRUE。
第 50 题
- (A) 分区容错性
- (B) 原子性
- (C) 可用性
- (D) 一致性
答案与解析
- 试题难度:一般
- 知识点:数据库发展和新技术>NoSQL
- 试题答案:[['B']]
- 试题解析:CAP理论CAP简单来说:就是对一个分布式系统,一致性(Consistency)、可用性(Availablity)和分区容错性(Partition tolerance)三个特点最多只能三选二。
第 51 题
- (A) 共享内存
- (B) 共享磁盘
- (C) 无共享
- (D) 层次
答案与解析
- 试题难度:一般
- 知识点:数据库发展和新技术>其它
- 试题答案:[['A']]
- 试题解析:并行数据库体系结构并行数据库要求尽可能的并行执行所有的数据库操作,从而在整体上提高数据库系统的性能。根据所在的计算机的处理器(Processor)、内存(Memory)及存储设备(Storage)的相互关系,并行数据库可以归纳为三种基本的体系结构(这也是并行计算的三种基本体系结构),即:
- 共享内存结构(Shared-Memory)、
- 共享磁盘结构(Shared-Disk)
3.无共享资源结构(Shared-Nothing)。
1、共享内存(Shared-Memory)结构
该结构包括多个处理器、一个全局共享的内存(主存储器)和多个磁盘存储,各个处理器通过高速通讯网络(InterconnectionNetwork)与共享内存连接,并均可直接访问系统中的一个、多个或全部的磁盘存储,在系统中,所有的内存和磁盘存储均由多个处理器共享。
(1)提供多个数据库服务的处理器通过全局共享内存来交换消息和数据,通讯效率很高,查询内部和查询间的并行性的实现也均不需要额外的开销;
(2)数据库中的数据存储在多个磁盘存储上,并可以为所有处理器访问;
(3)在数据库软件的编制方面与单处理机的情形区别也不大。
这种结构由于使用了共享的内存,所以可以基于系统的实际负荷来动态地给系统中的各个处理器分配任务,从而可以很好地实现负荷均衡。
2、共享磁盘(Shared-Disk)结构
该结构由多个具有独立内存(主存储器)的处理器和多个磁盘存储构成,各个处理器相互之间没有任何直接的信息和数据的交换,多个处理器和磁盘存储由高速通信网络连接,每个处理器都可以读写全部的磁盘存储。
这种结构常用于实现数据库集群,硬件成本低、可扩充性好、可用性强,且可很容易地从单处理器系统迁移,还可以容易地在多个处理器之间实现负载均衡。
3、无共享资源(Shared-Nothing)结构
该结构由多个完全独立的处理节点构成,每个处理节点具有自己独立的处理器、独立的内存(主存储器)和独立的磁盘存储,多个处理节点在处理器级由高速通信网络连接,系统中的各个处理器使用自己的内存独立地处理自己的数据。
这种结构中,每一个处理节点就是一个小型的数据库系统,多个节点一起构成整个的分布式的并行数据库系统。由于每个处理器使用自己的资源处理自己的数据,不存在内存和磁盘的争用,提高的整体性能。另外这种结构具有优良的可扩展性——只需增加额外的处理节点,就可以以接近线性的比例增加系统的处理能力。
这种结构中,由于数据是各个处理器私有的,因此系统中数据的分布就需要特殊的处理,以尽量保证系统中各个节点的负载基本平衡,但在目前的数据库领域,这个数据分布问题已经有比较合理的解决方案。
由于数据是分布在各个处理节点上的,因此,使用这种结构的并行数据库系统,在扩展时不可避免地会导致数据在整个系统范围内的重分布(Re-Distribution)问题。
第 52 题
- (A) 网状
- (B) 层次
- (C) 关系
- (D) 多维
答案与解析
- 试题难度:一般
- 知识点:数据库技术基础>数据仓库的数据模式
- 试题答案:[['D']]
- 试题解析:数据仓库是面向主题的;操作型数据库的数据组织面向事务处理任务,而数据仓库中的数据是按照一定的主题域进行组织。主题是指用户使用数据仓库进行决策时所关心的重点方面,一个主题通常与多个操作型信息系统相关。主题是与传统数据库的面向应用相对应的,是一个抽象概念,是在较高层次上将企业信息系统中的数据综合、归类并进行分析利用的抽象。每一个主题对应一个宏观的分析领域。数据仓库排除对于决策无用的数据,提供特定主题的简明视图。
因此数据通常是多维数据,包括维属性和量度属性。即数据仓库中的数据组织是基于多维模型的。
第 53 题
- (A) 识别社交网络中的社团结构,即连接稠密的子网络
- (B) 根据现有的客户信息,分析潜在客户
- (C) 分析数据,以确定哪些贷款申请是安全的,哪些是有风险的
- (D) 根据以往病人的特征,对新来的病人进行诊断
- (A) EM
- (B) Apriori
- (C) K-means
- (D) SVM
答案与解析
- 试题难度:一般
- 知识点:数据库技术基础>数据挖掘最常用的技术
- 试题答案:[['A'],['D']]
- 试题解析:分类(classification ):有指导的类别划分,在若干先验标准的指导下进行,效果好坏取决于标准选取的好坏。它找出描述并区分数据类或概念的模型(或函数),以便能够使用模型预测类标记未知的对象类。分类分析在数据挖掘中是一项比较重要的任务,目前在商业上应用最多。识别社交网络中的社团结构,即连接稠密的子网络一般采用社区分析算法CNM。
第 54 题
- (A) 本地 DNS 缓存
- (B) 本机 hosts 文件
- (C) 本地 DNS 服务器
- (D) 根域名服务器
答案与解析
- 试题难度:一般
- 知识点:计算机网络>DNS与DHCP应用
- 试题答案:[['B']]
- 试题解析:域名查询记录:先HOSTS表,再本地DNS缓存,然后再查找本地DNS服务器,再根域名服务器,顶级域名服务器、权限域名服务器。
第 55 题
- (A) Linux 只有一个根目录,用“/root”表示
- (B) Linux 中有多个根目录,用“/”加相应目录名称表示
- (C) Linux 中只有一个根目录,用“/ ”表示
- (D) Linux 中有多个根目录,用相应目录名称表示
答案与解析
- 试题难度:一般
- 知识点:操作系统>绝对路径与相对路径
- 试题答案:[['C']]
- 试题解析:Linux文件系统只有一个根目录,使用“/”表示。
第 56 题
- (A) 10.110.12.0
- (B) 10.110.12.30
- (C) 10.110.12.31
- (D) 10.110.12.32
答案与解析
- 试题难度:一般
- 知识点:计算机网络>IP地址与子网划分
- 试题答案:[['B']]
- 试题解析:子网掩码为255.255.255.224,说明IP地址中有27位表示网络位,剩下5位表示主机位,5位表示主机位,即每个子网一共有25-2=30个可用IP地址,而本题的IP地址的网络号为:10.110.12.0,该网络中的可用IP地址范围是10.110.12.0~10.110.12.31,其中10.110.12.31表示子网广播地址。

第 57 题
- (A) 500b/s
- (B) 700b/s
- (C) 3500b/s
- (D) 5000b/s
答案与解析
- 试题难度:一般
- 知识点:计算机网络>其它
- 试题答案:[['C']]
- 试题解析:由于每个字符能传送7位有效数据位,每秒能传送有效数据位为:500*7b/s=3500b/s
第 58 题
- (A) 静态路由
- (B) 洪泛式
- (C) 随机路由
- (D) 自适应路由
答案与解析
- 试题难度:一般
- 知识点:计算机网络>其它
- 试题答案:[['D']]
- 试题解析:静态路由路由信息是不进行路由信息更新的;动态路由选择算法就是自适应路由选择算法,是依靠当前网络的状态信息进行决策,从而使路由选择结果在一定程度上适应网络拓扑结构和通信量的变化,需要依据网络信息经常更新路由。
随机路由使用前向代理来收集网络中的有限全局信息,即当前结点到其源结点的旅行时间,并以此来更新结点的旅行时间表; 算法根据结点旅行时间表所记录的历史信息和当前的链路状态来共同确定一个邻结点的路由质量,并以此为参考随机路由分组来均衡网络负载。
洪泛(mflood)路由算法是一个简单有效的路由算法,其基本思想是每个节点都是用广播转发收到的数据分组,若收到重复分组则进行丢弃处理。
第 59 题
The beauty of software is in its function, in its internal structure, and in the way in which it is created by a team. To a user, a program with just the right features presented through an intuitive and ( ) interface is beautiful.To a software designer, an internal structure that is partitioned in a simple and intuitive manner, and that minimizes internal coupling is beautiful.To developers and managers, a motivated team of developers making significant progress every week, and producing defect-free code, is beautiful. There is beauty on all these levels.
Our world needs software -- lots of software. Fifty years ago software was something that ran in a few big and expensive machines. Thirty years ago it was something that ran in most companies and industrial settings. Now there is software running in our cell phones, watches, appliances, automobiles, toys, and tools. And need for new and better software never ( ). As our civilization grows and expands,as developing nations build their infrastructures, as developed nations strive to achieve ever greater efficiencies,the need for more and more software ( )to increase. It would be a great shame if, in all that software,there was no beauty.
We know that software can be ugly. We know that it can be hard to use, unreliable, and carelessly structured. We know that there are software systems whose tangled and careless internal structures make them expensive and difficult to change. We know that there are software systems that present their features through an awkward and cumbersome interface.We know that there are software systems that crash and misbehave. These are ( ) systems. Unfortunately, as a profession, software developers tend to create more ugly systems than beautiful ones.
There is a secret at the best software developers know. Beauty is cheaper than ugliness. Beauty is faster than ugliness. A beautiful software system can be built and maintained in less time, and for less money, than an ugly one. Novice software developers don't understand is. They think that they have to do everything fast and quick.They think that beauty is ( ). No! By doing things fast and quick, they make messes that make the software stiff and hard to understand. Beautiful systems are flexible and easy to understand. Building them and maintaining them is a joy. It is ugliness that is impractical.Ugliness will slow you down and make your software expensive and brittle. Beautiful systems cost the least to build and maintain, and are delivered soonest.
- (A) simple
- (B) Hard
- (C) complex
- (D) duplicated
- (A) happens
- (B) Exists
- (C) stops
- (D) starts
- (A) starts
- (B) continues
- (C) appears
- (D) Stops
- (A) practical
- (B) useful
- (C) beautiful
- (D) Ugly
- (A) impractical
- (B) perfect
- (C) time-wasting
- (D) practical
答案与解析
- 试题难度:一般
- 知识点:专业英语>专业英语
- 试题答案:[['A'],['C'],['B'],['D'],['C']]
- 试题解析:软件的优点在于其功能,内部结构以及由团队创建的方式。对于用户来说,通过直观和____界面呈现的正确功能的程序是美丽的。对于软件设计师来说,分割的内部结构是一种简单而直观的方式,最小化内部耦合是美观的。对于开发人员和经理来说,一个积极的开发团队每周都取得重大进展,并且生产无缺陷的代码是美丽的。所有这些级别都有美丽。我们的世界需要大量软件。五十年前,软件是在大多数公司和工业环境中运行的。现在软件存在在我们的手机,手表,电器,汽车,玩具和工具中。并且对新的和更好的软件的需求永远不会。随着我们文明的发展和壮大,随着发展中国家建设基础设施,发达国家努力实现更高的效率,越来越多的软件需求增长。如果在所有的软件中没有美丽的话,这将是一个很大的耻辱。
我们知道软件可能是丑的。我们知道它可能很难使用,不可靠,粗心大意的结构。我们知道有一些软件系统的纠结和粗心的内部结构使得它们变得昂贵和难以改变。我们知道有一些软件系统通过尴尬和繁琐的界面来呈现其功能。我们知道有软件系统崩溃和行为不端。这些都是系统。不幸的是,作为一个专业,软件开发人员倾向于创建丑陋的系统比美丽的系统更多。
这是最好的软件开发者知道的秘密。美丽的比丑陋的更便宜。美丽的比丑陋的更快。一个美丽的软件系统相当于一个丑陋的系统来说,建立和维护要花的时间与金钱会少得多。很多新手软件开发人员不明白这一点。他们认为做每一个事情必须快速,更快速。他们认为美是。没有!通过快速,快速地做事情,他们使软件变得僵硬,难以理解。美观的系统灵活易懂。建立和维护他们是一种快乐。丑陋是不切实际的。丑陋会减慢你的速度,会使你的软件昂贵而脆弱。美观的系统成本最低,建立和维护成本最低,交货时间最短。
A simple(简单) B hard(困难) C complex(复杂) D duplicated(被复制)
A happens(发生) B exists(存在) C stops(停止) D starts(开始)
A starts (开始) B continues(持续) C appears(出现) D stops(停止)
A practical (实用的) B useful(有用的) C beautiful(美丽的) D ugly(丑陋的)
A impractical (不实用的) B perfect(完美的) C time-wasting(浪费时间) D practical(实用的)