201205数据库上午真题
第 1 题
位于CPU与主存之间的高速缓冲存储器Cache用于存放部分主存数据的拷贝,主存地址与Cache地址之间的转换工作由( )完成。
- (A) 硬件
- (B) 软件
- (C) 用户
- (D) 程序员
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>Cache
- 试题答案:[['A']]
- 试题解析:
本题考查高速缓冲存储器(Cache)的工作特点。提供“高速缓存”的目的是为了让数据存取的速度适应CPU的处理速度,其基于的原理是内存中“程序执行与数据访问的局部性行为”,即一定程序执行时间和空间内,被访问的代码集中于一部分。为了充分发挥高速缓存的作用,不仅依靠“暂存刚刚访问过的数据”,还要使用硬件实现的指令预测与数据预取技术,即尽可能把将要使用的数据预先从内存中取到高速缓存中。一般而言,主存使用DRAM技术,而Cache使用昂贵但较快速的SRAM技术。目前微计算机上使用的AMD或INTEL微处理器都在芯片内部集成了大小不等的数据高速缓存和指令高速缓存,通称为L1 高速缓存(L1 Cache,即第一级片上高速缓冲存储器);而比L1 容量更大的L2 高速缓存曾经被放在CPU外部(主板或者CPU接口卡上),但是现在已经成为CPU内部的标准组件;更昂贵的顶级家用和工作站CPU 甚至会配备比L2 高速缓存还要大的L3 高速缓存。
第 2 题
内存单元按字节编址,地址0000A000H~0000BFFFH共有( )个存储单元。
- (A) 8192K
- (B) 1024K
- (C) 13K
- (D) 8K
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>数据的表示
- 试题答案:[['D']]
- 试题解析:
本题考查存储器的地址计算知识。
每个地址编号为一个存储单元(容量为1个字节),地址区间0000A000H~0000BFFFH共有1FFF+1个地址编号(即213),1K=1024=210,因此该地址区间的存储单元数也就是8K。
第 3 题
相联存储器按( )访问。
- (A) 地址
- (B) 先入后出的方式
- (C) 内容
- (D) 先入先出的方式
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>多级存储体系
- 试题答案:[[C]]
- 试题解析:
本题考查相联存储器的概念。
相联存储器是一种按内容访问的存储器,其工作原理就是把数据和数据的某一部分作为关键字,将该关键字与存储器中的每一单元进行比较,找出存储器中所有与关键字相同的数据字。
相联存储器可用在高速缓冲存储器中;在虚拟存储器中用来作段表、页表或快表存储器;还用在数据库和知识库中。
第 4 题
若CPU要执行的指令为:MOV R1,#45(即将数值45传送到寄存器R1中),则该指令中采用的寻址方式为( )。
- (A) 直接寻址和立即寻址
- (B) 寄存器寻址和立即寻址
- (C) 相对寻址和直接寻址
- (D) 寄存器间接寻址和直接寻址
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>寻址方式
- 试题答案:[['B']]
- 试题解析:
本题考查指令系统基础知识。
指令中的寻址方式就是如何对指令中的地址字段进行解释,以获得操作数的方法或获得程序转移地址的方法。常用的寻址方式有:
立即寻址:操作数就包含在指令中。
直接寻址:操作数存放在内存单元中,指令中直接给出操作数所在的存储单元的地址。
寄存器寻址:操作数存放在某一寄存器中,指令中给出存放操作数所在的寄存器名。
寄存器间接寻址:操作数存放在内存单元中,操作数所在存储单元的地址在某个寄存器中。
间接寻址:指令中给出操作数地址的地址。
相对寻址:指令地址码给出的是一个偏移量(可正可负),操作数地址等于本条指令的地址加上该偏移量。
变址寻址:操作数地址等于变址寄存器的内容加偏移量。
题目给出的指令中,R1是寄存器,属于寄存器寻址方式,45是立即数,属于立即寻址方式。
第 5 题
一条指令的执行过程可以分解为取指、分析和执行三步,在取指时间t取指=3△t、分析时间t分析=2△t、执行时间t执行=4△t的情况下,若按串行方式执行,则10条指令全部执行完需要( )△t。若按照流水方式执行,则执行完10条指令需要=( )△t。
- (A) 40
- (B) 70
- (C) 90
- (D) 100
- (A) 20
- (B) 30
- (C) 40
- (D) 45
答案与解析
- 试题难度:容易
- 知识点:计算机组成与体系结构>流水线技术
- 试题答案:[['C'],['D']]
- 试题解析:
本题考查指令执行的流水化概念
根据题目中给出的数据,每一条指令的执行过程需要9△t。在串行执行方式下,执行完一条指令后才开始执行下一条指令,10条指令共耗时90△t。若按照流水线 方式执行,则在第i+2条指令处于执行阶段时,就可以分析第i+1条指令,同时取第i条指令。由于指令的执行阶段所需时间最长(为4△t),因此,指令开始流水执行后,每4△t将完成一条指令,所需时间为:3△t+2△t+4△t+4△t*9=45△t
第 6 题
甲和乙要进行通信,甲对发送的消息附加了数字签名,乙收到该消息后利用( )验证该消息的真实性。
- (A) 甲的公钥
- (B) 甲的私钥
- (C) 乙的公钥
- (D) 乙的私钥
答案与解析
- 试题难度:一般
- 知识点:信息安全>信息摘要与数字签名
- 试题答案:[['A']]
- 试题解析:
本题考查数字签名的概念。
数字签名技术是不对称加密算法的典型应用:数据源发送方使用自己的私钥对数据校验和/或其他与数据内容有关的变量进行加密处理,完成对数据的合法“签名”,数据接收方则利用对方的公钥来解读收到的“数字签名”,并将解读结果用于对数据完整性的检验,以确认签名的合法性。数字签名主要的功能是:保证信息传输的完整性,发送者的身份认证,防止交易中的抵赖发生。
第 7 题
在Windows系统中,默认权限最低的用户组是( )。
- (A) everyone
- (B) administrators
- (C) power users
- (D) users
答案与解析
- 试题难度:一般
- 知识点:操作系统>其它
- 试题答案:[['A']]
- 试题解析:
本题考查Windows用户权限方面的知识。在以上4个选项中,用户组默认权限由高到低的顺序是:administrators→power users→users→everyone
第 8 题
IIS6.0支持的身份验证安全机制有4种验证方法, 其中安全级别最高的验证方法是( ) 。
- (A) 匿名身份验证
- (B) 集成Windows身份验证
- (C) 基本身份验证
- (D) 摘要式身份验证
答案与解析
- 试题难度:一般
- 知识点:计算机网络>其它
- 试题答案:[[B]]
- 试题解析:
本题考查Windows IIS服务中身份认证的基础知识。
Windows IIS服务支持的身份认证方式有:.Net Passport身份验证、集成Windows身份验证、摘要式身份验证和基本身份验证。
集成Windows身份验证:以Kerberos票证的形式通过网络向用户发送身份验证信息,并提供较高的安全级别。Windows 集成身份验证使用Kerberos 版本5和NTLM身份验证。
摘要式身份验证:将用户凭据作为MD5哈希或消息摘要在网络中进行传输,这样就无法根据哈希对原始用户名和密码进行解码
.Net Passport 身份验证:对IIS的请求必须在查询字符串或Cookie中包含有效的.Net Passport凭据,提供了单一登录安全性,为用户提供对Internet上各种服务的访问权限。
基本身份验证:用户凭据以明文形式在网络中发送。这种形式提供的安全级别很低,因为几乎所有协议分析程序都能读取密码。
第 9 题
软件著作权的客体不包括 ( )。
- (A) 源程序
- (B) 目标程序
- (C) 软件文档
- (D) 软件开发思想
答案与解析
- 试题难度:容易
- 知识点:法律法规与标准化>其它
- 试题答案:[['D']]
- 试题解析:
软件著作权的客体是指著作权法保护的计算机软件,包括计算机程序及其相关文档。
计算机程序通常包括源程序和目标程序。
源程序(又称源代码、源码)是采用计算机程序设计语言(如C、Java语言)编写的程序,需要转换成机器能直接识别和执行的形式才能在计算机上运行并得出结果。它具有可操作性、间接应用性和技术性等特点。
目标程序以二进制编码形式表示,是计算机或具有信息处理能力的装置能够识别和执行的指令序列,能够直接指挥和控制计算机的各部件(如存储器、处理器、I/O设备等)执行各项操作,从而实现一定的功能。它具有不可读性、不可修改性和面向机器性等特点。
源程序与目标程序就其逻辑功能而言不仅内容相同,而且表现形式相似,二者可以互相转换,最终结果一致。源程序是目标程序产生的基础和前提,目标程序是源程序编译的必然结果;源程序和目标程序具有独立的表现形式,但是目标程序的修改通常依赖于源程序。同一程序的源程序文本和目标程序文本应当视为同一程序,无论是用源程序形式还是目标程序形式体现,都能得著作权法保护。
计算机软件包含了计算机程序,并且不局限于计算机程序,还包括与之相关的程序描述和辅助资料。我国将计算机程序文档(软件文档)视为计算机软件的一个组成部分。计算机程序文档与计算机程序不同,计算机程序是用编程语言,如汇编语言、C语言、Java语言等编写而成,而计算机程序文档是由自然语言或由形式语言编写而成的。计算机程序文档是指用自然语言或由形式语言编写的文字资料和图表,用来描述程序的内容、组成、设计、功能、开发情况、测试结果及使用方法等。计算机程序文档一般以程序设计说明书,流程图、数据流图和用户手册等表现
我国《计算机软件保护条例》第六条规定:“本条例对软件著作权的保护不延及开发软件所用的思想、处理过程、操作方法或者数学概念等”。也就是说,软件开发的思想、处理过程、操作方法或者数学概念等与计算机软件分别属于主客观两个范畴。思想是开发软件的设计方案、构思技巧和功能,设计程序所实现的处理过程、操作方法、算法等,表现是完成某项功能的程序。
我国著作权法只保护作品的表达,不保护作品的思想、原理、概念、方法、公式、算法等,因此对计算机软件来说,只有程序的作品性能得到著作权法的保护,而体现其工具性的程序构思、程序技巧等却无法得到保护。实际上计算机程序的技术设计,如软件开发中对软件功能、程序技巧等却无法得到保护。实际上计算机程序的技术设计,如软件开发中对软件功能、结构的构思,往往是比程序代码更重要的技术成果,通常体现了软件开发中的主要创造性贡献。
第 10 题
中国企业M与美国公司L进行技术合作,合同约定M使用一项在有效期内的美国专利,但该项美国专利未在中国和其他国家提出申请。对于M销售依照该专利生产的产品,以下叙述正确的是 ( )。
- (A) 在中国销售,M需要向L支付专利许可使用费
- (B) 返销美国,M不需要向L支付专利许可使用费
- (C) 在其他国家销售,M需要向L支付专利许可使用费
- (D) 在中国销售,M不需要向L支付专利许可使用费
答案与解析
- 试题难度:容易
- 知识点:法律法规与标准化>侵权判断
- 试题答案:[['D']]
- 试题解析:
本题考查知识产权知识,涉及专利权的相关概念。知识产权受地域限制,只有在一定地域内知识产权才具有独占性。也就是说,各国依照其本国法律授予的知识产权,只能在其本国领域内受其法律保护,而其他国家对这种权利没有保护的义务,任何人均可在自己的国家内自由使用外国人的知识产品,既无需取得权利人的同意(授权),也不必向 权利人支付报酬。例如,中国专利局授予的专利权或中国商标局核准的商标专用权,只能在中国领域内受保护,在其他国家则不给予保护。外国人在我国领域外使用中国专利局授权的发明专利不侵犯我国专利权,如美国人在美国使用我国专利局授权的发明专利不侵犯我国专利权
通过缔结有关知识产权的国际公约或双边互惠协定的形式,某一国家的国民(自然人或法人)的知识产权在其他国家(缔约国)也能取得权益。参加知识产权国际公约的国家(或者签订双边互惠协定的国家)会相互给予成员国国民的知识产权保护,所以,我国公民、法人完成的发明创造要想在外国受保护,必须在外国申请专利。商标要在外国受保护,必须在外国申请商标注册。著作权虽然自动产生,但它受地域限制,我国法律对外国人的作品并不是都给予保护,只保护共同参加国际条约国家的公民作品。同样,参加公约的其他成员国也按照公约规定,对我国公民和法人的作品给予保护。虽然众多知识产权国际条约等的订立使地域性有时会变得模糊,但地域性的特征不但是知识产权最“古老”的特征,也是最基础的特征之一。目前知识产权的地域性仍然存在,是否授予权利、如何保护权利仍须 由各缔约国按照其国内法来决定。
本题涉及的依照该专利生产的产品在中国或其他国家销售,中国M企业不需要向美国L公司支付这件美国专利的许可使用费。这是因为L公司未在中国及其他国家申请该专利,不受中国及其他国家专利法的保护,因此依照该专利生产的产品在中国及其他国家销售,M企业不需要向L公司支付这件专利的许可使用费。如果返销美国,需要向L公司支付这件专利的许可使用费。这是因为这件专利已在美国获得批准,因而受到美国专利法的保护,M企业依照该专利生产的产品在美国销售,则需要向L公司支付这件专利的许可使用费。
第 11 题
使用( ) DPI的分辨率扫描一幅2×4英寸的照片,可以得到一幅300×600像素的图像。
- (A) 100
- (B) 150
- (C) 300
- (D) 600
答案与解析
- 试题难度:容易
- 知识点:多媒体基础>图像数字化
- 试题答案:[['B']]
- 试题解析:
本题考查多媒体基础知识。我们经常遇到的分辨率有两种,即显示分辨率和图像分辨率。显示分辨率是指显示屏上能够显示出的像素数目。例如,显示器分辨率为1024×768 表示显示屏分成768行(垂直分辨率),每行(水平分辨率)显示1024个像素,整个显示屏就含有796432个显像点。屏幕能够显示的像素越多,说明显示设备的分辨率越高,显示的图像质量越高。图像分辨率是指组成一幅图像的像素密度,也是用水平和垂直的像素表示,即用每英寸多少点表示数字化图像的大小。例如:用200dpi来扫描一幅2×2.5英寸的彩色照片,那么得到一幅400×500个像素点的图像。它实质上是图像数字化的采样间隔,由它确立组成一幅图像的像素数目。对同样 大小的一幅图,如果组成该图的图像像素数目越多,则说明图像分辨率越高,图像看起来就越逼真。相反,图像显得越粗糙。因此,不同的分辨率会造成不同的图像清晰度。
第 12 题
计算机数字音乐合成技术主要有( )两种方式,其中使用( )合成的音乐,其音质更好。
- (A) FM和AM
- (B) AM和PM
- (C) FM和PM
- (D) FM和Wave Table
- (A) FM
- (B) AM
- (C) PM
- (D) Wave Table
答案与解析
- 试题难度:一般
- 知识点:多媒体基础>音频数字化
- 试题答案:[['D'],['D']]
- 试题解析:
本题考查多媒体基础知识。计算机和多媒体系统中的声音,除了数字波形声音之外,还有一类是使用符号表示的,由计算机合成的声音包括语音合成和音乐合成。音乐合成技术主要有调频(FM)音乐合成、波形表(Wave Table)音乐合成两种方式。调频音乐合成是使高频震荡波的频率按调制信号规律变化的一种调制方式。采用不同调制波频率和调制指数就可以方便地合成具有不同频谱分布的波形,再现某些乐器的音色。可以采用这种方法得到具有独特效果的“电子模拟声”,创造出丰富多彩的声音,是真实乐器所不具备的音色。波形表音乐合成是将各种真实乐器所能发出的所有声音(包括各个音域、声调)录制下来,存储为一个波表文件。播放时,根据MIDI文件记录的乐曲信息向波形表发出指令,从“表格”中逐一找出对应的声音信息,经过合成、加工后回放出来。应用调频音乐合成技术的乐声已经很逼真,波形表音乐合成技术的乐音更真实。目前这两种音乐合成技术都应用于多媒体计算机的音频卡中。
第 13 题
数据流图(DFD)对系统的功能和功能之间的数据流进行建模,其中顶层数据流图描述了系统的( )。
- (A) 处理过程
- (B) 输入与输出
- (C) 数据存储
- (D) 数据实体
答案与解析
- 试题难度:一般
- 知识点:软件工程>DFD与数据字典
- 试题答案:[['B']]
- 试题解析:
本题考查数据流图的基本概念。数据流图从数据传递和加工的角度,以图形的方式刻画数据流从输入到输出的移动变换过程,其基础是功能分解。对于复杂一些的实际问题,在数据流图中常常出现许多加工,这样看起来不直观,也不易理解,因此用分层的数据流图来建模。按照系统的层次结构进行逐步分解,并以分层的数据流图反映这种结构关系。
在分层的数据流图中,各层数据流图应保持“平衡”关系,即输入和输出数据流在各层应该是一致的。
第 14 题
模块A执行几个逻辑上相似的功能,通过参数确定该模块完成哪一个功能,则该模块具有( )内聚。
- (A) 顺序
- (B) 过程
- (C) 逻辑
- (D) 功能
答案与解析
- 试题难度:一般
- 知识点:软件工程>软件设计
- 试题答案:[['C']]
- 试题解析:
本题考查软件设计的相关内容。模块独立性是创建良好设计的一个重要原则,一般采用模块间的耦合和模块的内聚两个准则进行度量。内聚是指模块内部各元素之间联系的紧密程度,内聚度越高,则模块的独立性越好。内聚性一般有以下几种:
1、 偶然内聚:指一个模块内的各个处理元素之间没有任何联系。
2、逻辑内聚:指模块内执行几个逻辑上相似的功能,通过参数确定该模块完成哪一个功能。
3、时间内聚:把需要同时执行的动作组合在一起形成的模块。
4、通信内聚:指模块内所有处理元素都在同一数据结构上操作,或者指各处理使用相同的输入数据或者产生相同的输出数据。
5、顺序内聚:指一个模块中各个处理元素都密切相关于同一功能且必须顺序执行,前一个功能元素的输出就是下一个功能元素的输入。
6、功能内聚:是最强的内聚,指模块内所有元素共同完成一个功能,缺一不可。
第 15 题
下图是一个软件项目的活动图,其中顶点表示项目里程碑,连接顶点的边表示包含的活动,边上的值表示完成活动所需要的时间,则( )在关键路径上。

- (A) B
- (B) C
- (C) D
- (D) H
答案与解析
- 试题难度:容易
- 知识点:项目管理>Gant图与Pert图
- 试题答案:[[B]]
- 试题解析:
本题考查项目管理及工具技术。根据关键路径法,计算出关键路径为A—C—F—G—I,关键路径长度为17。因此里程碑C在关键路径上。
第 16 题
( )最不适于采用无主程序员组的开发人员组织形式。
- (A) 开发人数少(如3—4人)的项目
- (B) 采用新技术的项目
- (C) 大规模项目
- (D) 确定性较小的项目
答案与解析
- 试题难度:一般
- 知识点:项目管理>其它
- 试题答案:[[C]]
- 试题解析:
本题考查项目管理的人员管理。程序设计小组的组织形式一般有主程序员组,无主程序员组和层次式程序员组。其中无主程序员组中的成员之间相互平等,工作目标和决策都由全体成员民主讨论。对于项目规模较小、开发人员少、采用新技术和确定性较小的项目比较合适,而对大规模项目不适宜采用。
第 17 题
若软件项目组对风险采用主动的控制方法,则( )是最好的风险控制策略。
- (A) 风险避免
- (B) 风险监控
- (C) 风险消除
- (D) 风险管理及意外事件计划
答案与解析
- 试题难度:一般
- 知识点:项目管理>风险管理
- 试题答案:[['A']]
- 试题解析:
本题考查项目管理的风险管理。风险控制的目的是辅助项目组建立处理风险的策略,有效地策略必须考虑以下三个问题,即风险避免、风险监控和风险管理及意外事件计划,而其中风险避免是最好的风险控制策略
第 18 题
对于逻辑表达式“x and y or not z”,and、or、not分别是逻辑与、或、非运算,优先级从高到低为not、and、or,and、or为左结合,not为右结合,若进行短路计算,则( )。
- (A) x为真时,整个表达式的值即为真,不需要计算y和z的值
- (B) x为假时,整个表达式的值即为假,不需要计算y和z的值
- (C) x为真时,根据y的值决定是否需要计算z的值
- (D) x为假时,根据y的值决定是否需要计算z的值
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>数据的表示
- 试题答案:[['C']]
- 试题解析:
本题考查程序语言基础知识。
对逻辑表达式可以进行短路计算,其依据是:a and b 的含义是a和b同时为“真”,则a and b为“真”,因此,若a为“假”,则无论b的值为“真”或“假”,a and b必然为“假”;a or b的含义是a 和 b同时为“假”,则a or b为“假”,因此,若a为“真”,则无论b的值为“真”或“假”,a or b 必然为“真”
在优先级和结合性规定下,对逻辑表达式“X and Y Or NOT Z”求值时,应先计算“X and Y”的值,若为“假”,才去计算“Not Z”来确定表达式的值而不管y是“真”是“假”。当X的值为“真”,则需要计算Y的值:若y的值为“真”,则整个表达式的值为“真”(从而不需要计算“Not Z”);若Y的值为“假”,则需要计算“Not Z”来确定表达式的值。
第 19 题
对于二维数组a[1…N,1…N]中的一个元素a[i,j](1≤i,J≤N),存储在a[i,j]之前的元素个数( )。
- (A) 与按行存储或按列存储方式无关
- (B) 在i=j时与按行存储或按列存储方式无关
- (C) 在按行存储方式下比按列存储方式下要多
- (D) 在按行存储方式下比按列存储方式下要少
答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>数组与矩阵
- 试题答案:[['B']]
- 试题解析:
本题考查数组元素的存储
二维数组A[1…n,1…n]的元素布局如下:
a[1,1] a[1,2] … a[1,j] … a[1…n]
a[2,1] a[2,2] … a[2,j] … a[2...n]
. . .
. . .
. . .
a[i,1] a[i,2] … a[I , j] … a[i...n]
. . .
. . .
. . .
a[n,1] a[n,2] … a[n , j] … a[n…n]
在按行存储方式下,a[i , j]之前的元素个数为(i-1)*N+j-1;在按列存储方式下,a[i , j]之前的元素个数为(j-1)*N+i-1。若i=j,在a[i , j]是主对角线上的元素,显然(i-1)*N+j-1与(j-1)*N+i-1相等。若i<j,则a[i , j]是上三角区域的元素;i>j,则a[i , j]是下三角区域的元素,这两种情况下,存储在a[i , j]之前的元素个数分别为(i-1)*N+j-1和(j-1)*N+i-1,其大小关系依赖于i和j的具体取值。
第 20 题
算术表达式x-(y+c)*8的后缀式是( ) (-、+、*表示算术的减、加、乘运算,运算符的优先级和结合性遵循惯例)。
- (A) xyc8-+*
- (B) x y-c +8*
- (C) x y c 8*+-
- (D) x y c +8*-
答案与解析
- 试题难度:一般
- 知识点:程序设计语言>后缀表达式
- 试题答案:[['D']]
- 试题解析:
本题考查程序语言基础知识
后缀表达式(也叫逆波兰)是将运算符写在操作数之后的表达式表示方法。
表达式“x-(y+c)*8”的后缀表达式为“x y c +8*-”
第 21 题
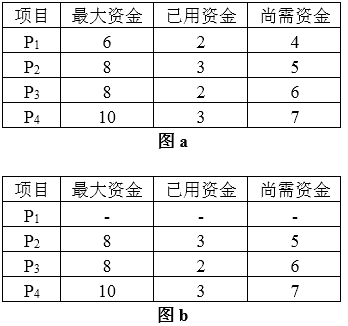
若某企业拥有的总资金数为15,投资4个项目P1、P2、P3、P4,各项目需要的最大资金数分别是6、8、8、10,企业资金情况如图a所示。 P1新申请2个资金, P2新申请1个资金,若企业资金管理处为项目 P1和 P2分配新申请的资金,则 P1、P2、P3、P4尚需的资金数分别为( ) ;假设 P1已经还清所有投资款,企业资金使用情况如图b所示,那么企业的可用资金数为( ) 。若在图b所示的情况下,企业资金管理处为 P2、P3、P4各分配资金数2、2、3,则分配后 P2、P3、P4已用资金数分别为( ) 。
- (A) 1、3、6、7,可用资金数为0,故资金周转状态是不安全的
- (B) 2、5、6、7,可用资金数为1,故资金周转状态是不安全的
- (C) 2、4、6、7,可用资金数为2,故资金周转状态是安全的
- (D) 3、3、6、7,可用资金数为2,故资金周转状态是安全的
- (A) 4
- (B) 5
- (C) 6
- (D) 7
- (A) 3、2、3,尚需资金数分别为5、6、7,故资金周转状态是安全的
- (B) 5、4、6,尚需资金数分别为3、4、4,故资金周转状态是安全的
- (C) 3、2、3,尚需资金数分别为5、6、7,故资金周转状态是不安全的
- (D) 5、4、6,尚需资金数分别为3、4、4,故资金周转状态是不安全的
答案与解析
- 试题难度:一般
- 知识点:操作系统>银行家算法
- 试题答案:[['C'],['D'],['D']]
- 试题解析:
本题考查操作系统进程管理方面的基础知识。
在图a的情况下,项目P1申请2个资金,P2申请1个资金,则企业资金管理处分配资金后项目P1、P2、P3、P4已用的资金数分别为4、4、2、3,可用资金数为2,故尚需的资金数分别为2、4、6、7。由于可用资金数为2,能保证项目
P1 完成。假定项目P1完成释放资源后,可用资金数为6,能保证项目P2或P3完成。同理,项目P2完成释放资源后,可用资金数为10,能保证项目P3或P4完成,故资金周转状态是安全的。</p>
对于图b,因为企业资金管理处为项目P2、P3、P4已分配资金数为3、2、3,若企业资金管理处又为项目P2、P3、P4分配资金数为2、2、3,则企业分配后项目P2、P3、P4已用资金数分别为5、4、6,可用资金为0,尚需资金数分别为3、4、4,故资金周转状态是不安全的。
第 22 题
假设一台按字节编址的16位计算机系统,采用虚拟页式存储管理方案,页面的大小为2K,且系统中没有使用快表(或联想存储器)。某用户程序如图a所示,该程序的页面变换表如图b所示,表中状态位等于1和0分别表示页面在内存或不在内存。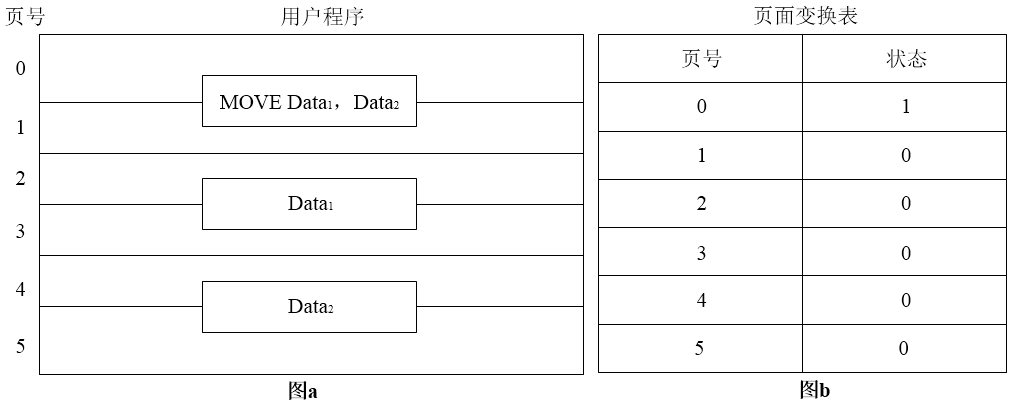
图a中MOVE Data1,Data2是一个4字节的指令,
Data1 和
Data2表示该指令的两个32位操作数。假设MOVE指令存放在2047地址开始的内存单元中,
Data1 存放在6143地址开始的内存单元中,
Data2存放在10239地址开始的内存单元中,那么执行MOVE指令将产生( ) 次缺页中断,其中:取指令产生( ) 次缺页中断。
- (A) 3
- (B) 4
- (C) 5
- (D) 6
- (A) 0
- (B) 1
- (C) 2
- (D) 3
答案与解析
- 试题难度:一般
- 知识点:操作系统>页面置换算法
- 试题答案:[['C'],['B']]
- 试题解析:
本题考查操作系统中系统内存管理方面的知识,从题图中可见,程序的MOVE指令跨两个页面,且源地址Data1 和目标地址
Data2所涉及的区域也跨两个页面的页内地址,根据题意,页面1、2、3、4和5不在内存,系统取MOVE Data1,Data2指令时,由于该指令跨越页面0、1,查页面变换表可以发现页面1不在内存,故需要产生一次缺页中断,取地址为
Data1 的操作数,由于该操作数不在内存且跨越页面2、3,需要将页面2、3装入内存,所以产生两次缺页中断,同理,取地址为
Data2的操作数时,由于该操作数不在内存且跨越页面4、5,需要将页面4、5装入内存,所以产生两次缺页中断,共产生5次缺页中断。</p>
第 23 题
E-R模型向关系模型转换时,三个实体之间多对多的联系m:n:p应该转换为一个独立的关系模式,且该关系模式的主键由( )组成。
- (A) 多对多联系的属性
- (B) 三个实体的主键
- (C) 任意一个实体的主键
- (D) 任意两个实体的主键
答案与解析
- 试题难度:一般
- 知识点:数据库设计>逻辑结构设计
- 试题答案:[['B']]
- 试题解析:
本题考查数据库设计方面的基础知识。
E-R模型向关系模型转换时,两个以上实体之间多对多的联系应该转换为一个独立的关系模式,且该关系模式的关键字由这些实体关键字组成。
第 24 题
给定关系模式销售排名(员工号,商品号,排名),若每一名员工每种商品有一定的排名,每种商品每一排名只有一名员工,则以下叙述中错误的是( )。
- (A) 关系模式销售排名属于3NF
- (B) 关系模式销售排名属于BCNF
- (C) 只有(员工号,商品号)能作为候选键
- (D) (员工号,商品号)和(商品号,排名)都可以作为候选键
答案与解析
- 试题难度:一般
- 知识点:关系数据库>1NF至4NF
- 试题答案:[['C']]
- 试题解析:
本题考查关系数据库的基本概念
试题给定关系模式销售排名(员工号,商品好,排名),若每一名员工每种商品有一定的排名,每种商品每一排名只用一名员工,根据语义可得到如下的函数依赖:
(员工号,商品号)→排名,(商品号,排名)→员工号可见,(员工号,商品号),(商品号,排名)都可以作为候选键,又由于在销售排名关系中无非主属性,且每一个决定因素都包含候选键,因此该销售排名关系属于BCNF,显然也属于3NF
第 25 题
在数据库系统中,( )用于对数据库中全部数据的逻辑结构和特征进行描述:其中,外模式、模式和内模式分别描述( )层次上的数据特性。
- (A) 外模式
- (B) 模式
- (C) 内模式
- (D) 存储模式
- (A) 概念视图、用户视图和内部视图
- (B) 用户视图、内部视图和概念视图
- (C) 概念视图、内部视图和用户视图
- (D) 用户视图、概念视图和内部视图
答案与解析
- 试题难度:一般
- 知识点:数据库技术基础>数据库的三级模式结构与两级映像
- 试题答案:[['B'],['D']]
- 试题解析:
本题考查数据库系统基本概念方面的基础知识
在数据库系统中,模式用于对数据库中全部数据的逻辑结构和特征进行描述,即模式用于描述概念视图层次上的数据特性。外模式也称为用户模式或子模式,是用户与数据库系统的接口,是用户用到的那部分数据的描述,即外模式用于描述用户视图层次上的数据特性,内模式也称存储模式,是数据物理结构和存储方式的描述,即内模式用于描述内部视图层次上的数据特性,是数据在数据库内部的表示方式。
第 26 题
数据库应用系统的生命周期分为如下图所示的六个阶段,图中①、②、③、④分别表示( )阶段。( )阶段是对用户数据的组织和存储设计,以及对数据操作及业务实现的设计,包括事务设计和用户界面设计。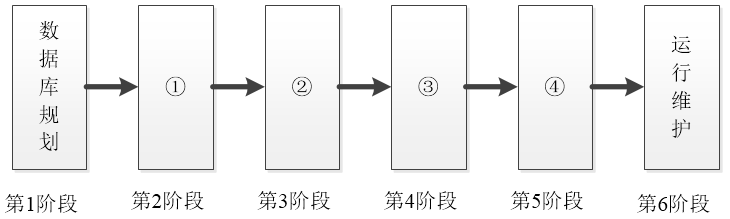
- (A) 数据库与应用程序设计、需求描述与分析、实现、测试
- (B) 数据库与应用程序设计、实现、测试、需求描述与分析
- (C) 需求描述与分析、数据库与应用程序设计、实现、测试
- (D) 需求描述与分析、实现、测试、数据库与应用程序设计
- (A) 数据库与应用程序设计
- (B) 需求描述与分析
- (C) 实现
- (D) 测试
答案与解析
- 试题难度:容易
- 知识点:数据库设计>其它
- 试题答案:[['C'],['A']]
- 试题解析:
本题考查数据库设计方面的基础知识。
数据库应用系统的生命周期分为:数据库规划、需求描述与分析、数据库与应用程序设计、实现、测试和运行维护6个阶段。其中,数据库与应用程序设计阶段是对用户数据的组织和存储设计,以及对数据操作及业务实现的设计,包括事物设计和用户界面设计。
第 27 题
某销售公司数据库的零件关系P(零件号,零件名称,供应商,供应商所在地,库存量),函数依赖集F={零件号→零件名称,(零件号,供应商)→库存量,供应商→供应商所在地}。零件关系P的主键为( ),该关系模式属于( )。
查询各种零件的平均库存量、最多库存量与最少库存量之间差值的SQL语句如下:
SELECT 零件号,( )
FROM P
( );
查询供应商所供应的零件名称为P1或P3,且50≤库存量≤300以及供应商地址包含“雁塔路”的SQL语句如下:
SELECT零件名称,供应商,库存量
FROM P
WHERE ( )AND 库存量 ( )AND 供应商所在地 ( );
- (A) 零件号,零件名称
- (B) 零件号,供应商所在地
- (C) 零件号,供应商
- (D) 供应商,供应商所在地
- (A) 1NF
- (B) 2NF
- (C) 3NF
- (D) 4NF
- (A) AVG(库存量)AS平均库存量,MAX(库存量)-MIN(库存量)AS差值
- (B) 平均库存量AS AVG(库存量),差值AS MAX(库存量)-MIN(库存量)
- (C) AVG库存量AS平均库存量,MAX库存量-MIN库存量AS差值
- (D) 平均库存量AS AVG库存量,差值AS MAX库存量-MIN库存量
- (A) ORDER BY供应商
- (B) ORDER BY零件号
- (C) GROUP BY供应商
- (D) GROUP BY零件号
- (A) 零件名称=’P1’ AND零件名称=’P3’
- (B) (零件名称= ’P1’AND零件名称=’P3t)
- (C) 零件名称=’P1’ OR零件名称=’P3’
- (D) (零件名称=’P1’ OR零件名称=’P3’)
- (A) Between 50 T0 300
- (B) Between 50 AND 300
- (C) IN (50 T0 300)
- (D) IN 50 AND 300
- (A) in’%雁塔路%’
- (B) like’_雁塔路%’
- (C) like’%雁塔路%’
- (D) like’雁塔路%’
答案与解析
- 试题难度:一般
- 知识点:SQL语言>SELECT语句
- 试题答案:[['C'],['A'],['A'],['D'],['D'],['B'],['C']]
- 试题解析:
本题考查关系数据库及SQL方面的基础知识。
根据题意,零件P关系中的(零件号,供应商)可决定零件P关系的所有属性,所以零件P关系的主键为(零件号,供应商)。另外,根据题意(零件号,供应商)→零件名称,而零件号→零件名称,供应商→供应商所在地,可以得出零件名称和供应商所在地都部分依赖于码,所以关系模式属于1NF。
查询各种零件的平均库存量、最高库存量与最低库存量之间的差距时,首先需要在结果列中的空处填写AVG(库存量)AS 平均库存量,MAX(库存量)-MIN(库存量)AS 差值。其次必须用分组语句按零件号分组,故四空应填写 GROUP BY 零件号。第五空的正确选项为D,因为试题要求查询供应商所供应的零件名称为P1或P3,选项A和B显然是错误的;选项C也是错误的,因为只要零件名称为P1也会在结果集中,故不符合查询要求,所以正确的选项为(零件名称=‘P1’ OR 零件名称=‘P2’)。
对于第六空,要求查询50<=库存量<=300,选项A、C和D的语法格式是错误的,正确的格式为Between 50 AND 300。最后一空的正确选项为C。因为试题要求查询供应商地址包含“雁塔路”,选项C满足查询要求;选项A语法格式是错误的,选项B的含义是查询第二个字开始为“雁塔路”的供应商地址,选项D的含义是查询以“雁塔路”打头的供应商地址。
第 28 题
假设关系R1、R2和R3如下所示:
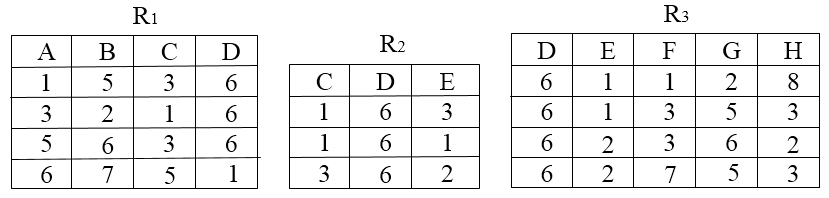
若进行R1⋈R2运算,则结果集分别为( )元关系,共有( )个元组;若进行R2×σF<4(R3)运算,则结果集为( )元关系,共有( )个元组。
- (A) 4
- (B) 5
- (C) 6
- (D) 7
- (A) 4
- (B) 5
- (C) 6
- (D) 7
- (A) 5
- (B) 6
- (C) 7
- (D) 8
- (A) 9
- (B) 10
- (C) 11
- (D) 12
答案与解析
- 试题难度:一般
- 知识点:关系数据库>关系代数运算
- 试题答案:[['B'],['A'],['D'],['A']]
- 试题解析:
本题考查数据库系统中关系代数运算方面的基础知识。
根据题意,R1和R2为自然连接,自然连接是一种特殊的等值连接,要求两个关系中进行比较的分量必须是相同的属性,并且在结果集中将重复属性列去掉。本题比较的条件为R1.C=R2.C 并且R1.D=R2.D,故结果集共有4个元组满足条件,在结果集中将重复属性列R2.C和R2.D去掉,故结果集为5元关系。
根据题意,R3进行选择运算后的结果集再与R2进行笛卡尔积运算,R3 进行选择运算后(F列的值小于4)的结果有3个元组,故再与R2进行笛卡尔积运算为3×3=9个元组。
第 29 题
系统中有三个事务T1、T2、T3分别对数据R1和R2进行操作,其中R1和R2的初值R1=120、R2=50。假设事务T1、T2、T3操作的情况如下图所示,图中T1与T2间并发操作( ) 问题,T2与T3间并发操作( ) 问题。

- (A) 不存在任何
- (B) 存在T1不能重复读的
- (C) 存在T1丢失修改的
- (D) 存在T2读“脏”数据的
- (A) 不存在任何
- (B) 存在T2读”脏“数据的
- (C) 存在T2丢失修改的
- (D) 存在T3丢失修改的
答案与解析
- 试题难度:一般
- 知识点:事务管理>并发操作及问题
- 试题答案:[['B'],['C']]
- 试题解析:
本题考查数据库并发控制方面的基础知识。所谓并发操作是指在多用户共享的系统中,许多用户可能同时对同一数据进行操作。并发操作带来的问题是数据的不一致性,主要有三类:丢失更新、不可重复读和读脏数据。其主要原因是事物的并发操作破坏了事务的隔离性。
事物T1、T2分别对数据R1和R2进行读写操作,在T3时刻事物T1将R1和R2相加存入X,X=170。在t7时刻事务T2将R1减去R2存入R2,R2=70。在t11时刻事务T1将R1和R2相加存入X,X=190,验算结果不对。这种情况称为“不能重复读”。
事物T2、T3分别对数据R1和R2进行读写操作,在t7时刻T2将R1减去R2存入R2,R2=70。在t12时刻事务T3将R2加80存入R2 ,R2=130,可见,T2与T3间并发操作丢失了事务T2对R2的修改,将这种情况称为丢失修改。
第 30 题
以下属于DBA职责的是( ) 。
- (A) 开发应用程序
- (B) 负责系统设计
- (C) 系统故障恢复
- (D) 负责调试安装
答案与解析
- 试题难度:一般
- 知识点:数据库技术基础>其它
- 试题答案:[['C']]
- 试题解析:
本题考查对数据库应用系统开发维护的掌握。应用系统的分析设计由系统分析员和设计人员负责,DBA也会参与分析和设计,程序的编写和调试安装由应用程序员负责。DBA作为企业人员,负责系统的日常维护和故障恢复。
第 31 题
约束“主码中的属性不能取空值”,属于( )。
- (A) 实体完整性约束
- (B) 参照完整性约束
- (C) 用户定义完整性约束
- (D) 函数依赖
答案与解析
- 试题难度:一般
- 知识点:关系数据库>关系数据库相关术语
- 试题答案:[['A']]
- 试题解析:
本题考查对关系基本概念的理解。关系的定义包含约束的定义,实体完整性约束指关系的主码中出现的任何属性都不能取空值。参照完整性指外码的取值要么取空值,要么取被参照关系的主码中已有的值。用户自定义完整性约束通常指属性的值域限制,如性别只能取“男”或“女”,成绩只能取0~100分之间等。函数依赖指属性间的取值约束,如部门名称相同的员工记录,其部门经理的取值一定相同。
第 32 题
引入索引的目的是为了( )。
- (A) 提高查询语句执行效率
- (B) 提高更新语句执行效率
- (C) 实现数据的物理独立性
- (D) 实现数据的逻辑独立性
答案与解析
- 试题难度:容易
- 知识点:SQL语言>索引
- 试题答案:[[A]]
- 试题解析:
本题考查对索引的掌握。记录如果按某个字段的取值顺序存储或哈希存储,则对该字段查找时可以按照二分查找或哈希函数定位,而不采取顺序查找的方式,可以大大提高查询效率。但记录只能以一种顺序进行物理存储,而不同的查询条件会使用不同的字段,因此引入索引表,包括索引项和指针项,索引项即为查询条件中的字段,指针项指向物理记录,索引项按顺序或哈希组织,查询时先查索引项(二分或哈希查找),根据对应的指针找到记录,从而提高查询效率。但更新数据项时索引表也要保持一致,相比无索引,更新语句执行效率会降低,因此要有选择性地建索引,即对作为查询项的字段考虑建立索引。索引与数据的独立性无关。
第 33 题
以下关于事务调度的叙述中,错误的是( ) 。
- (A) 串行调度是指一个事务执行完再执行下一个事务
- (B) 可串行化调度是正确的调度
- (C) 2PL能够保证可串行化调度
- (D) 2PL能够保证不产生死锁
答案与解析
- 试题难度:容易
- 知识点:事务管理>两段锁协议
- 试题答案:[['D']]
- 试题解析:
本题考查对事务调度的掌握。事务调度是指DBMS对事务指令的安排执行。串行调度是指一个事务执行完后才开始下一事务的执行,同一时刻不存在两个同时执行的事务,事务执行期间不会相互干扰,保证执行结果正确。若对多个事务的并发调度与这些事务的某一串行调度等价,则该并发调度为可串行化调度,是正确的调度。引入两段锁协议,可以保证可串行化调度,得到正确的执行结果。两段锁协议不能避免死锁,对死锁的处理由DBMS负责,主要采用检测和解除死锁的方案。
第 34 题
事务提交之后,其对数据库的修改还存留在缓冲区中,并未写入到硬盘,此时发生系统故障,则破坏了事务的( ) ;系统重启后,由DBMS根据( ) 对数据库进行恢复,将已提交的事务对数据库的修改写入硬盘。
- (A) 原子性
- (B) 一致性
- (C) 隔离性
- (D) 持久性
- (A) 日志
- (B) 数据库文件
- (C) 索引记录
- (D) 数据库副本
答案与解析
- 试题难度:一般
- 知识点:数据库运行与管理>故障分类与恢复
- 试题答案:[['D'],['A']]
- 试题解析:
本题考查对事务ACID(原子性、一致性、隔离性、持久性)属性和故障恢复的理解和掌握。一个事务对应了现实中的一项业务,会涉及多条对数据库的更新指令。事务的ACID属性中,原子性是指事务要么全部执行完,要么不被执行,与现实业务相对应;一致性指事务的执行结果要与现实业务产生的信息相一致,数据库也就处于一致性状态;隔离性指多个事务并发执行时不能相互干扰造成结果的错误;持久性指事务一旦提交,其执行结果应被存入数据库而不被丢失。题干所描述的情况,事务提交后执行结果未写入数据库,因系统重启而丢失,破坏了事务的持久性。系统故障由系统自动恢复,任何对数据库的修改都必须采取先写日志的方式,修改前的数据和修改后的数据都会写入到日志中,而且日志文件写入硬盘后才进行数据库的更新,所以在系统重启后,可以查看日志,对已提交的事务,将其更新结果写入到数据库,即保证了事务的持久性。
第 35 题
需求分析阶段,采用( )对用户各项业务过程中使用的数据进行详细描述。
- (A) 数据流图
- (B) 数据字典
- (C) E-R图
- (D) 关系模式
答案与解析
- 试题难度:一般
- 知识点:软件工程>需求分析
- 试题答案:[[B]]
- 试题解析:
本题考查对数据库设计各阶段的了解。需求分析就是对企业应用的调查和分析,并进行规范的整理,以数据流图的形式描述企业各项业务的进行过程,以数据字典形式对业务过程中使用的数据进行详细的描述,E-R图是概念设计的文档,关系模式属于逻辑设计的内容。
第 36 题
索引设计属于数据库设计的( )阶段。
- (A) 需求分析
- (B) 概念设计
- (C) 逻辑设计
- (D) 物理设计
答案与解析
- 试题难度:一般
- 知识点:数据库设计>物理结构设计
- 试题答案:[[D]]
- 试题解析:
本题考查对数据库设计各个阶段的了解。需求分析阶段完成数据流图和数据字典;概念设计阶段完成E-R图设计;逻辑设计阶段完成关系模式设计和视图设计;物理设计确定数据的存储结构,并设计索引,以提高查询效率。
第 37 题
在定义课程实体时,具有属性:课程号、课程名、学分、任课教师,同时,教师又以实体形式出现在另一 E-R图中,这种情况属于( ),合并E-R图时,解决这一冲突的方法是( )。
- (A) 属性冲突
- (B) 命名冲突
- (C) 结构冲突
- (D) 实体冲突
- (A) 将课程实体中的任课教师作为派生属性
- (B) 将课程实体中的任课教师属性去掉
- (C) 将课程实体中的任课教师属性去掉,在课程与教师实体间建立任课联系
- (D) 将教师实体删除
答案与解析
- 试题难度:一般
- 知识点:数据库设计>概念结构设计
- 试题答案:[['C'],['C']]
- 试题解析:
本题考查对概念设计的理解和掌握。合并E-R图的主要目的是为了解决属性冲突、命名冲突和结构冲突。属性冲突是指同一属性在不同的分E-R图中存在属性域或取值单位的不同;命名冲突是指不同的分E-R图中存在同名异义、异名同义等冲突;结构冲突是指同一对象在不同E-R图中做了不同抽象或同一实体的属性不同,不同抽象是指同一对象在某一E-R图中作实体,而在另一E-R图中又作属性或联系,出现这种情况时,应将作为属性的对象改为实体,并与原所在属性间建立联系。
第 38 题
假设某企业职工实体有属性:职工号、职工姓名、性别、出生日期;部门实体有属性:部门号、部门名称、电话,一个部门可以有多部电话。一个部门有多个职工,职工可以在部门之间调动,要求记录职工每次调动时的调入时间和调出时间。则职工和部门之间的联系属于( ),该联系具有的属性是( ),设计的一组满足4NF的关系模式为( )。
- (A) 1:1联系
- (B) 1:N联系
- (C) N:1联系
- (D) M:N联系
- (A) 工作时间
- (B) 调入时间、调出时间
- (C) 调出时间
- (D) 没有属性
- (A) 职工(职工号,职工姓名,性别,出生日期) 部门(部门号,部门名称,电话) 工作(职工号,部门号,工作时间)
- (B) 职工(职工号,职工姓名,性别,出生日期) 部门(部门号,部门名称,电话) 工作(职工号,部门号,调入时间,调出时间)
- (C) 职工(职工号,职工姓名,性别,出生日期) 部门(部门号,部门名称) 部门电话(部门号,电话) 工作(职工号,部门号,调入时间,调出时间)
- (D) 职工(职工号,职工姓名,性别,出生日期) 部门(部门号,部门名称) 部门电话(部门号,电话) 工作(职工号,部门号,工作时间)
答案与解析
- 试题难度:一般
- 知识点:数据库技术基础>E-R模型
- 试题答案:[['D'],['B'],['C']]
- 试题解析:
本题考查对概念设计的掌握和应用能力。本题中,职工实体集中包含所有职工,部门实体集中包含所有部门,每一职工与现在和曾经工作过的部门都有联系,每一部门会与现有或曾经的职工有联系,故职工与部门间为多对多联系。如果某一职工与某一部门产生联系,必然是他在某一时间在该部门工作,调入时间和调出时间应作为联系的属性。一个部门有多部电话,则电话应作为部门的多值属性。根据由E-R图向关系模式的转换规则,将部门实体的标识符部门号和多值属性电话独立作一个关系模式,标识符部门号和其他属性另作一关系模式:职工实体作为一个关系模式,职工与部门间的多对多联系独立作一个关系模式,包括双方的标识符和联系自有的属性调入时间和调出时间。
第 39 题
给定关系模式R<U,F>,U= {A,B,C,D),F={A→B,BC→D},则关系R的候选键为( ) 。对关系R分解为R1(A,B,C)和R2 (A,C,D),则该分解( ) 。
- (A) (AB)
- (B) (AC)
- (C) (BC)
- (D) (BD)
- (A) 有无损连接性,保持函数依赖
- (B) 不具有无损连接性,保持函数依赖
- (C) 具有无损连接性,不保持函数依赖
- (D) 不具有无损连接性,不保持函数依赖
答案与解析
- 试题难度:一般
- 知识点:关系数据库>求候选码
- 试题答案:[['B'],['C']]
- 试题解析:
本题考查对关系理论的理解和掌握。根据候选码的定义和求解算法,(AC)+=ABCD满足决定性,且A或C都不能决定全属性,故AC为候选码。根据无损连接性判定定理,R1∩R2=AC,R1-R2=B,计算 (AC)+=ABCD,则AC-->B成立,即R1∩R2→R1-R2成立,,故分解具有无损连接性。分解之后R1的函数依赖集F1={A→B},R2的函数依赖集F2={AC→D},F1∪F2={A→B,AC→D},(BC)+(F1∪F2)=BC,不包含D,即F中的BC→D无法由分解之后关系模式中的函数依赖集逻辑地推出,故不保持函数依赖。
第 40 题
通过对历史数据的分析,可以预测年收入超过80000元的年轻女性最有可能购买小型运动汽车。这是通过数据挖掘的( ) 分析得到的。
- (A) 分类
- (B) 关联规则
- (C) 聚类
- (D) 时序模式
答案与解析
- 试题难度:一般
- 知识点:数据库技术基础>数据挖掘最常用的技术
- 试题答案:[['A']]
- 试题解析:
本题考查的是数据挖掘的基础知识。简单地说,数据挖掘是从海量数据中提取或挖掘知识。数据挖掘对数据进行描述和预测。分类、关联规则、聚类和时序分析是数据挖掘的重要分析方法。分类分析首先找出描述和区分数据类或概念的模型,以便能够使用模型来预测类标号未知的对象类。本题中,年收入超过80000元的年轻妇女最有可能购买小型运动车是属于分类分析得到的一个预测结论。关联规则分析用于发现描述数据中强关联特征的模式。聚类指在发现紧密相关的观测值组群,使得与不同组群的观察值相比,属于同一组群内的观测值尽量相似。而时序分析,也称为演变分析,描述行为随着时间变化的对象的规律或趋势,并对其建模。
第 41 题
( )不是数据仓库的特点。
- (A) 面向功能
- (B) 集成
- (C) 非易失
- (D) 随时间变化
答案与解析
- 试题难度:一般
- 知识点:数据库技术基础>数据仓库的基本特性
- 试题答案:[['A']]
- 试题解析:
本题考查数据仓库的基础知识。数据仓库是一个面向主题的、集成的、非易失的且 随时间变化的数据集合,用来支持管理人员的决策。该定义中指明了数据仓库的几个重要的特点。首先是面向主题的。与传统的面向应用不同,数据仓库是面向主题的。其次是集成的。数据仓库的数据来源于多个或多类不同的数据源,在进入数据仓库之前,需要对数据进行抽取、转换和装载操作,将其集成到数据仓库中。再次是非易失的。数据仓库上的数据一般是载入和访问操作,而不是更新操作。最后是随时间变化的。数据仓库中的数据分析结果是某一时刻生成的复杂的快照,其对应的时间期限较长,且键码结构总是包含某时间元素。
第 42 题
以下关于面向对象数据模型的叙述中,错误的是( )。
- (A) 一个对象对应着E-R模型中的一个实体
- (B) 对象类是一系列相似对象的集合
- (C) 对象中的属性和方法对外界是不可见的
- (D) 对象之间的相互作用通过消息来实现
答案与解析
- 试题难度:一般
- 知识点:数据库发展和新技术>面向对象数据模型
- 试题答案:[[C]]
- 试题解析:
本题考查面向对象数据库的基础知识。面向对象数据库系统是以面向对象数据模型为基础的,一系列面向对象的概念构成了面向对象数据模型的基础。如一个对象对应着E-R模型中的一个实体。对象是由封装的属性和方法构成的,封装的属性和方法对外界是不可见的,但对象可以定义对外界可见的属性和方法。对象之间的相互作用要通过消息来实现。在面向对象数据库中,类是一系列对象的集合。
第 43 题
以下关于面向对象数据库系统的叙述中,错误的是( )。
- (A) 具有表达和管理对象的能力
- (B) 具有表达复杂对象结构的能力
- (C) 不具有表达对象嵌套的能力
- (D) 具有表达和管理数据库变化的能力
答案与解析
- 试题难度:容易
- 知识点:数据库发展和新技术>面向对象数据模型
- 试题答案:[['C']]
- 试题解析:
本题考查面向对象数据库的基础知识。数据库的特征依赖于实际应用,所设计的数据库语言必须允许用户方便地使用这些特征,数据库的结构也应能有效地支持这些特征。作为一种新型的数据库系统,面向对象数据库应该具有如下的特征:表达和管理对象的能力,面向对象数据库系统通过对象及其之间的相互联系来描述现实世界;表示复杂对象结构的能力,应该具有表达现实世界的复杂对象的能力;表达和管理数据库变化的能力,管理同一对象的多个版本的能力对于设计和工程应用是至关重要的;具有表达嵌套对象的能力,这是面向对象的一个重要特征。
第 44 题
网络中存在各种交换设备,下面的说法中错误的是( )。
- (A) 以太网交换机根据MAC地址进行交换
- (B) 帧中继交换机只能根据虚电路号DLCI进行交换
- (C) 三层交换机只能根据第三层协议进行交换
- (D) ATM交换机根据虚电路标识进行信元交换
答案与解析
- 试题难度:一般
- 知识点:计算机网络>网络规划与设计
- 试题答案:[['C']]
- 试题解析:
以太网交换机根据数据链路层MAC地址进行帧交换;帧中继网和ATM网都是面向连接的通信网,交换机根据预先建立的虚电路标识进行交换。帧中继的虚电路号是DLCI,进行交换的协议数据单元为“帧”;而ATM网的虚电路号为VPI和VCI,进行交换的协议数据单元为“信元”。
三层交换机是指因特网中使用的高档交换机,这种设备把MAC交换的高带宽和低延迟优势与网络层分组路由技术结合起来,其工作原理可以概括为:一次路由,多次交换。就是说,当三层交换机第一次收到一个数据包时必须通过路由功能寻找转发端口,同时记住目标MAC地址和源MAC地址,以及其他相关信息,当再次收到目标地址和源地址相同的帧时就直接进行交换了,不再调用路由功能。所以三层交换机不但具有路由功能,而且比通常的路由器转发得更快。
第 45 题
SMTP传输的邮件报文采用( ) 格式表示。
- (A) ASCII
- (B) ZIP
- (C) PNP
- (D) HTML
答案与解析
- 试题难度:一般
- 知识点:计算机网络>其它
- 试题答案:[[A]]
- 试题解析:
本题考查SMTP协议及相关服务。SMTP传输的邮件报文需采用ASCII进行编码
第 46 题
网络的可用性是指( ) 。
- (A) 网络通信能力的大小
- (B) 用户用于网络维修的时间
- (C) 网络的可靠性
- (D) 用户可利用网络时间的百分比
答案与解析
- 试题难度:一般
- 知识点:计算机网络>其它
- 试题答案:[[D]]
- 试题解析:
可用性是指网络系统、网络元素或网络应用对用户可利用的时间的百分比。如果用平均无故障时间(MTBF)来度量网络元素的故障率,可用性=MTBF/(MTBF+MTTR)其中MTTR为平均维修时间。
第 47 题
建筑物综合布线系统中的园区子系统是指( )。
- (A) 由终端到信息插座之间的连线系统
- (B) 楼层接线间到工作区的线缆系统
- (C) 各楼层设备之间的互连系统
- (D) 连接各个建筑物的通信系统
答案与解析
- 试题难度:一般
- 知识点:计算机网络>网络规划与设计
- 试题答案:[['D']]
- 试题解析:
结构化布线系统分为6个子系统:工作区系统、水平子系统、干线子系统、设备间子系统、管理子系统和建筑群子系统。
工作区子系统:是由终端设备到信息插座的整个区域。
水平布线子系统:各个楼层接线间所安装的线缆属于水平子系统
管理子系统:管理子系统设置在楼层的接线间内,由各种交连设备以及集线器和交换机等交换设备组成,交连方式取决于网络拓扑结构和工作区设备的要求。
干线子系统:是建筑物的主干线缆,实现各楼层设备间子系统之间的互连。干线子系统通常由垂直的大对数铜缆或光缆组成,一端接于设备间的主配线架上,另一端接在楼层接线间的管理配线架上设备间子系统:是网络管理人员值班的场所,设备间子系统由建筑物的进户线、交换设备、电话、计算机、适配器以及保安设施组成。实现中央主配线架与各种不同设备之间的连接
建筑群子系统:也叫园区子系统,它是连接各个建筑物的通信系统。
第 48 题
如果子网172.6.32.0/20被划分为子网172.6.32.0/26,则下面的结论中正确的是( )。
- (A) 被划分为62个子网
- (B) 每个子网有64个主机地址
- (C) 被划分为32个子网
- (D) 每个子网有62个主机地址
答案与解析
- 试题难度:一般
- 知识点:计算机网络>IP地址与子网划分
- 试题答案:[[D]]
- 试题解析:
子网172.6.32.0/20被划分为子网172.6.32.0/26,网络掩码增加了6位,被划分成了64个子网,每个子网的主机ID为6位,可以提供主机地址的个数为62
第 49 题
At a basic level, cloud computing is simply a means of delivering IT resources as ( ).Almost all IT resources can be delivered as a cloud service: applications, compute power, storage capacity, networking, programming tools, even communication services and collaboration ( )。
Cloud computing began as large-scale Internet service providers such as Google, Amazon, and others built out their infrastructure. An architecture emerged: massively scaled, ( ) distributed system resources, abstracted as virtual IT services and managed as continuously configured, pooled resources. In this architecture, the data is mostly resident on ( )“somewhere on the Internet”and the application runs on both the "cloud servers”and the user’s browser.
Both clouds and grids are built to scale horizontally very efficiently. Both are built to withstand failures of ( ) elements or nodes. Both are charged on a per-use basis. But while grids typically process batch jobs, with a defined start and end point, cloud services can be continuous. What’s more, clouds expand the types of resources available —— file storage, databases, and Web services —— and extend the applicability to Web and enterprise applications.
- (A) hardware
- (B) computers
- (C) services
- (D) software
- (A) computers
- (B) disks
- (C) machines
- (D) tools
- (A) horizontally
- (B) vertically
- (C) inclined
- (D) decreasingly
- (A) clients
- (B) middleware
- (C) servers
- (D) hard disks
- (A) entire
- (B) individual
- (C) general
- (D) separate
答案与解析
- 试题难度:一般
- 知识点:专业英语>专业英语
- 试题答案:[['C'],['D'],['A'],['C'],['B']]
- 试题解析:
本段英文简要介绍云计算的概念。云计算主要是将资源看作云服务,包括应用程序、计算能力、存储容量、网络、编程工具,以及通信和协作工具。云计算最初由一些大的Internet服务提供商构建的基础设施而起步,其架构呈现出大规模、水平分布式系统资源、抽象的IT服务、管理持续配置、资源池等特性,数据大多存储于Internet上的某个地方的服务器上,应用程序运行于云服务器和用户浏览器中。
云和网格都针对有效的水平可扩展性,避免节点的单点失效对系统的影响,都按使用付费。它们的区别是:网格通常是处理一批有明确定义起点和终点的作业,而云服务是可以连续不断的。另外,云扩展了资源的类型,包括文件存储、数据库和Web服务等,也将适用性扩展到Web和企业应用。