201505数据库上午真题
第 1 题
- (A) 2n
- (B) 2n-1
- (C) 2n-1
- (D) 2n-1+1
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>数据的表示
- 试题答案:[['A']]
- 试题解析:本题考查计算机系统基础常识。二进制数据在计算机系统中的表示方法是最基本的专业知识。补码本身是带符号位
的,补码表示的数字中 0 是唯一的,不像原码有 +0 和-0 之分,也就意味着 n 位二进制编码可以表示 2n 个不同的数。
第 2 题
- (A) 内存
- (B) Cache
- (C) 通用寄存器
- (D) 硬盘
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>多级存储体系
- 试题答案:[['C']]
- 试题解析:本题考查计算机系统基础知识。计算机系统中的 CPU 内部对通用寄存器的存取操作是速度最快的,其次是 Cache,内存的存取速度再次,选项中访问速度最慢的就是作为外存的硬盘。它们共同组成分级存储体系来解决存储容量、成本和速度之间的矛盾。
第 3 题
- (A) 全相联映像
- (B) 组相联映像
- (C) 直接映像
- (D) 无法确定的
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>Cache
- 试题答案:[['A']]
- 试题解析:本题考查计算机系统基础知识。Cache 工作时,需要拷贝主存信息到 Cache 中,就需要建立主存地址和 Cache 地址的映射关系。 Cache 的地址映射方法主要有三种,即全相联影像、直接映像和组相联映像。其中全相联方式意味着主存的任意一块可以映像到 Cache 中的任意一块,其特点是块冲突概率低, Cache 空间利用率高,但是相联目录表容量大导致成本高、查表速度慢;直接映像方式是指主存的每一块只能映像到 Cache 的一个特定的块中,整个 Cache 地址与主存地址的低位部分完全相同 ,其特点是硬件简单,不需要相联存储器,访问速度快(无需地址变换),但是 Cache 块冲突概率高导致 Cache 空间利用率很低;组相联方式是对上述两种方式的折中处理,对 Cache 分组,实现组间直接映射,组内全相联,从而获得较低的块冲突概率、较高的块利用率,同时得到较快的速度和较低的成本。
第 4 题
- (A) 从发出中断请求到中断处理结束
- (B) 从中断处理开始到中断处理结束
- (C) CPU分析判断中断请求
- (D) 从发出中断请求到开始进入中断处理程序
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>I/O控制方式
- 试题答案:[['D']]
- 试题解析:中断是指计算机在执行期间,系统内发生任何非寻常的或非预期的急需处理事件,使得CPU暂时中断当前正在执行的程序而转去执行相应的事件处理程序,待处理完毕后又返回原来被中断处继续执行的过程。中断响应时间:就是中断的响应过程的时间,中断的响应过程是当有事件产生,进入中断之前必须先记住当前正在做的事情,然后去处理发生的事情,处理这个过程的时间。
第 5 题
- (A) 40
- (B) 80
- (C) 160
- (D) 200
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>总线系统
- 试题答案:[['C']]
- 试题解析:时钟频率是指同步电路中时钟的基础频率,它以“若干次周期每秒”来度量,量度单位采用SI单位赫兹(Hz)。
时钟频率为200MHz,需要5个时钟周期才传送一次数据,所以在一秒内可以传送200/5=40M次数据。
可传送的数据量为:40M*32bit/8bit=160MB/S
第 6 题
- (A) 最大吞吐率取决于流水线中最慢一段所需的时间
- (B) 如果流水线出现断流,加速比会明显下降
- (C) 要使加速比和效率最大化应该对流水线各级采用相同的运行时间
- (D) 流水线采用异步控制会明显提高其性能
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>流水线技术
- 试题答案:[['D']]
- 试题解析:异步流动是指任务从流水线流出的次序同流入流水线的次序不一样,也称为乱序流动或错序流动。性能会下降。
第 7 题
- (A) ARP
- (B) Telnet
- (C) SSH
- (D) WEP
答案与解析
- 试题难度:一般
- 知识点:信息安全>网络安全协议
- 试题答案:[['C']]
- 试题解析:终端设备与远程站点之间建立安全连接的协议是SSH。 SSH 为Secure Shell 的缩写, 是由 IETF 制定的建立在应用层和传输层基础上的安全协议。 SSH 是专为远程登录会话 和其他网络服务提供安全性的协议。利用SSH 协议可以有效防止远程管理过程中的信息 泄露问题。SSH 最初是 UNIX 上的程序,后来又迅速扩展到其他操作平台。
第 8 题
- (A) 机房安全
- (B) 入侵检测
- (C) 漏洞补丁管理
- (D) 数据库安全
- (A) 机房安全
- (B) 入侵检测
- (C) 漏洞补丁管理
- (D) 数据库安全
答案与解析
- 试题难度:一般
- 知识点:信息安全>系统安全分级
- 试题答案:[['C'],['D']]
- 试题解析:机房安全属于物理安全,入侵检测属于网络安全,漏洞补丁管理属于系统安全,而数据库安全则是应用安全。
第 9 题
- (A) 应由公司
- (B) 应由公司和王某共同
- (C) 应由王某
- (D) 除署名权以外,著作权的其他权利由王某
答案与解析
- 试题难度:容易
- 知识点:法律法规与标准化>知识产权人确定
- 试题答案:[['A']]
- 试题解析:本题考查知识产权的基本知识。依据《中华人民共和国著作权法》第十一条、第十六条规定,职工为完成所在单位的工作任务而创作的作品属于职务作品。职务作品的著作权归属分为两种情况。
①虽是为完成工作任务而为,但非经法人或其他组织主持,不代表其意志创作,也不由其承担责任的职务作品,如教师编写的教材;著作权应由作者享有,但法人或者其他组织有权在其业务范围内优先使用的权利,期限为 2 年。
②由法人或者其他组织主持,代表法人或者其他组织意志创作,并由法人或者其 他组织承担责任的职务作品,如工程设计、产品设计图纸及其说明、计算机软件、地图 等职务作品,以及法律规定或合同约定著作权由法人或非法人单位单独享有的职务作品,作者享有署名权,其他权利由法人或者其他组织享有。
第 10 题
- (A) 甲公司
- (B) 甲、乙公司均
- (C) 乙公司
- (D) 由甲、乙公司协商确定谁
答案与解析
- 试题难度:一般
- 知识点:法律法规与标准化>知识产权人确定
- 试题答案:[['D']]
- 试题解析:
本题考查知识产权的基本知识。
当两个以上的申请人分别就同样的发明创造申请专利的,专利权授给最先申请的人。如果两个以上申请人在同一日分别就同样的发明创造申请专利的,应当在收到专利行政管理部门的通知后自行协商确定申请人。如果协商不成,专利局将驳回所有申请人的申请,即均不授予专利权。 《中华人民共和国专利法》规定:“两个以上的申请人分别就同样的发明创造申请专利的,专利权授予最先申请的人”。 《中华人民共和国专利法实施细则》规定:“同样的发明创造只能被授予一项专利。依照《专利法》第九条的规定,两个以上的申请人在同一日分别就同样的发明创造申请专利的,应当在收到国务院专利行政部门的通知后自行协商确定申请人”。
第 11 题
- (A) 音箱
- (B) 声音编码
- (C) 电缆
- (D) 声音
答案与解析
- 试题难度:一般
- 知识点:多媒体基础>媒体的种类(显示媒体)
- 试题答案:[['D']]
- 试题解析:本题考查多媒体基本知识。感觉媒体指直接作用于人的感觉器官,使人产生直接感觉的媒体,如引起听觉反应的声音,引起视觉反应的图像等。
第 12 题
- (A) 表现媒体
- (B) 传输媒体
- (C) 表示媒体
- (D) 存储媒体
答案与解析
- 试题难度:一般
- 知识点:多媒体基础>媒体的种类(显示媒体)
- 试题答案:[['A']]
- 试题解析:本题考查多媒体基本知识。表现媒体是指进行信息输入和输出的媒体,如键盘、鼠标、话筒,以及显示器、打印机、喇叭等;表示媒体指传输感觉媒体的中介媒体,即用于数据交换的编码,如图像编码、文本编码和声音编码等;传输媒体指传输表示媒体的物理介质,如电缆、光缆、 电磁波等;存储媒体指用于存储表示媒体的物理介质,如硬盘、光盘等。
第 13 题
( )是表示显示器在纵向(列)上具有的像素点数目指标。
- (A) 显示分辨率
- (B) 水平分辨率
- (C) 垂直分辨率
- (D) 显示深度
答案与解析
- 试题难度:容易
- 知识点:多媒体基础>图像数字化
- 试题答案:[['C']]
- 试题解析:本题考查多媒体基本知识。显示分辨率是指显示器上能够显示出的像素点数目,即显示器在横向和纵向上能够显示出的像素点数目。水平分辨率表明显示器水平方向(横向)上显示出的像素点数目,垂直分辨率表明显示器垂直方向(纵向)上显示出的像素点数目。例如,显示分辨率为 1024×768 则表明显示器水平方向上显示 1024 个像素点,垂直方向上显示 768 个像素点, 整个显示屏就含有 786432 个像素点。屏幕能够显示的像素越多,说明显示设备的分辨率越高,显示的图像质量越高。显示深度是指显示器上显示每个像素点颜色的二进制位数。
第 14 题
- (A) 软件系统
- (B) 硬件系统
- (C) 过程
- (D) 人员
答案与解析
- 试题难度:一般
- 知识点:软件工程>其它
- 试题答案:[['C']]
- 试题解析:本题考查软件工程的基本概念。软件工程是一门工程学科,涉及到软件开发的各个方面,从最初的系统描述到交付后的系统维护,都属于其学科范畴。用软件工程方法进行软件开发,涉及到方法、工具和过程等要素。其中,方法是产生某些结果的形式化过程。工具是用更好的方式完成某件事情的设备或自动化系统。过程是把工具和方法结合起来,定义涉及活动、约束和资源使用的一系列步骤,来生产某种想要的输出。
第 15 题
- (A) 概要
- (B) 详细
- (C) 结构化
- (D) 面向对象
答案与解析
- 试题难度:一般
- 知识点:软件工程>软件设计
- 试题答案:[['A']]
- 试题解析:本题考查软件工程的基本概念。软件设计的任务是基于需求分析的结果建立各种设计模型,给出问题的解决方案。从工程管理的角度,可以将软件设计分为两个阶段:概要设计阶段和详细设计阶段。结构化设计方法中,概要设计阶段进行软件体系结构的设计、数据设计和接口设计;详细 设计阶段进行数据结构和算法的设计。面向对象设计方法中,概要设计阶段进行体系结构设计、初步的类设计/数据设计、结构设计;详细设计阶段进行构件设计。
结构化设计和面向对象设计是两种不同的设计方法,结构化设计根据系统的数据流图进行设计,模块体现为函数、过程及子程序;面向对象设计基于面向对象的基本概念进行,模块体现为类、对象和构件等。
第 16 题
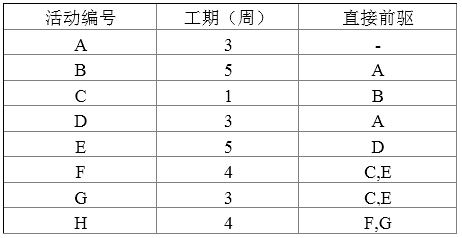
- (A) 16
- (B) 17
- (C) 18
- (D) 19
- (A) A
- (B) B
- (C) D
- (D) F
答案与解析
- 试题难度:一般
- 知识点:项目管理>Gant图与Pert图
- 试题答案:[['D'],['B']]
- 试题解析:本题考查软件项目管理的基础知识。活动图是描述一个项目中各个工作任务相互依赖关系的一种模型,项目的很多重要 特性可以通过分析活动图得到,如估算项目完成时间,计算关键路径和关键活动等。
根据上表给出的数据,构建活动图,如下图所示。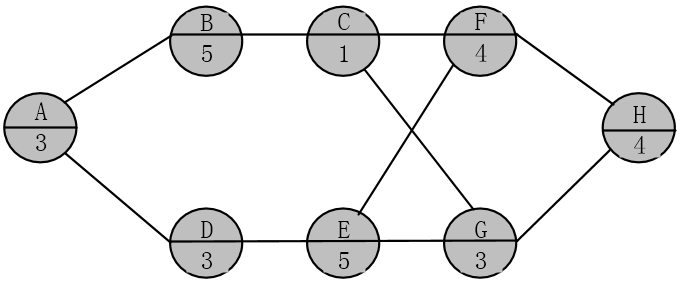
从上图很容易看出,关键路径为 A-D-E-F-H ,其长度为19,关键路径上的活动均为关键活动。
第 17 题
- (A) 风险影响( Risk Impact)
- (B) 风险概率(Risk Probability)
- (C) 风险暴露(Risk Exposure)
- (D) 风险控制(Risk Control)
答案与解析
- 试题难度:一般
- 知识点:项目管理>风险管理
- 试题答案:[['C']]
- 试题解析:本题考查软件项目管理的基础知识。风险是一种具有负面后果的、人们不希望发生的事件。风险管理是软件项目管理的 一项重要任务。在进行风险管理时,根据风险的优先级来确定风险控制策略,而优先级是根据风险暴露来确定的。风险暴露是一种量化风险影响的指标,等于风险影响乘以风险概率。风险影响是当风险发生时造成的损失。风险概率是风险发生的可能性。风险控制是风险管理的一个重要活动。
第 18 题
- (A) 程序设计语言的基本成分包括数据、运算、控制和传输等
- (B) 高级程序设计语言不依赖于具体的机器硬件
- (C) 程序中局部变量的值在运行时不能改变
- (D) 程序中常量的值在运行时不能改变
答案与解析
- 试题难度:一般
- 知识点:程序设计语言>程序语言的基本成分
- 试题答案:[['C']]
- 试题解析:本题考查程序语言基础知识。选项 A 涉及程序语言的一般概念, 程序设计语言的基本成分包括数据、运算、控制和传输等。
选项 B 考查高级语言和低级语言的概念。关于程序设计语言,高级语言和低级语言是指其相对于运行程序的机器的抽象程度。低级语言在形式上越接近机器指令,汇编语言就是与机器指令一一对应的。高级语言对底层操作进行了抽象和封装,其一条语句对应多条机器指令,使编写程序的过程更符合人类的思维习惯,并且极大了简化了人力劳动。高级语言并不依赖于具体的机器硬件。
选项 C 考查局部变量的概念,凡是在函数内部定义的变量都是局部变量(也称作内部变量),包括在函数内部复合语句中定义的变量和函数形参表中说明的形式参数。局部变量只能在函数内部使用,其作用域是从定义位置起至函数体或复合语句体结束为止。 局部变量的值通常在其生存期内是变化的。
选项 D 考查常量的概念,程序中常量的值在运行时是不能改变的。
第 19 题
- (A)
- (B)
- (C)
- (D)
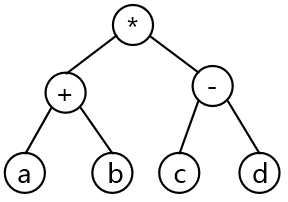
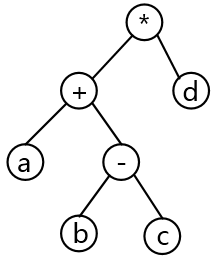
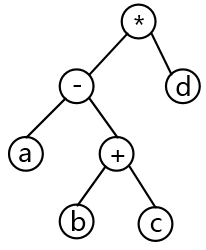
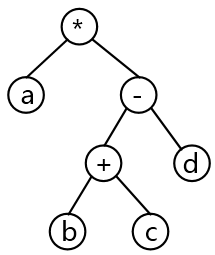
答案与解析
- 试题难度:容易
- 知识点:程序设计语言>后缀表达式
- 试题答案:[['B']]
- 试题解析:本题考查程序语言与数据结构基础知识。对算术表达式 “(a+(b-c))*d” 求值的运算处理顺序是:先进行 b-c;然后与 a 相加, 最后再与 d 相乘。只有选项 B 所示的二叉树与其相符。
第 20 题
- (A) 代码区
- (B) 静态数据区
- (C) 栈区
- (D) 堆区
答案与解析
- 试题难度:一般
- 知识点:程序设计语言>程序语言的基本成分
- 试题答案:[['B']]
- 试题解析:本题考查程序语言基础知识。程序运行时的用户内存空间一般划分为代码区、静态数据区、栈区和堆区,其中栈区和堆区也称为动态数据区。全局变量的存储空间在静态数据区。
第 21 题
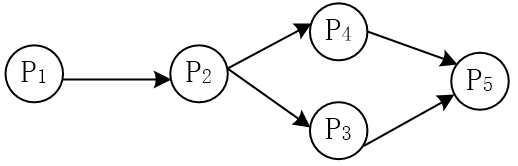
若用PV操作控制进程P1、P2、P3、P4和P5并发执行的过程,则需要设置5个信号量S1、S2、S3、S4和S5,且信号量S1~S5的初值都等于零。下图中a、b和c处应分别填写( );d和e处应分别填写( ),f和g处应分别填写( )。
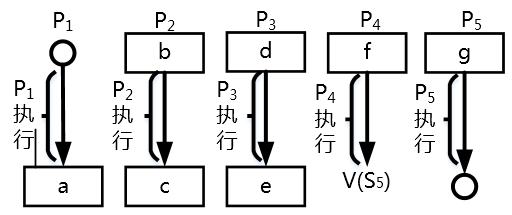
>- (A) V(S1)、P(S1)和V(S2)V(S3) >- (B) P(S1)、V(S1)和V(S2)V(S3) >- (C) V(S1)、V(S2)和P(S1)V(S3) >- (D) P(S1)、V(S2)和V(S1)V(S3) >- (A) V(S2)和P(S4) >- (B) P(S2)和V(S4) >- (C) P(S2)和P(S4) >- (D) V(S2)和V(S4) >- (A) P(S3)和V(S4)V(S5) >- (B) V(S3)和P(S4)P(S5) >- (C) P(S3)和P(S4)P(S5) >- (D) V(S3)和V(S4)V(S5) **答案与解析** - 试题难度:一般 - 知识点:操作系统>信号量与PV操作 - 试题答案:[['A'],['B'],['C']] - 试题解析:
第一空的正确的选项为 A 。根据前驱图,P1进程执行完需要通知P2 进程,故需要利用 V (S1)操作通知 P2 进程,所以空 a 应填 V ( S1); P2进程需要等待 P1进程的结果,故需要利用 P(S1)操作测试 P1进程是否运行完,所以空 b 应填 P (S1);又由于 P2 进程运行结束需要利用 V (S2)、V (S3) 操作分别通知P3、P4进程,所以空 c应填 V (S2)、V (S3)。
第二空的正确的答案为 B。根据前驱图, P3 进程运行前需要等待 P2 进程的结果, 故需执行程序前要先利用 1 个 P 操作,根据排除法可选项只有选项 B 和选项 C。又因为 P3进程运行结束后 需要利用 1 个 V 操作通知P5进程,根据排除法可选项只有选项B 满足要求 。
第三空的正确的答案为 C。根据前驱图,P4进程执行前需要等待 P2 进程的结果,故空 f 处需要 1 个 P 操作; P5 进程执行前需要等待 P3和 P4进程的结果, 故空 g 处需要 2 个 P 操作。根据排除法可选项只有选项 C 能满足要求 。
第 22 题

>- (A) 0 >- (B) 1 >- (C) 2 >- (D) 3 **答案与解析** - 试题难度:一般 - 知识点:操作系统>页面置换算法 - 试题答案:[['D']] - 试题解析:
第 23 题
- (A) 瀑布
- (B) 原型
- (C) 增量
- (D) 螺旋
答案与解析
- 试题难度:一般
- 知识点:软件工程>开发模型
- 试题答案:[['D']]
- 试题解析:本题考查软件过程模型的基础知识。瀑布模型将软件生存周期各个活动规定为线性顺序连接的若干阶段的模型,规定了由前至后,相互衔接的固定次序,如同瀑布流水,逐级下落。这种方法是一种理想的现象开发模式,缺乏灵活性,特别是无法解决软件需求不明确或不准确的问题。螺旋将瀑布模型与快速原型模型结合起来,并且加入两种模型均忽略了的风险分析,适用于复杂的大型软件。
原型模型从初始的原型逐步演化成最终软件产品,特别适用于对软件需求缺乏准确认识的情况。
增量开发是把软件产品作为一系列的增量构件来设计、编码、集成和测试,可以在增量开发过程中逐步理解需求。
第 24 题
- (A) 描述数据对象之间的关系
- (B) 描述对数据的处理流程
- (C) 说明将要出现的逻辑判定
- (D) 指明系统对外部事件的反应
答案与解析
- 试题难度:一般
- 知识点:软件工程>DFD与数据字典
- 试题答案:[['B']]
- 试题解析:本题考查数据流图的概念和应用。数据流图或称数据流程图 (Data Flow Diagram ,DFD) 是一种便于用户理解、分析系统数据流程的图形工具。数据流图描述对数据的处理流程,着重系统信息的流向和处理过程。它摆脱了系统的物理内容,精确地在逻辑上描述系统的功能、输入、输出和数据存储等,是系统逻辑模型的重要组成部分。
第 25 题
- (A) 为HLMP
- (B) 在集合{H,L,M,P}中任选一个
- (C) 在集合{HL,HM,HP,LM,LP,MP}中任选一个
- (D) 在集合{HLM,HLP,HMP,LMP}中任选一个
答案与解析
- 试题难度:一般
- 知识点:关系数据库>关系数据库相关术语
- 试题答案:[['A']]
- 试题解析:本题考查关系数据库系统中键的基本概念。在关系数据库系统中,全码(Al l-key)指关系模型的所有属性组是这个关系模式的候选键,本题所有属性组为HLMP,故本题的正确选项为A。
第 26 题
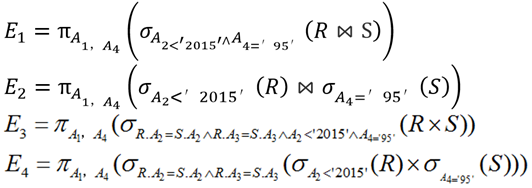
如果严格按照表达式运算顺序,则查询效率最高的是( )。将该查询转换为等价的SQL语句如下:
SELECT A1,A4 FROM R,S
WHERE( );
>- (A) E1 >- (B) E2 >- (C) E3 >- (D) E4 >- (A) R.A2< 2015 OR S.A4=95 >- (B) R.A2< 2015 AND S.A4=95 >- (C) R.A2< 2015 OR S.A4=95 OR R.A2=S.A2 >- (D) R.A2< 2015 AND S.A4=95 AND R.A2=S.A2AND R.A3=S.A3 **答案与解析** - 试题难度:一般 - 知识点:关系数据库>关系表达式优化的原则 - 试题答案:[['B'],['D']] - 试题解析:
本题考查关系代数表达式的等价性问题和查询优化方面的基本知识。
第一空正确的选项为 B 。表达式E2的查询效率最高,因为E2将选取运算σA2 <'2015'(R)和 σA4='80'(S) 移到了叶节点,然后进行自然连接运算。这样满足条件的元组数比先进行笛卡尔积产生的元组数大大下降,甚至无需中间文件,就可将中间结果放在内存,最后在内存即可形成所需结果集。
第二空正确的选项为 D。在关系R( A1,A2,A3 )和 S(A2,A3,A4) 上进行关系运算的 4个等价的表达式中可以看出,
E3 = πA1,A4(σA2<'2015'⊥R.A3⊥A4='95'(R×S))应该先进行 R×S运算,然后在结果集中进行满足条件
" R.A2 <'2015' ⊥S.A4 <'95' ⊥R.A3 = S.A3 "的选取运算σ ,最后再进行属性A1,A4的投影运算 π。可见,选项 D 与条件 " R.A2 <'2015' ⊥S.A4 <'95' ⊥R.A3 = S.A3"等价。
员工(员工代码,姓名,部门代码,联系方式,薪资)
项目(项目编号,项目名称,承担任务)

若部门和员工关系进行自然连接运算,其结果集为( )元关系。由于员工和项目关系之间的联系类型为( ),所以员工和项目之间的联系需要转换成一个独立的关系模式,该关系模式的主键是( )。 >- (A) 5 >- (B) 6 >- (C) 7 >- (D) 8 >- (A) 1对1 >- (B) 1对多 >- (C) 多对1 >- (D) 多对多 >- (A) (项目名称,员工代码) >- (B) (项目编号,员工代码) >- (C) (项目名称,部门代码) >- (D) (项目名称,承担任务) **答案与解析** - 试题难度:容易 - 知识点:数据库技术基础>E-R模型 - 试题答案:[['C'],['D'],['B']] - 试题解析:
本题考查关系数据库 E-R 模型的相关知识。
第一空 的正确答案是 C。根据题意,部门和员工关系进行自然连接运算,应该去掉一个重复属性“部门代码”,所以自然连接运算的结果集为 7 元关系。
第二空的正确答案是 D。在E-R 模型中,用1 1 表示 1 对1联系,用1 *表示 1 对多联系,用* *表示多对多联系。
第三空的正确答案是 B。因为员工和项目之间是一个多对多的联系,多对多联系的向关系模式转换的规则是:多对多联系只能转换成一个独立的关系模式,关系模式的名称取联系的名称,关系模式的属性取该联系所关联的两个多方实体的主键及联系的属性,关系的码是多方实体的主键构成的属性组 。由于员工关系的主键是员工代码,项目关系的主键是项目编号,因此,根据该转换规则(第三空)员工和项目之间的联系的关系模式的主键是(员工代码,项目编号)。
第 28 题
给定关系模式R(A1,A2,A3,A4),R上的函数依赖集F= {A1A3→A2,A2→A3},R( )。若将R分解为ρ={(A1,A2,A4),(A1,A3)},那么该分解是( )的。
- (A) 有一个候选关键字 A1A3
- (B) 有一个候选关键字 A1A2A3
- (C) 有二个候选关键字A1A3A4和A1A2A4
- (D) 有三个候选关键字A1A2、A1A3和A1A4
- (A) 无损联接
- (B) 无损联接且保持函数依赖
- (C) 保持函数依赖
- (D) 有损联接且不保持函数依赖
答案与解析
- 试题难度:一般
- 知识点:关系数据库>模式分解
- 试题答案:[['C'],['D']]
- 试题解析:
本题考查关系数据库规范化理论方面的基础知识。
第一空正确答案为 C,第二空 正确答案为 D。A1A3→A2 ,A2 →A3,没有出现 A4 ,所以候选关键字中肯定包含A4,属性 A1A3A4 决定全属性,故为候选关键字。同理 A1A3A4 也为候选关键字。
设 U1= {A1,A2 ,A4} ,U2 = {A1,A3} ,那么可得出: (U1∩U2) →(U1-U2) = A1→A2 ,(U1∩U2) → (U2-U1) =A1→A3 而 A1 →A2,A1→ A3 ∉F+ ,所以分解 ρ 是有损连接的。
又因为 F1=F2= φ, F+≠ (F1UF2)+ ,所以分解不保持函数依赖。
第 29 题
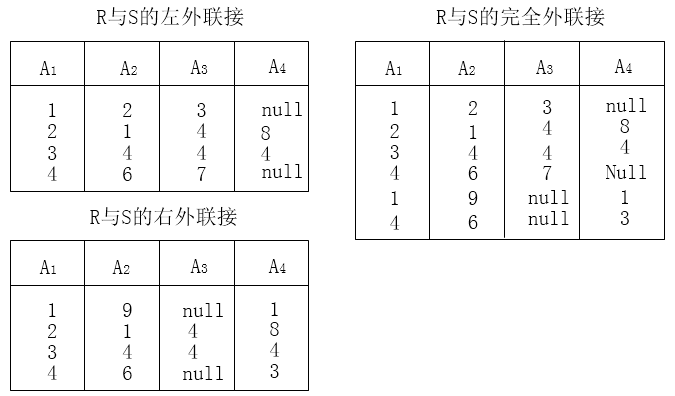
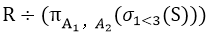 的结果为( ),R、S的左外连接、右外连接和完全外连接的元组个数分别为( )。
的结果为( ),R、S的左外连接、右外连接和完全外连接的元组个数分别为( )。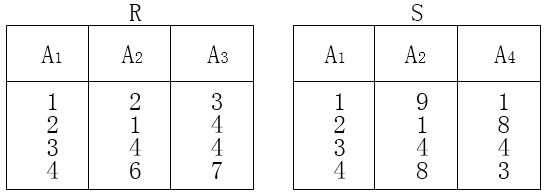
>- (A) {4} >- (B) {3,4} >- (C) {3,4,7} >- (D) {(1,2),(2,1),(3,4), (4,7)} >- (A) 2,2,4 >- (B) 2,2,6 >- (C) 4,4,4 >- (D) 4,4,6 **答案与解析** - 试题难度:一般 - 知识点:关系数据库>关系代数运算 - 试题答案:[['A'],['D']] - 试题解析:
R÷S= {tr I tr ∈ R ∧ts[Y]⊆Yx}
其中:Yx为 x 在 R 的象集, x=tr[X], 且 R÷S 的结果集的属性组为 X 。
根据除法定义,试题 X 属性为 A3,Y 属性为 (A1,A2) , R÷S 应当满足元组在 X 上的分量值 x 的象集Yx包含 S 在 Y 上投影的集合,所以结果集的属性为 A3 。 属性 A3可以取 3 个值 {3,4,7},其中:3 的象集为{(1,2)}, 4的象集为 {(2,1),(3,4)},7 的象集为 {(4,6)}。
根据除法定义,本题关系 S 为 πA1, A2 (σ1<3(S)) ,在属性组Y(A1,A2) 上的投影为{(2,1),(3,4)}如下表所示:
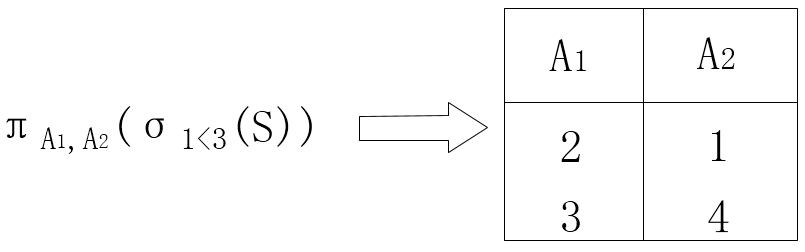
第二空的正确结果为 D。两个关系R 和 S 进行自然连接时,选择两个关系 R 和S 公共属性上相等的元组,去掉重复的属性列构成新关系。在这种情况下,关系R 中的某些元组有可能在关系 S 中不存在公共属性值上相等的元组,造成关系 R 中这些元组的值在运算时舍弃了;同样关系 S 中的某些元组也可能舍弃。为此,扩充了关系运算左外联接、右外联接和完全外联接。
右外联接是指 R 与S 进行自然连接时,只把 S 中舍弃的元组放到新关系中。
完全外联接是指 R 与S 进行自然连接时,把 R 和 S 中舍弃的元组都放到新关系中 。
第二空R 与S的左外联接、右外联接和完全外联接的结果如下表所示:
从运算的结果可以看出 R 与 S 的左外联接、右外联接和完全外联接的元组个数分别为 4,4,6。
### 第 30 题
- (A) 关联分析
- (B) 序列模式分析
- (C) 分类分析
- (D) 聚类分析
答案与解析
- 试题难度:一般
- 知识点:数据库技术基础>数据挖掘最常用的技术
- 试题答案:[['C']]
- 试题解析:
本题考查数据挖掘基础知识。
数据挖掘就是应用一系列技术从大型数据库或数据仓库中提取人们感兴趣的信息和知识,这些知识或信息是隐含的,事先未知而潜在有用的,提取的知识表示为概念、 规则、规律、模式等形式。也可以说,数据挖掘是一类深层次的数据分析。无论采用哪种技术完成数据挖掘,从功能上可以将数据挖掘的分析方法划分为四种,即关联分析、序列模式分析、分类分析和聚类分析。
①关联分析( Associations ) :目的是为了挖掘出隐藏在数据间的相互关系。若设R={A1 ,A2,…,AP}为 {0,1}域上的属性集, r 为 R 上的一个关系,关于 r 的关联规则表示为X→B,其中X∈R, B∈R,且x∩B=Ø。关联规则的矩阵形式为:矩阵 r 中,如果在行X 的每一列为 1,则行B 中各列趋向于为 1。在进行关联分析的同时还需要计算两个参数,最小置信度( Confidence )和最小支持度 (Support) 。前者用以过滤掉可能性过小的规则,后者则用来表示这种规则发生的概率,即可信度。
②序列模式分析(Sequential Patterns): 目的也是为了挖掘出数据之间的联系,但它的侧重点在于分析数据间的前后关系(因果关系)。例如,将序列模式分析运用于商业, 经过分析,商家可以根据分析结果发现客户潜在的购物模式,发现顾客在购买一种商品的同时经常购买另一种商品的可能性。在进行序列模式分析时也应计算置信度和支持度。
③分类分析( Classifiers ) :首先为每一个记录赋予一个标记(一组具有不同特征的类别),即按标记分类记录,然后检查这些标定的记录,描述出这些记录的特征。这些描述可能是显式的,如一组规则定义;也可能是隐式的,如一个数学模型或公式。
④聚类分析( Clustering) :聚类分析法是分类分析法的逆过程,它的输入集是一组未标定的记录,即输入的记录没有作任何处理。目的是根据一定的规则,合理地划分记录集合,并用显式或隐式的方法描述不同的类剔。
在实际应用的 DM 系统中,上述四种分析方法有着不同的适用范围,因此经常被综合运用。
第 31 题
CREATE TABLE R(住院号CHAR(8) ( ),
姓名CHAR(10),
性别CHAR(1) ( ),
科室号CHAR(4),
病房CHAR(4),
家庭住址ADDR, //ADDR为用户定义的类
( ) );
b.表R中复合属性是( )。 >- (A) PRIMARY KEY >- (B) REFERENCES D(科室号) >- (C) NOT NULL >- (D) REFERENCES D(科室名) >- (A) IN(M,F) >- (B) CHECK('M','F') >- (C) LIKE('M','F') >- (D) CHECK(性别IN('M','F')) >- (A) PRIMARY KEY(科室号)NOT NULL UNIQUE >- (B) PRIMARY KEY(科室名)UNIQUE >- (C) FOREIGN KEY(科室号)REFERENCES D(科室号) >- (D) FOREIGN KEY(科室号)REFERENCES D(科室名) >- (A) 住院号 >- (B) 姓名 >- (C) 病房 >- (D) 家庭住址 **答案与解析** - 试题难度:容易 - 知识点:SQL语言>表及相关约束 - 试题答案:[['A'],['D'],['C'],['D']] - 试题解析:
第二空的正确答案是 D。根据题意,属性"性别"的取值只能为M 或 F ,因此需要用语句 "CHECK(性别 IN ('M','F')"进行完整性约束。
第三空的正确答案是 C。根据题意。属性"科室号"是外键,因此需要用语句"REFERENCES D(科室号)"进行参考完整性约束。
第四空的正确答案是 D。简单属性是原子的、不可再分的,复合属性可以细分为更小的部分(即划分为别的属性)。试题中"家庭住址"属性可以进一步分为邮编、省、市、街道,故属于复合属性。
### 第 32 题
数据字典中“数据项”的内容包括:名称、编号、取值范围、长度和( )。
>- (A) 处理频率 >- (B) 最大记录数 >- (C) 数据类型 >- (D) 数据流量 **答案与解析** - 试题难度:容易 - 知识点:软件工程>DFD与数据字典 - 试题答案:[['C']] - 试题解析:### 第 33 题
 和
和 ,两个事务都要对数据
,两个事务都要对数据 和
和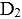 进行操作。若
对
进行操作。若
对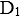 已加排它锁,
对
已加排它锁,
对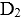 已加共享锁;那么
已加共享锁;那么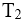 对
对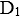 ( ),那么
( ),那么 对
对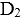 ( )。
( )。
- (A) 加共享锁成功,加排它锁失败
- (B) 加共享锁、加排它锁都失败
- (C) 加共享锁、加排它锁都成功
- (D) 加排它锁成功,加共享锁失败
- (A) 加共享锁成功,加排它锁失败
- (B) 加共享锁、加排它锁都失败
- (C) 加共享锁、加排它锁都成功
- (D) 加排它锁成功,加共享锁失败
答案与解析
- 试题难度:容易
- 知识点:事务管理>封锁协议
- 试题答案:[['B'],['A']]
- 试题解析:本题考查数据库事务处理方面的基础知识。并发事务如果对数据读写时不加以控制,会破坏事务的隔离性和一致性。控制的手段就是加锁,在事务执行时限制其他事务对数据的读取。在并发控制中引入两种锁:排它锁 (Exclusive Locks,简称X 锁)和共享锁( Share Locks,简称S 锁)。
排它锁又称为写锁,用于对数据进行写操作时进行锁定。如果事务 T 对数据 A 加上X 锁后,就只允许事务 T 读取和修改数据 A ,其他事务对数据A 不能再加任何锁,从而 也不能读取和修改数据 A ,直到事务T 释放 A 上的锁。
共享锁又称为读锁,用于对数据进行读操作时进行锁定。如果事务 T 对数据 A 加上 了 S 锁后,事务 T 就只能读数据 A 但不可以修改,其他事务可以再对数据 A 加 S 锁来读取,只要数据 A 上有 S 锁,任何事务都只能再对其加 S 锁读取而不能加 X 锁修改。
第 34 题
- (A) 主码
- (B) 关系
- (C) 数据模型
- (D) 概念模型
- (A) 索引
- (B) 触发器
- (C) 存储过程
- (D) 函数
答案与解析
- 试题难度:容易
- 知识点:数据库设计>物理结构设计
- 试题答案:[['B'],['A']]
- 试题解析:本题考查数据模型的基础知识。概念模型是信息的描述方式,逻辑模型是数据的逻辑结构,数据模型是指数据的物理组织方式。逻辑模型(E-R 图)中的联系描述的是实体间的关联关系,主要是现实世界中的事件,包括参与者和事件自身的属性。在关系模型中,取参与联系的实体的码(唯一代表具体的参与者)和事件自身的属性,构成记录即以关系的形式来描述。
索引是为提高查询效率而引入的机制。通过对查询项建立索引表(包含查找项和指针,其中查找项进行排序或散列),可以通过查询条件先在索引表中进行查找(因为查找项有序,效率高),再根据指针项准确定位记录所在的页面进行读取,而无须进行大量的 I/O操作读取所有记录。
第 35 题
- (A) DBMS
- (B) DBA
- (C) DataBase
- (D) DBS
- (A) 客户机
- (B) DB服务器
- (C) Web服务器
- (D) 数据库
- (A) 客户机
- (B) DB服务器
- (C) Web服务器
- (D) 数据库
答案与解析
- 试题难度:一般
- 知识点:数据库发展和新技术>WEB与数据库
- 试题答案:[['A'],['A'],['C']]
- 试题解析:本题考查数据库应用系统的基础知识。数据库的运行维护是由专门的数据库管理系统软件(DBMS)来负责的。 C/S 结构又称两层结构,由客户端运行应用程序;B/S 结构分为三层,客户端只需要浏览器显示和简单的界面处理,Web服务器上的应用程序负责业务处理并与数据库交互。
第 36 题
- (A) REVOKE UPDATE(XH) ON STUD TOZHAO
- (B) REVOKE UPDATE(XH) ON STUD TO PUBLIC
- (C) REVOKE UPDATE(XH) ON STUD FROM ZHAO
- (D) REVOKE UPDATE(XH) ON STUD FROM PUBLIC
答案与解析
- 试题难度:容易
- 知识点:SQL语言>授权语句
- 试题答案:[['C']]
- 试题解析:本题考查数据库安全中的授权知识。标准 SQL 中的权限收回语法为:
REVOKE 〈权限〉
[ ,<权限>... ]
ON [<对象类型>] <对象名>
FROM <用户>[,<用户>... ];
其中属性列的修改权限用 UPDATE(< 列名>)来表达; PUBLIC 表示所有用户。
第 37 题
- (A) END WORK和ROLLBACK WORK
- (B) COMMIT WORK和ROLLBACK WORK
- (C) SAVE WORK和ROLLUP WORK
- (D) COMMITWORK和ROLLUP WORK
答案与解析
- 试题难度:容易
- 知识点:事务管理>事务的状态
- 试题答案:[['B']]
- 试题解析:本题考查事务程序的基础知识。事物的结束语句是 ROLLBACK 和 COMMIT。当事务执行中出错时,使用 ROLLBACK对当前事务对数据库已做的更新进行撤销:事务所有指令执行完成后,用 COMMIT 语句对数据库所做的更新进行提交 。COMMIT WORK 和 ROLLBACK WORK 中的 WORK 可省略。
第 38 题

>- (A) 满足两段锁协议、不发生死锁 >- (B) 满足两段锁协议、会发生死锁 >- (C) 不满足两段锁协议、不发生死锁 >- (D) 不满足两段锁协议、会产生死锁 >- (A) T1 >- (B) T2 >- (C) T1和T2 >- (D) T1或T2 **答案与解析** - 试题难度:一般 - 知识点:事务管理>两段锁协议 - 试题答案:[['B'],['B']] - 试题解析:
2PL 协议不能避免死锁。图中事务 T1 先对数据项 B 加了独占锁,事务T2先对数据 A 加了共享锁;随后事务T2 申请数据项 B 上的共享锁,只能等待事务T1释放 B 上的独占锁:事务T1 申请数据项 A 上的独占锁,只能等待事务T2 释放 A 上的共享锁。两个事务相互等待造成死锁。
死锁的解除由 DBMS 来完成。需要在造成死锁的多个事务中选择一个回滚代价最小的事务进行强制回滚,并将该事务置于事务队列中稍后执行。图中事务 T1 对数据 B 已经做了修改,事务T2只是读取了数据 A ,相对而言,回滚事务T2 代价最小。
### 第 39 题
- (A) 原子性
- (B) 一致性
- (C) 隔离性
- (D) 持久性
- (A) 镜像
- (B) 数据库备份
- (C) 日志
- (D) 两段锁协议
答案与解析
- 试题难度:一般
- 知识点:事务管理>事务的特性
- 试题答案:[['D'],['C']]
- 试题解析:本题考查数据库恢复的基础知识。数据库故障会造成数据的不 一致。数据库的更新是由事务驱动的,事务的 ACID 属 性被破坏是数据不一致的根本原因 。系统重启会使内存中更新过的数据未写入硬盘而丢 失,破坏了事务的持久性,即事务一经提交,其对数据库的影响会体现到数据库中。
为保证事务发生故障后可恢复, DBMS 使用日志。即在对数据更新前,先将欲做的 修改在日志中记录并写入硬盘,然后再进行数据更新。当系统重启肘,根据日志文件对数据进行恢复。
第 40 题
- (A) AB、AC
- (B) AB、AD
- (C) AC、AD
- (D) AB、AC、AD
- (A) 1NF
- (B) 2NF
- (C) 3NF
- (D) BCNF
答案与解析
- 试题难度:一般
- 知识点:关系数据库>规范化的基础概念
- 试题答案:[['D'],['C']]
- 试题解析:
本题考查关系理论的基础知识。
根据候选码求解算法,求解该关系模式的码:
①必然出现在候选码中的属性为 A;不出现在候选码中的属性为 E; 待考查的属性为 BCD;
② (A)+=A,不包含全部属性,不是候选码;
③ (AB) + = ABDEC 包含全部属性,是候选码;
(AC)+ = ACEDB 包含全部属性,是候选码;
(AD) + = ADBCE 包含全部属性,是候选码。
故 R 的候选码为 {AB、AC 、AD} 。
根据候选码的求解结果,关系R的非主属性为 E。三个候选码中,任何一个候选码中的属性去掉后,即(A)+=A ,(B)+ =BCD ,(C)+=CD,(D)+=D ,都不能决定E ,故不存在非主属性 E 对码的部分依赖,关系 R 属于 2NF。除了三个候选码决定E 之外,没有哪个属性集决定 E,即E 直接依赖于码,关系 R 属于 3NF。存在函数据依赖B→C ,左边不是码,故关系 R 不属于 BCNF 。因此,关系R 属于 3NF。
第 41 题
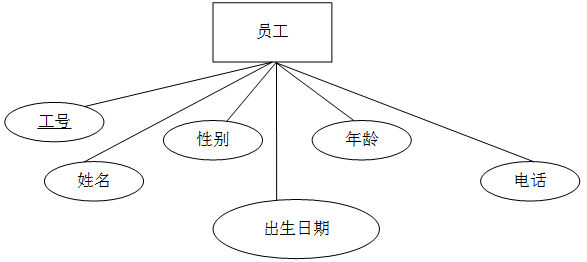
>- (A) 出生日期 >- (B) 年龄 >- (C) 电话 >- (D) 工号 >- (A) 员工(工号,姓名,性别,出生日期,年龄。电话) >- (B) 员工(工号,姓名,性别,出生日期,电话) >- (C) 员工(工号,姓名,性别,出生日期,年龄) 员工电话(工号,电话) >- (D) 员工(工号,姓名,性别,出生日期) 员工电话(工号,电话) **答案与解析** - 试题难度:一般 - 知识点:数据库技术基础>E-R模型 - 试题答案:[['B'],['D']] - 试题解析:
根据扩展 E-R 图的转换规则,派生属性在转换过程中丢弃,多值属性与实体的标识符独立转换成一个关系模式,该关系模式属于4NF 。其他属性构成的关系模式属于 BCNF ,无多值依赖,也属于4NF 。
### 第 42 题
- (A) 类是一组具有相同或相似性质的对象的抽象。一个对象是某一类的一个实例
- (B) 类的属性可以是基本类,如整数、字符串等,也可以是包含属性和方法的一般类
- (C) 类的某个属性的定义可以是该类自身
- (D) 一个对象通常对应实际领域的一个实体,有唯一的标识,即对象标识OID,用户可以修改OID
答案与解析
- 试题难度:一般
- 知识点:数据库发展和新技术>面向对象数据模型
- 试题答案:[['D']]
- 试题解析:本题考查面向对象数据库的基础知识。面向对象数据库中的数据模型充分利用了面向对象的核心概念,选项 A、B 和 C 是对类和对象的概念叙述,是正确的。而 D 选项中,一个对象通常对应实际领域的一个实体,有唯一的标识,即对象标识 OID。但是对用户而言, OID不可以修改的。
第 43 题
- (A) 键值
- (B) 文档
- (C) 图形
- (D) XML
答案与解析
- 试题难度:一般
- 知识点:数据库发展和新技术>NoSQL
- 试题答案:[['B']]
- 试题解析:本题考查 NoSQL 的相关知识。NoSQL 是指非关系型数据库,是对不同于传统的关系型数据库 DBMS 的统称。有几种典型的 NoSQL 数据库。
文档存储数据库是以文档为存储信息的基本单位,如 BaseX ,CouchDB ,MongoDB等。
键值存储数据库支持简单的键值存储和提取,具有极高的并发读写性能,如Dynamo ,Memcached ,Redis等。
图形存储数据库利用计算机将点、线、面等图形基本元素按照一定的数据结构进行存储,如 FlockDB 、Ne04j 等。
多值数据库系统是一种分布式数据库系统,提供了一个通用的数据集成与访问平台,屏蔽了各种数据库系统不同的访问方法和用户界面,给用户呈现出一个访问多种数据库的公共接口。
第 44 题
- (A) C4.5
- (B) Apriori
- (C) K-means
- (D) EM
答案与解析
- 试题难度:一般
- 知识点:数据库技术基础>数据挖掘最常用的技术
- 试题答案:[['A']]
- 试题解析:本题考查数据挖掘的基础知识。基于历史数据预测新数据所属的类型,类型已知(患心脏病/没有患心脏病),这是一个典型的分类问题。在四个选项中,C4.5是一个分类算法, Apriori 是一个关联规则挖掘算法, K-means 和 EM 都是聚类算法,因此正确选项为 A。
第 45 题
- (A) K-Means和DBSCAN的聚类结果与输入参数有很大的关系
- (B) K-Means基于距离的概念而DBSCAN基于密度的概念进行聚类分析
- (C) K-Means很难处理非球形的簇和不同大小的簇,DBSCAN可以处理不同大小和不同形状的簇
- (D) 当簇的密度变化较大时,DBSCAN不能很好的处理,而K-Means则可以
答案与解析
- 试题难度:一般
- 知识点:数据库技术基础>数据挖掘最常用的技术
- 试题答案:[['D']]
- 试题解析:本题考查数据挖掘的基础知识。K-Means 和 DBSCAN 是两个经典的聚类算法,将相似的数据对象归类一组,不相似的数据对象分开。 K-means 算法基于对象之间的聚类进行聚类,需要输入聚类的个数。 DBSCAN 算法基于密度进行聚类,需要确定阈值,两者的聚类结果均与输入参数关系很大。 DBSCAN 可以处理不同大小和不同形状的簇,而 K-means 算法则不适合。若数据分布密度变化大,则这两种算法都不适用。
第 46 题

>- (A) 服务器A的IP地址是广播地址 >- (B) 工作站B的IP地址是网络地址 >- (C) 工作站B与网关不属于同一子网 >- (D) 服务器A与网关不属于同一子网 **答案与解析** - 试题难度:一般 - 知识点:计算机网络>IP地址与子网划分 - 试题答案:[['D']] - 试题解析:
工作站 B 的 IP 地址 131.1.123.43/27: 10000011.00000001.01111011.00101011 这个地址不是网络地址。
工作站 B 的网关地址 131.1.123.33: 10000011.00000001.01111011.00100001 工作站 B与网关属于同一个子网。 ### 第 47 题
- (A) 允许逻辑地划分网段
- (B) 减少了冲突域的数量
- (C) 增加了冲突域的大小
- (D) 减少了广播域的数量
答案与解析
- 试题难度:一般
- 知识点:计算机网络>其它
- 试题答案:[['A']]
- 试题解析:把局域网划分成多个不同的 VLAN ,使得网络接入不再局限于物理位 置的约束,这样就简化了在网络中增加、移除和移动主机的操作,特别是动态配置的 VLAN ,无论主机在哪里,它都处于自己的 VLAN 中。VLAN 内部可以相互通信 ,VLAN 之间不能直接通信,必须经过特殊设置的路由器才可以连通。这样做的结果是,通过在较大的局域网中创建不同的 VLAN ,可以抵御广播风暴的影响,也可以通过设置防火墙来提高网络的安全性。VLAN 并不能直接增强网络的安全性。
第 48 题
- (A) 使用www.abc.com和abc.com打开的是同一页面
- (B) 在地址栏中输入www.abc.com默认使用http协议
- (C) www.abc.com中的“www”是主机名
- (D) www.abc.com中的“abc.com”是域名
答案与解析
- 试题难度:一般
- 知识点:计算机网络>URL
- 试题答案:[['A']]
- 试题解析:本题考查 URL 的基本知识。URL 由三部分组成:资源类型、存放资源的主机域名、资源文件名。
URL 的一般语法格式为(带方括号[ ]的为可选项):
Protocol :// hostname[:port] / path /filename
第 49 题
- (A) WINS名字解析
- (B) 静态地址分配
- (C) DNS名字登录
- (D) 自动分配IP地址
- (A) TCP
- (B) IP
- (C) UDP
- (D) HDLC
答案与解析
- 试题难度:一般
- 知识点:计算机网络>TCP/IP协议族
- 试题答案:[['D'],['A']]
- 试题解析:本题考查 DHCP 和 FTP 两个应用协议。DHCP 协议的功能是自动分配IP地址; FTP 协议的作用是文件传输,使用的传输层协议为 TCP。
第 50 题
Second, the documents will communicate the decisions to others. The manager will be continually amazed that policies he took for common knowledge are totally unknown by some member of his team. Since his fundamental job is to keep everybody going in the ( ) direction, his chief daily task will be communication, not decision-making, and his documents will be immensely ( ) this load.
Finally, a manager's documents give him a data base and checklist. By reviewing them ( ) he sees where he is, and he sees what changes of emphasis or shifts in direction are needed.
The task of the manager is to develop a plan and then to realize it. But only the written plan is precise and communicable. Such a plan consists of documents on what, when, how much, where, and who. This small set of critical documents ( ) much of the manager's work. If their comprehensive and critical nature is recognized in the beginning, the manager can approach them as friendly tools rather than annoying busywork. He will set his direction much more crisply and quickly by doing so.
- (A) inconsistencies
- (B) consistencies
- (C) steadiness
- (D) adaptability
- (A) other
- (B) different
- (C) another
- (D) same
- (A) extend
- (B) broaden
- (C) lighten
- (D) release
- (A) periodically
- (B) occasionally
- (C) infrequently
- (D) rarely
- (A) decides
- (B) encapsulates
- (C) realizes
- (D) recognizes
答案与解析
- 试题难度:较难
- 知识点:专业英语>专业英语
- 试题答案:[['A'],['D'],['C'],['A'],['B']]
- 试题解析:参考译文:为什么要有正式的文档?
首先,书面记录决策是必要的。只有记录下来,分歧才会明朗,矛盾才会突出。书写这项活动需要上百次的细小决定,正是由于它们的存在,人们才能从令人迷惑的现象 中得到清晰、确定的策略。
第二,文档能够作为同其他人的沟通渠道。项目经理常常会不断发现,许多理应被 普遍认同的策略,完全不为团队的一些成员所知。正因为项目经理的基本职责是使每个 人都向着相同的方向前进,所以他的主要工作是沟通,而不是作出决定。这些文档能极 大地减轻他的负担。
最后,项目经理的文档可以作为数据基础和检查列表。通过周期性的回顾,他能清楚项目所处的状态,以及哪些需要重点进行更改和调整。
项目经理的任务是制订计划,并根据计划实现。但是只有书面计划是精确和可以沟通的。计划中包括了时间、地点、人物、做什么、资金。这些少量的关键文档封装了一些项目经理的工作。如果一开始就认识到它们的普遍性和重要性,那么就可以将文档作 为工具友好地利用起来,而不会让它成为令人厌烦的繁重任务。通过遵循文档开展工作, 项目经理能更清晰和快速地设定自己的方向。