201405数据库上午真题
第 1 题
在CPU中,常用来为ALU执行算术逻辑运算提供数据并暂存运算结果的寄存器是( )。
- (A) 程序计数器
- (B) 状态寄存器
- (C) 通用寄存器
- (D) 累加寄存器
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>运算器与控制器
- 试题答案:[['D']]
- 试题解析:本题考查寄存器的类型和特点。
寄存器是CPU中的一个重要组成部分,它是CPU内部的临时存储单元。寄存器既可以用来存放数据和地址,也可以存放控制信息或CPU工作时的状态。在CPU中增加寄存器的数量,可以使CPU把执行程序时所需的数据尽可能地放在寄存器件中,从而减少访问内存的次数,提高其运行速度。但是寄存器的数目也不能太多,除了增加成本外,由于寄存器地址编码增加也会对增加指令的长度。CPU中的寄存器通常分为存放数据的寄存器、存放地址的寄存器、存放控制信息的寄存器、存放状态信息的寄存器和其他寄存器等类型。
</p>
程序计数器用于存放指令的地址。令当程序顺序执行时,每取出一条指令,PC内容自动增加一个值,指向下一条要取的指令。当程序出现转移时,则将转移地址送入PC,然后由PC指向新的程序地址。
程序状态寄存器用于记录运算中产生的标志信息,典型的标志为有进位标志位、零标志位、符号标志位、溢出标志位、奇偶标志等。
地址寄存器包括程序计数器、堆栈指示器、变址寄存器、段地址寄存器等,用于记录各种内存地址。
累加寄存器是一个数据寄存器,在运算过程中暂时存放被操作数和中间运算结果,累加器不能用于长时间地保存一个数据。
第 2 题
某机器字长为n,最高位是符号位,其定点整数的最大值为( )。
- (A)
- (B)
- (C)
- (D)
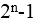
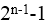
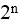
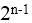
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>数据的表示
- 试题答案:[['B']]
- 试题解析:如下图所示:
</p>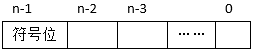
最大值为n-1位(符号位)为0(正数),从n-2到0位都为1,值为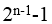 。
。
第 3 题
海明码利用奇偶性检错和纠错,通过在n个数据位之间插入k个检验位,扩大数据编码的码距。若n=48,则k应为( )。
- (A) 4
- (B) 5
- (C) 6
- (D) 7
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>校验码
- 试题答案:[['C']]
- 试题解析:设:N为待发送海明码的总位数,n是有效信息位数,r是校验位个数(分成r组作奇偶校验,能产生r位检错信息)校验位的个数r应满足公式 :N=n+r ≤
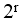 -1。此题中n = 48,校验位个数为k,则
-1。此题中n = 48,校验位个数为k,则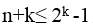 ,即
,即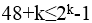 ,则k为6。
,则k为6。
第 4 题
通常可以将计算机系统中执行一条指令的过程分为取指令,分析和执行指令3步。若取指令时间为4△t,分析时间为2△t。执行时间为3△t,按顺序方式从头到尾执行完600条指令所需时间为( )△t;若按照执行第i条,分析第i+1条,读取第i+2条重叠的流水线方式执行指令,则从头到尾执行完600条指令所需时间为( )△t。
- (A) 2400
- (B) 3000
- (C) 3600
- (D) 5400
- (A) 2400
- (B) 2405
- (C) 3000
- (D) 3009
答案与解析
- 试题难度:容易
- 知识点:计算机组成与体系结构>流水线技术
- 试题答案:[['D'],['B']]
- 试题解析:按顺序方式执行时间为(4+2+3)△t * 600=5400△t
流水线方式:单条指令所需时间+(n-1)*(流水线周期),其中,流水线周期是指:指令分段执行中时间最长的一段。该题中时间最长的一段为4△t,所以流水线的周期为:4△t;所以该题按照流水线方式执行的时间为:(4+2+3)△t+(600-1)4△t=2405△t
</p>
第 5 题
若用256K×8bit的存储器芯片,构成地址40000000H到400FFFFFH且按字节编址的内存区域,则需( )片芯片。
- (A) 4
- (B) 8
- (C) 16
- (D) 32
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>内存
- 试题答案:[['A']]
- 试题解析:内存区域从40000000H到40000000H,则其拥有的字节数为:
400FFFFFH - 40000000H + 1 = 100000H=220=1024K
该内存区域有1024K个字节,其空间表示为1024K×8bit,题干中给出一个芯片的空间容量为256K × 8bit,需要的此空间大小的芯片数量为(1024K×8)/(256K × 8)= 4片。
第 6 题
以下关于木马程序的叙述中,正确的是( )。
- (A) 木马程序主要通过移动磁盘传播
- (B) 木马程序的客户端运行在攻击者的机器上
- (C) 木马程序的目的是使计算机或网络无法提供正常的服务
- (D) Sniffer是典型的木马程序
答案与解析
- 试题难度:一般
- 知识点:信息安全>计算机病毒与木马
- 试题答案:[['B']]
- 试题解析:传播方式:
1、通过邮件附件、程序下载等形式传播,因此A选项错误。
</p>
2、通过伪装网页登录过程,骗取用户信息进而传播。
3、通过攻击系统安全漏洞传播木马,大量黑客使用专门的黑客工具来传播木马。木马程序危害在于多数有恶意企图,例如占用系统资源,降低电脑效能,危害本机信息安全(盗取QQ账号、游戏账号甚至银行账号),将本机作为工具来攻击其他设备等,因此,C选项错误。
4、Sniffer 是用于拦截通过网络传输的TCP/IP/UDP/ICMP等数据包的一款工具,可用于分析网络应用协议,用于网络编程的调试、监控通过网络传输的数据、检测木马程序等,因此D选项错误。
本题只有B选项是正确的。
第 7 题
防火墙的工作层次是决定防火墙效率及安全的主要因素,以下叙述中,正确的是( )。
- (A) 防火墙工作层次越低,工作效率越高,安全性越高
- (B) 防火墙工作层次越低,工作效率越低,安全性越低
- (C) 防火墙工作层次越高,工作效率越高,安全性越低
- (D) 防火墙工作层次越高,工作效率越低,安全性越高
答案与解析
- 试题难度:一般
- 知识点:信息安全>防火墙技术
- 试题答案:[['D']]
- 试题解析:防火墙工作层次越低,工作效率越高,安全性越低。
防火墙工作层次越高,工作效率越低,安全性越高。
第 8 题
以下关于包过滤防火墙和代理服务防火墙的叙述中,正确的是( )。
- (A) 包过滤成本技术实现成本较高,所以安全性能高
- (B) 包过滤技术对应用和用户是透明的
- (C) 代理服务技术安全性较高,可以提高网络整体性能
- (D) 代理服务技术只能配置成用户认证后才建立连接
答案与解析
- 试题难度:一般
- 知识点:信息安全>防火墙技术
- 试题答案:[['B']]
- 试题解析:包过滤防火墙工作在网络协议IP层,它只对IP包的源地址、目标地址及相应端口进行处理,因此速度比较快,能够处理的并发连接比较多,缺点是对应用层的攻击无能为力,包过滤成本与它的安全性能没有因果关系,而应用程序和用户对于包过滤的过程并不需要了解,因此该技术对应用和用户是透明的,本题选择B选项。
代理服务器防火墙将收到的IP包还原成高层协议的通讯数据,比如http连接信息,因此能够对基于高层协议的攻击进行拦截。缺点是处理速度比较慢,能够处理的并发数比较少,所以不能提高网络整体性能,而代理对于用户认证可以设置。
第 9 题
王某买了一幅美术作品原件,则他享有该美术作品的( )。
- (A) 著作权
- (B) 所有权
- (C) 展览权
- (D) 所有权与其展览权
答案与解析
- 试题难度:容易
- 知识点:法律法规与标准化>知识产权人确定
- 试题答案:[['D']]
- 试题解析:
展览权是原件持有人的特有的权利,著作权人不能以发表权限制其权利(除非有约定)。
</p>
所有权是所有人依法对自己财产所享有的占有,使用,收益和处分的权利。
第 10 题
甲、乙两软件公司于2012年7月12日就其财务软件产品分别申请“用友”和 “用有”商标注册。两财务软件相似,甲第一次使用时间为2009年7月,乙第一次使用时间为2009年5月。此情形下,( )能获准注册。
- (A) “用友”
- (B) “用友”与“用有”都
- (C) “用有”
- (D) 由甲、乙抽签结果确定
答案与解析
- 试题难度:一般
- 知识点:法律法规与标准化>知识产权人确定
- 试题答案:[['C']]
- 试题解析:
商标注册是指商标所有人为了取得商标专用权,将其使用的商标,依照法律的注册条件、原则和程序,向商标局提出注册申请,商标局经过审核,准予注册的法律制度。 注册商标时使用的商标标识须具备可视特征,且不得与他人先取得的合法权力相冲突,不得违反公序良俗。 具备可视性(显著性),要求必须为视觉可感知,可以是平面的文字、图形、字母、数字,也可以是三维立体标志或者颜色组合以及上述要素的组合。显著性要求商标的构成要素必须便于区别。但怎样的文字、图形和三维标志是具有显著特征的,我国《商标法》一般是从反面作出禁止性规定,凡是不含有禁用要素的商标(如同中华人民共和国的国旗、国徽相同或相近似的标识),就被视为具备显著性。显著性特征一般是指易于识别,即不能相同或相似。相同是指用于同一种或类似商品上的两个商标的文字、图形、字母、数字、三维标志或颜色组合相同。读音相同也属于相同商标,如“小燕”与“小雁”、“三九”与“999”属于相同商标。近似是指在文字的字形、读音、含义或者图形的构图及颜色或者文字与图形的整体结构上,与注册商标相比,易使消费者对商品的来源产生误认的商标。如虎、豹、猫图案外观近似;“娃哈哈“与”娃娃哈“读音近似; “长城”与 “八达岭”,虽然读音、文字都不近似,但其所指的事物非常近似,其思想主题相同,也会引起消费者的误认。 不得与在先权利相冲突。在先权利是指在申请商标注册之前已有的合法权利。该题中两个商标违反了“显著性”和“不得与在先权利相冲突”两项。所以“用友”不能获取注册。
第 11 题
以下媒体中,( )是表示媒体,( )是表现媒体。
- (A) 图像
- (B) 图像编码
- (C) 电磁波
- (D) 鼠标
- (A) 图像
- (B) 图像编码
- (C) 电磁波
- (D) 鼠标
答案与解析
- 试题难度:一般
- 知识点:多媒体基础>媒体的种类(显示媒体)
- 试题答案:[['B'],['D']]
- 试题解析:
表示媒体:表示媒体指的是为了传输感觉媒体而人为研究出来的媒体,借助于此种媒体,能有效地存储感觉媒体或将感觉媒体从一个地方传送到另一个地方。如语言编码、电报码、条形码等。
表现媒体:表现媒体指的是用于通信中使电信号和感觉媒体之间产生转换用的媒体。如输入、输出设备,包括键盘、鼠标、显示器、打印机等。
第 12 题
( )表示显示器在横向(行)上具有的像素点数目。
- (A) 显示分辨率
- (B) 水平分辨率
- (C) 垂直分辨率
- (D) 显示深度
答案与解析
- 试题难度:容易
- 知识点:多媒体基础>多媒体技术基本概念
- 试题答案:[['B']]
- 试题解析:
分辨率分为水平分辨率和垂直分辨率,在大多数情况下两者是相等的,因此在技术指标中一般仅给出水平分辨率,其度量单位电视线也往往简称为线。水平指横向上具有的像素点数目,垂直指纵向上具有的像素点数目。
第 13 题
以下关于结构化开发方法的叙述中,不正确的是( )。
- (A) 将数据流映射为软件系统的模块结构
- (B) 一般情况下,数据流类型包括变换流型和事务流型
- (C) 不同类型的数据流有不同的映射方法
- (D) 一个软件系统只有一种数据流类型
答案与解析
- 试题难度:容易
- 知识点:软件工程>软件开发方法
- 试题答案:[['D']]
- 试题解析:面向数据流的设计是以需求分析阶段产生的数据流图为基础,按一定的步骤映射成软件结构,因此又称结构化设计。该方法由美国IBM公司L.Constantine和E.Yourdon等人于1974年提出,与结构化分析(SA)衔接,构成了完整的结构化分析与设计技术,是目前使用最广泛的软件设计方法之一。各种软件系统,不论DFD如何庞大和复杂,一般可分为变换型和事务型,一个软件系统既可以只有一种数据流类型,也可以是两种数据流类型。在结构化设计中,可以将数据流映射为软件系统的模块结构,不同类型的数据流有不同的映射方法。
第 14 题
模块A提供某个班级某门课程的成绩给模块B,模块B计算平均成绩、最高分和最低分,将计算结果返回给模块A,则模块B在软件结构图中属于( )模块。
- (A) 传入
- (B) 传出
- (C) 变换
- (D) 协调
答案与解析
- 试题难度:一般
- 知识点:软件工程>软件设计
- 试题答案:[['C']]
- 试题解析:传入模块:从下属模块取得数据,经处理再将其传送给上级模块。
传出模块:从上级模块取得数据,经处理再将其传送给下属模块。变换模块:从上级模块取得数据,进行特定的处理,转换成其他形式,再传送给上级模块。
第 15 题
( )软件成本估算模型是一种静态单变量模型,用于对整个软件系统进行估算。
- (A) Putnam
- (B) 基本COCOMO
- (C) 中级COCOMO
- (D) 详细COCOMO
答案与解析
- 试题难度:一般
- 知识点:项目管理>其它
- 试题答案:[['B']]
- 试题解析:
基本COCOMO是一种静态的单值模型,它使用以每千源代码行数(KLoC)来度量的程序大小来计算软件开发的工作量(及成本)。COCOMO可以应用于三种不同的软件项目:
</p>
有机项目——相对较小、较简单的软件项目,由较小的有经验的团队来完成,需求较少并且没有过分严格的限定。
中度分离项目——指中等规模(大小及复杂度)的软件项目,由不同经验水平的人组成的团队来完成,需求中既有严格的部分也有不太严格的部分。
嵌入式项目——指软件项目必须依赖于一套紧凑的硬件、软件以及符合操作的限制。
第 16 题
以下关于进度管理工具Gantt图的叙述中,不正确的是( )。
- (A) 能清晰地表达每个任务的开始时间、结束时间和持续时间
- (B) 能清晰地表达任务之间的并行关系
- (C) 不能清晰地确定任务之间的依赖关系
- (D) 能清晰地确定影响进度的关键任务
答案与解析
- 试题难度:一般
- 知识点:项目管理>Gant图与Pert图
- 试题答案:[['D']]
- 试题解析:Gantt图是一种简单的水平条形图,以日历为基准描述项目任务。水平轴表示日历时间线(如时、天、周、月和年等),每个条形表示一个任务,任务名称垂直地列在左边的列中,图中水平条的起点和终点对应水平轴上的时间,分别表示该任务的开始时间和结束时间,水平条的长度表示完成该任务所持续的时间。当日历中同一时段存在多个水平条时,表示任务之间的并发。
Gantt图能清晰地描述每个任务从何时开始,到何时结束,任务的进展情况以及各个任务之间的并行性。但是其缺点是不能清晰地反映出各个任务之间的依赖关系,难以确定整个项目的关键所在,也不能反映计划中有潜力的部分。
第 17 题
项目复杂性、规模和结构的不确定性属于( )风险。
- (A) 项目
- (B) 技术
- (C) 经济
- (D) 商业
答案与解析
- 试题难度:一般
- 知识点:项目管理>风险管理
- 试题答案:[['A']]
- 试题解析:
项目风险涉及到各种形式的预算、进度、人员、资源以及客户相关的问题,并且可能导致项目损失。
第 18 题
以下程序设计语言中,( )更适合用来进行动态网页处理。
- (A) HTML
- (B) LISP
- (C) PHP
- (D) JAVA/C++
答案与解析
- 试题难度:一般
- 知识点:程序设计语言>多种程序语言特点
- 试题答案:[['C']]
- 试题解析:
HTML:静态网页
LISP:一种基于λ演算的函数式编程语言
PHP :混合了C、Java、Perl以及PHP自创的语法。它可以比CGI或者Perl更快速地执行动态网页。
第 19 题
引用调用方式下进行函数调用,是将( )。
- (A) 实参的值传递给形参
- (B) 实参的地址传递给形参
- (C) 形参的值传递给实参
- (D) 形参的地址传递给实参
答案与解析
- 试题难度:一般
- 知识点:程序设计语言>传值与传址
- 试题答案:[['B']]
- 试题解析:在函数调用时,系统为形参准备空间,并把实参的值赋值到形参空间中,在调用结束后,形参空间将被释放,而实参的值保持不变,这就是传值传递方式。传值传递方式中实参与形参之间的数据传递是单向的,只能由实参传递给形参,因而即使形参的值在函数执行过程中发生了变化,也不会影响到实参值。在C语言中,当参数类型是非指针类型和非数组类型时,均采用传值方式。传地址方式把实参的地址赋值给形参,这样形参就可以根据地址值访问和更改实参的内容,从而实现双向传递。当参数类型是指针类型或数组类型时,均采用传地址方式。
第 20 题
编译程序对高级语言源程序进行编译的过程中,要不断收集、记录和使用源程序中一些相关符号的类型和特征等信息,并将其存入( )中。
- (A) 符号表
- (B) 哈希表
- (C) 动态查找表
- (D) 栈和队列
答案与解析
- 试题难度:一般
- 知识点:程序设计语言>编译与解释
- 试题答案:[['A']]
- 试题解析:符号表:符号表是一种用于语言翻译器(例如编译器和解释器)中的数据结构。在符号表中,程序源代码中的每个标识符都和它的声明或使用信息绑定在一起,比如其数据类型、作用域以及内存地址。
哈希表:也叫散列表,是根据关键码值(Key value)直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
</p>
动态查找表:动态查找表的表结构本身是在查找过程中动态生成的,即对于给定值key,若表中存在其关键字等于key的记录,则查找成功返回,否则插入关键字等于key的记录。
栈和队列:基本的数据结构。栈的基本特点是“后进先出”,而队列的基本特点是“先进先出”。
第 21 题
假设某计算机系统中资源R的可用数为6,系统中有3个进程竞争R,且每个进程都需要i个R,该系统可能会发生死锁的最小i值是( )。若信号量S的当前值为-2,则R的可用数和等待R的进程数分别为( )。
- (A) 1
- (B) 2
- (C) 3
- (D) 4
- (A) 0、0
- (B) 0、1
- (C) 1、0
- (D) 0、2
答案与解析
- 试题难度:一般
- 知识点:操作系统>死锁
- 试题答案:[['C'],['D']]
- 试题解析:当3个进程都占有2个R资源时,都需要再申请一个资源才能正常运行,此时会出现相互等待的状况。
信号量为负值,说明此时系统中已经没有R资源了,此负值也代表正在等待R的进程数。
第 22 题
某计算机系统页面大小为4K,若进程的页面变换表如下所示,逻辑地址为十六进制1D16H。该地址经过变换后,其物理地址应为十六进制( )。
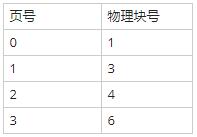
页式存储中的逻辑地址与物理地址之间的变换需要掌握变换的规则。
逻辑地址的构成是:逻辑页号+页内地址。
物理地址的构成是:物理块号+页内地址。
从构成可以看出逻辑地址与物理地址的页内地址是一样的,不同的是逻辑页号与物理块号。而这两者的关系,正是通过题目已给出的表来进行映射的。如逻辑页号1就对应着物理块号3。
所以题目告诉我们“逻辑地址为十六进制1D16H”时,我们先要把逻辑地址中的页号与页内地址分离。
通过什么条件分离呢?
题目中的“计算机系统页面大小为4K”,从这句话可以看出,页内地址是二进制的12位 (4K=212)。二进制12位对应十六进制3位。
所以D16H是页内地址。页号也就是1了。通过页表查询到物理块号:3。所以物理地址是:3D16H。
第 23 题
若某文件系统的目录结构如下图所示,假设用户要访问文件fault.swf,且当前工作目录为swshare,则该文件的相对路径和绝对路径分别为( )。
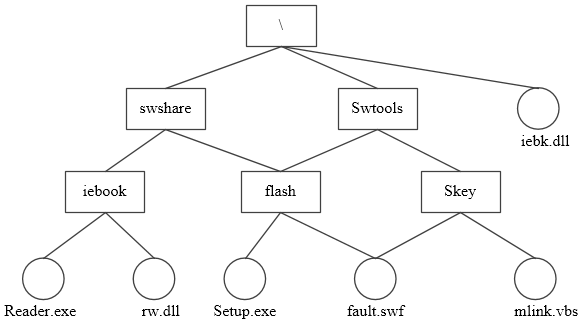
- (A) swshare\flash\和\flash\
- (B) flash\和\swshare\flash\
- (C) \swshare\flash\和flsah\
- (D) \flash\和\swshare\flash\
答案与解析
- 试题难度:一般
- 知识点:操作系统>绝对路径与相对路径
- 试题答案:[['B']]
- 试题解析:相对路径是相对于当前所在的目录开始的路径,绝对路径是从根开始的路径。本题的位置为swshare,要访问的fault.swf文件在flash目录下,所以相对路径应该为flash\,绝对路径应为\swshare\flash\。
第 24 题
在数据库设计过程中,设计用户外模式属于( );数据的物理独立性和数据的逻辑独立性是分别通过修改( )来完成的。
- (A) 概念结构设计
- (B) 物理设计
- (C) 逻辑结构设计
- (D) 数据库实施
- (A) 模式与内模式之间的映像、外模式与模式之间的映像
- (B) 外模式与内模式之间的映像、外模式与模式之间的映像
- (C) 外模式与模式之间的映像、模式与内模式之间的映像
- (D) 外模式与内模式之间的映像、模式与内模式之间的映像
答案与解析
- 试题难度:一般
- 知识点:数据库技术基础>数据库的三级模式结构与两级映像
- 试题答案:[['C'],['A']]
- 试题解析:数据库的结构是三级模式结构,它包括外模式、模式和内模式,其中用户级对应外模式,概念级对应模式,物理级对应内模式。模式又称概念模式或逻辑模式。是对数据库中全部数据的逻辑结构和特征的总体描述。
外模式又称子模式。它是某个或某几个用户所看到的数据库的数据视图,是与某一应用有关的数据的逻辑表示。
内模式又称存储模式,它是数据库中全体数据的内部表示或底层描述,是数据库最低一级的逻辑描述,它描述了数据在存储介质上的存储方式和物理结构,对应着实际存储在外存储介质上的数据库。
综上所述,可知数据库的视图与基本表之间通过建立外模式到模式之间的映像,保证数据的逻辑独立性;而基本表与存储文件之间通过建立模式到内模式之间的映像,保证数据的物理独立性
外模式对应于视图和部分基本表,模式对应于基本表,内模式对应于存储文件。
逻辑结构设计的主要任务为:
确定数据模型
将E-R图转换为指定的数据模型
确定完整性约束
确定用户视图
第 25 题
为了保证数据库中数据的安全可靠和正确有效,系统在进行事务处理时,对数据的插入、删除或修改的全部有关内容先写入( );当系统正常运行时,按一定 的时间间隔,把数据库缓冲区内容写入( ):当发生故障时,根据现场数据内容及相关文件来恢复系统的状态。
- (A) 索引文件
- (B) 数据文件
- (C) 日志文件
- (D) 数据字典
- (A) 索引文件
- (B) 数据文件
- (C) 日志文件
- (D) 数据字典
答案与解析
- 试题难度:一般
- 知识点:数据库运行与管理>日志文件
- 试题答案:[['C'],['B']]
- 试题解析:在事务处理的过程中,DBMS把事务开始、事务结束以及对数据库的插入、删除和修改的每一次操作写入日志文件。一旦发生故障,DBMS的恢复子系统利用日志文件撤销事务对数据库的改变,回退到事务的初始状态。因此,DBMS利用日志文件来进行事务故障恢复和系统故障恢复,并可协助后备副本进行介质故障恢复。
第 26 题
假设系统中有运行的事务,若要转储全部数据库应采用( )方式。
- (A) 静态全局转储
- (B) 静态增量转储
- (C) 动态全局转储
- (D) 动态增量转储
答案与解析
- 试题难度:一般
- 知识点:数据库运行与管理>数据备份
- 试题答案:[['C']]
- 试题解析:静态转储和动态转储。静态转储是指在转储期间不允许对数据库进行任何存取、修改操作;动态转储是在转储期间允许对数据库进行存取、修改操作,因此,转储和用户事务可并发执行。海量转储和增量转储。海量转储是指每次转储全部数据;增量转储是指每次只转储上次转储后更新过的数据。
第 27 题
给定关系模式R(U,F),U={A,B,C,D},函数依赖集F={AB→C,CD→B}。关系模式R( ),且分别有( )。若将R分解成ρ={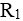 (ABC),
(ABC),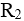 (CDB)},则分解ρ( )。
(CDB)},则分解ρ( )。
- (A) 只有1个候选关键字ACB
- (B) 只有1个候选关键字BCD
- (C) 有2个候选关键字ACD和ABD
- (D) 有2个候选关键字ACB和BCD
- (A) 0个非主属性和4个主属性
- (B) 1个非主属性和3个主属性
- (C) 2个非主属性和2个主属性
- (D) 3个非主属性和1个主属性
- (A) 具有无损连接性、保持函数依赖
- (B) 具有无损连接性、不保持函数依赖
- (C) 不具有无损连接性、保持函数依赖
- (D) 不具有无损连接性、不保持函数依赖
答案与解析
- 试题难度:一般
- 知识点:关系数据库>规范化的基础概念
- 试题答案:[['C'],['A'],['C']]
- 试题解析:求候选码:关系模式码的确定,设关系模式R<U,F>:1、首先应该找出F中所有的决定因素,即找出出现在函数依赖规则中“→”左边的所有属性,组成集合该题中
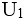 ;2、再从
;2、再从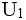 中找出一个属性或属性组K,运用Armstrong公理系统及推论,使得K→U,而K真子集K′→U不成立;这样就得到了关系模式R的一个候选码,找遍
中找出一个属性或属性组K,运用Armstrong公理系统及推论,使得K→U,而K真子集K′→U不成立;这样就得到了关系模式R的一个候选码,找遍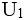 属性的所有组合,重复过程(2),最终得到关系模式R的所有候选码。
属性的所有组合,重复过程(2),最终得到关系模式R的所有候选码。
={A、B、C、D},若K=A时,运用Armstrong公理系统及推论都不能推出A→{A、B、C、D};若K=ABD时,由于AB→C,利用Armstrong公理系统 可以得出ABD→CD(增广率),从而得出
ABD→ABCD;同样也可以推出ACD→ABCD;因此,关系R的候选码为:ABD和ACD
由于候选码为:ABD和ACD。所以U中没有非主属性,即都为主属性
依据无损连接的定理: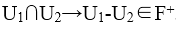 或者
或者 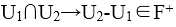 ;该题中
;该题中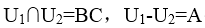 ;
;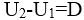 ,而
,而 ,所以该分解都不具备无损连接;
,所以该分解都不具备无损连接;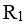 :AB→C,CD→B 被F所蕴含,因此该分解保持函数依赖性
:AB→C,CD→B 被F所蕴含,因此该分解保持函数依赖性
第 28 题
给定关系模式R(A,B,C,D)和关系S(A,C,D,E),对其进行自然连接运算,R⋈S后的属性列为( )个;与σR.B>S.E(R⋈S)等价的关系代数表达式为( )。
与 σR.B>S.E(R⋈S) 等价的SQL语句如下:
Select( )From A,B
Where ( );
- (A) 4
- (B) 5
- (C) 6
- (D) 8
- (A)
- (B)
- (C)
- (D)
- (A) R.A, R.B, R.C, R.D, S.E
- (B) R.A, R.C, R.D, S.C, S.D, S.E
- (C) A,B,C,D,A,C,D,E
- (D) R.A, R.B, R.C, R.D, S.A, S.C, S.D, S.E
- (A) R.A=S.A OR R.B=S.E OR R.C=S.C OR R.D=S.D
- (B) R.A=S.A OR R.B>S.E OR R.C=S.C OR R.D=S.D
- (C) R.A=S.A AND R.B=S.E AND R.C=S.C AND R.D=S.D
- (D) R.A=S.A AND R.B>S.E AND R.C=S.C AND R.D=S.D
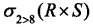
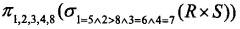
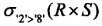
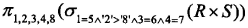
答案与解析
- 试题难度:一般
- 知识点:关系数据库>关系代数与SQL语句的转换
- 试题答案:[['B'],['B'],['A'],['D']]
- 试题解析:自然连接是一种特殊的等值连接,要求两个关系中进行比较的分量必须是相同的属性组,并且在结果集中将重复属性列去掉。由于R和S关系的列A、C、D列是重复的,所以在自然连接运算中应该去除重复的列,所以进行自然连接后的列数为:5R.B是R和S进行笛卡尔积运算结果的第2列,S.E是R和S进行笛卡尔积运算结果的第8列,列名可以用数字表示,其表达式为:2>8 。由于自然连接要消除重复的列,所以要进行投影运算,选择1、2、3、4、8列;其比较的列也要求相等,所以选择运算的表达式应该为R.A=S.A∧R.C=S.C∧R.D=S.D,即1=5∧3=6∧4=7 。再综合整个表达式,所以该题正确的选项为:B
SELECT 语句的语法为:SELECT <列表达式> FROM <表名> WHERE<条件表达式>。列表达式应该是指出要保留的列,条件表达式是逻辑与,所以应该使用AND,所以正确选项应该为A,D
第 29 题
假定某企业根据2014年5月员工的出勤率、岗位、应扣款得出的工资表如下:
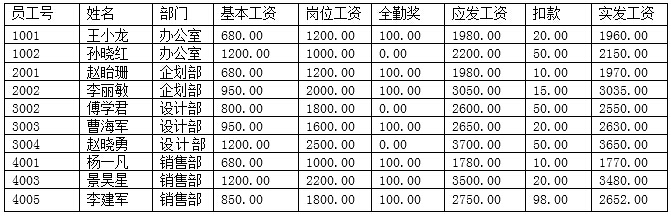
a.查询部门人数大于2的部门员工平均工资的SQL语句如下:
SELECT ( )
FROM工资表
( )
( )
b.将设计部员工的基本工资增加10%的SQL语句如下 Update工资表
Update 工资表
( )
( );
- (A) 部门,AVG (应发工资)AS平均工资
- (B) 姓名,AVG (应发工资)AS平均工资
- (C) 部门,平均工资AS AVG (应发工资)
- (D) 姓名,平均工资AS AVG (应发工资)
- (A) ORDER BY 姓名
- (B) ORDER BY 部门
- (C) GROUP BY 姓名
- (D) GROUP BY 部门
- (A) WHERE COUNT(姓名)> 2
- (B) WHERE COUNT(DISTINCT(部门))> 2
- (C) HAVING COUNT(姓名)> 2
- (D) HAVING COUNT(DISTINCT(部门))> 2
- (A) Set基本工资=基本工资*'1.1'
- (B) Set基本工资=基本工资*1.1
- (C) Insert基本工资=基本工资*'1.1'
- (D) Insert基本工资=基本工资*1.1
- (A) HAVING部门=设计部
- (B) WHERE '部门'='设计部'
- (C) WHERE部门='设计部'
- (D) WHERE部门=设计部
答案与解析
- 试题难度:一般
- 知识点:SQL语言>SELECT语句
- 试题答案:[['A'],['D'],['C'],['B'],['C']]
- 试题解析:SELECT 语句(分组)的语法为:SELECT <列表达式>
FROM <表名>
GROUP BY <列名> HAVING <条件表达式>
该题要求按部门统计平均工资,所以需要使用聚集函数:AVG,由于AVG统计列没有列名,需要使用AS给AVG统计的列进行重命名。按部门统计需要使用GROUP BY语句来对数据进行分组,所以GROUP BY后面应该跟随的列名为:部门。基于分组指定条件一般使用HAVING语句,要求统计部门人数大于2,需要使用聚集函数:COUNT
UPDATE 语句的语法为:UPDATE<表名> SET 列名=值表达式( ,列名=值表达式) [WHERE 条件表达式],在表达式中数值类型的数据,不需要使用单引号,字符类型或日期类型需要使用单引号。
第 30 题
事务是一个操作序列,这些操作( )。“当多个事务并发执行时,任何一个事务的更新操作直到其成功提交前的整个过程,对其他事务都是不可见的。”这一性质通常被称为事务的( )性质。
- (A) “可以做,也可以不做”,是数据库环境中可分割的逻辑工作单位
- (B) “可以只做其中的一部分”,是数据库环境中可分割的逻辑工作单位
- (C) “要么都做,要么都不做”,是数据库环境中可分割的逻辑工作单位
- (D) “要么都做,要么都不做”,是数据库环境中不可分割的逻辑工作单位
- (A) 原子性
- (B) 一致性
- (C) 隔离性
- (D) 持久性
答案与解析
- 试题难度:容易
- 知识点:事务管理>事务的特性
- 试题答案:[['D'],['C']]
- 试题解析:事务是一个操作序列,这些操作“要么都做,要么都不做”。事务是数据库环境中不可分割的逻辑工作单位。原子性是指事务要么全部执行完,要么不被执行,与现实业务相对应;一致性指事务的执行结果要与现实业务产生的信息相一致,数据库也就处于一致性状态;隔离性指多个事务并发执行时不能相互干扰造成结果的错误,即当多个事务并发执行时,任一事务的更新操作,在其成功提交之前,对其他事务都是不可见的;持久性指事务一旦提交,其执行结果应被存入数据库而不被丢失。
第 31 题
能实现UNIQUE约束功能的索引是( );针对复杂的约束,应采用( ) 来实现。
- (A) 普通索引
- (B) 聚簇索引
- (C) 唯一值索引
- (D) 复合索引
- (A) 存储过程
- (B) 触发器
- (C) 函数
- (D) 多表查询
答案与解析
- 试题难度:一般
- 知识点:SQL语言>表及相关约束
- 试题答案:[['C'],['B']]
- 试题解析:UNIQUE 约束唯一标识数据库表中的每条记录。UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。触发器是一种特殊类型的存储过程,是通过事件触发而执行的。触发器使每个站点在有数据修改时,自动强制执行其业务规则,并且可以用于SQL 约束、默认值和规则的完整性检查。
第 32 题
设计操作系统时不需要考虑的问题是( )。
- (A) 计算机系统中硬件资源的管理
- (B) 计算机系统中软件资源的管理
- (C) 用户与计算机之间的接口
- (D) 语言编译器的设计实现
答案与解析
- 试题难度:一般
- 知识点:操作系统>其它
- 试题答案:[['D']]
- 试题解析:OS作为用户与计算机硬件之间的接口。OS作为计算机系统的资源管理者,可以管理计算机的软硬件资源。
第 33 题
数据库的安全机制中,通过GRANT语句实现的是( );通过建立( ) 使用户只能看到部分数据,从而保护了其他数据;通过提供( )供第三方开发人 员调用进行数据更新,从而保证数据库的关系模式不被第三方所获取。
- (A) 用户授权
- (B) 许可证
- (C) 加密
- (D) 回收权限
- (A) 索引
- (B) 视图
- (C) 存储过程
- (D) 触发器
- (A) 索引
- (B) 视图
- (C) 存储过程
- (D) 触发器
答案与解析
- 试题难度:容易
- 知识点:SQL语言>其它
- 试题答案:[['A'],['B'],['C']]
- 试题解析:GANT语句是给用户授权的语句,其语法格式为: GRANT <权限>[,<权限>][ON<对象类型><对象名>] TO<用户>[,<用户>]··· [WITH GRANT OPTION];视图是从一个或多个表或视图中导出的表,其结构和数据是建立在对表的查询基础上。利用视图可以集中数据、简化和定制不同用户对数据库的不同数据要求;视图可以使用户只关心其感兴趣的某些特定数据及其所负责的特定任务,而那些不需要的或者无用的数据则不在视图中显示;视图大大地简化了用户对数据的操作;视图可以让不同的用户以不同的方式看到不同或者相同的数据集;视图提供了一个简单而有效地安全机制。
存储过程是指保存的 SQL 语句集合,可以接受和返回用户提供的参数,存储过程存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。
第 34 题
嵌入式SQL中,若查询结果为多条记录时,将查询结果交予主语言处理时, 应使用的机制是( ),引入( )来解决主语言无空值的问题。
- (A) 主变量
- (B) 游标
- (C) SQLCA
- (D) 指示变量
- (A) 主变量
- (B) 游标
- (C) SQLCA
- (D) 指示变量
答案与解析
- 试题难度:一般
- 知识点:SQL语言>嵌入式SQL
- 试题答案:[['B'],['D']]
- 试题解析:SQL通信区:SQLCA 向主语言传递SQL语句执行的状态信息,使主语言能够根据此信息控制程序流程主变量:也称共享变量,主语言通过主变量向SQL语句提供参数,主变量由主语言的程序定义,并用SQL的DECLARE语句说明,为了与SQL属性名相区别,需要在主变量前加 :
游标:SQL语言是面向集合的,一条SQL语句可产生或处理多条记录。而主语言是面向记录的,一组主变量一次只能存一条记录。所以,引入游标,通过移动游标指针可以决定获取哪一条记录。
第 35 题
事务
T1 中有两次查询学生表中的男生人数,在这两次查询执行中间,事务
T2 对学生表中加入了一条男生记录,导致
T1 两次查询的结果不一致,此类问题属于( ),为解决这一问题,应采用的隔离级别是( )。
- (A) 可重复读
- (B) 读脏数据
- (C) 丢失修改
- (D) 幻影现象
- (A) Read Uncommitted
- (B) Read Committed
- (C) Repeatable Read
- (D) Serializable
答案与解析
- 试题难度:一般
- 知识点:事务管理>隔离级别
- 试题答案:[['D'],['D']]
- 试题解析:并发操作可能导致:丢失更新、不可重复读、读“脏”数据等问题。丢失更新是指两个事务
T1 和
T2 读入同一数据并修改,
T2 提交的结果破坏了
T1 提交的结果,导致
T1 的修改被丢失。
不可重复读是指事务
T1 读取数据后,事务
T2 执行更新操作,是
T1 无法再现前一次读取结果。
(1)事务
T1 ,事务
T2 对其做了修改,事务
T1 再次读。
(2)事务
T1 按一定条件从数据库中读,事务
T2 删除了其中部分记录,当
T1 再次按相同的条件读。
(3)事务
T1 按一定条件从数据库中读,事务
T2 插入了一些记录,当
T1 再次按照相同条件读。
读“脏”数据是指事务
T1 修改某一数据并将其写回磁盘,事务
T2 读取同一数据后,
T1 由于某种原因被撤销,这时
T1 修改过的数据恢复原值,
T2 读到的数据就与数据库中的数据不一致,即
T2 读到了“脏”数据。
为了避免出现并发的几种情况,在标准SQL规范中,定义了4个事务隔离级别,不同的隔离级别对事务的处理不同。
未授权读取:也称为读未提交(Read Uncommitted):允许脏读取,但不允许更新丢失。如果一个事务已经开始写数据,则另外一个事务则不允许同时进行写操作,但允许其他事务读此行数据。该隔离级别可以通过“排它写锁”实现。
授权读取:也称为读提交(Read Committed):允许不可重复读取,但不允许脏读取。这可以通过“瞬间共享读锁”和“排它写锁”实现。读取数据的事务允许其他事务继续访问该行数据,但是未提交的写事务将会禁止其他事务访问该行。
可重复读取(Repeatable Read):禁止不可重复读取和脏读取,但是有时可能出现幻影数据。这可以通过“共享读锁”和“排它写锁”实现。读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务。
序列化(Serializable):提供严格的事务隔离。它要求事务序列化执行,事务只能一个接着一个地执行,但不能并发执行。如果仅仅通过“行级锁”是无法实现事务序列化的,必须通过其他机制保证新插入的数据不会被刚执行查询操作的事务访问到。
隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。
第 36 题
两个函数依赖集F和G等价是指( )。
- (A) F = G
- (B) F+= G+
- (C) F → G
- (D) G → F
答案与解析
- 试题难度:容易
- 知识点:关系数据库>规范化的基础概念
- 试题答案:[['B']]
- 试题解析:系模式R(U,F)中为F所逻辑蕴含的函数依赖的全体称为F的闭包,记为F+
第 37 题
通过反复使用保证无损连接性,又保持函数依赖的分解,能保证分解之后的关系模式至少达到( )。
- (A) 1NF
- (B) 2NF
- (C) 3NF
- (D) BCNF
答案与解析
- 试题难度:一般
- 知识点:关系数据库>1NF至4NF
- 试题答案:[['C']]
- 试题解析:(1) 分解具有无损连接性和分解保持函数依赖是两个互相独立的标准。具有无损连接性的分解不一定保持函数依赖。因此,关系模式的一个分解可能是保持函数依赖的,可能是具有无损连接性的,也可能是既具有无损连接性又保持函数依赖的。(2) 若要求分解具有无损连接性,那么模式分解一定可以达到4NF。
(3) 若要求分界保持函数依赖,那么模式分解可以达到3NF,但不一定能达到BCNF。
(4) 若要求分解既具有无损连接性,又保持函数依赖,则模式分解可以达到3NF,但不一定能达到BCNF。
第 38 题
在设计分E-R图阶段,人力部门定义的员工实体具有属件:员工号,姓名,性别和出生日期;教学部门定义的教师实体具有属性;教工号,姓名和职称.、这种情况属于( ),合并E-R图时,,解决这一冲突的方法是( )。
- (A) 属性冲突
- (B) 命名冲突
- (C) 结构冲突
- (D) 实体冲突
- (A) 员工和教师实体保持各自属性不变
- (B) 员工实体中加入职称属性,删除教师实体
- (C) 将教师实体所有属性并入员工实体,删除教师实体
- (D) 将教师实体删除
答案与解析
- 试题难度:一般
- 知识点:数据库设计>概念结构设计
- 试题答案:[['C'],['B']]
- 试题解析:属性冲突:同一属性可能会存在于不同的分E-R图,由于设计人员不同或是出发点不同,属性的类型、取值范围及数据单位等可能会不一致。命名冲突:相同意义的属性,在不同的分E-R图上有着不同的命名,或者是名称相同的属性在不同的分E-R图中代表着不同的意义。
结构冲突:同一实体在不同的分E-R图中有不同的属性,同一对象在某分E-R图中被抽象为实体而在另一分E-R图中又被抽象为属性。
该题中同一个员工,在员工和教师中被抽象出了不同的属性,应为结构冲突。
在分E-R图的合并过程中要对其进行优化,具体可以从以下几个方面进行:
(1)实体类型的合并:两个具有1:1联系或1:n联系的实体,可以予以合并,使实体个数减少,有利于减少将来数据库操作过程中的连接开销。
(2)冗余属性的消除:各分E-R图中的属性一般不存在冗余,但合并后就可能出现冗余。因为合并后的E-R图中的实体继承了合并前实体在分E-R图中的全部属性,而属性间可能存在冗余,即某一属性可以由其他属性确定。
(3)冗余联系的消除:在分E-R图合并过程中,可能会出现实体联系的环状结构,即某一实体A与另一实体B间有直接联系,同时A又通过其他实体与实体B发生间接联系。如果直接联系可以通过间接联系表达,可消除直接联系。
针对本题的合并,应该考虑实体类型的合并,即将一个实体删除,在对应的实体中增加相关的属性。由于教师实体应是员工实体的一个类型,所以合并时,应该将教师实体删除,保留员工实体。
第 39 题
某企业的E-R图中,职工实体的属性有:职工号、姓名、性别,出生日期,电话和所在部门,其中职工号为实体标识符,电话为多值属性,离退休职工所在部门为离退办,在逻辑设计阶段,应将职工号和电话单独构造一个关系模式,该关系模式为( );因为离退休职工不参与企业的绝大部分业务,应将这部分职工独立建立一个离退休职工关系模式,这种处理方式称为( )。
- (A) 1NF
- (B) 2NF
- (C) 3NF
- (D) 4NF
- (A) 水平分解
- (B) 垂直分解
- (C) 规范化
- (D) 逆规范化
答案与解析
- 试题难度:一般
- 知识点:关系数据库>1NF至4NF
- 试题答案:[['D'],['A']]
- 试题解析:
若关系模式R∈1NF,R的每个非平凡多值依赖X→→Y且Y⊊X时,X必含有码,则关系模式R(U,F)∈4NF;在该题中电话为多值属性,也就是说给定一个职工号,就会有多个电话与之对应。
将离退休职工单独处理,是依据一定的条件从职工关系中分解出来,是一种水平方式的分解。
第 40 题
分布式数据库系统除了包含集中式数据库系统的模式结构之外,还增加了几个模式级别,其中( )定义分布式数据库中数据的整体逻辑结构,使得数据如同没有分布一样。
- (A) 全局外模式
- (B) 全局概念模式
- (C) 分片
- (D) 分布
答案与解析
- 试题难度:一般
- 知识点:数据库发展和新技术>全局概念层
- 试题答案:[['B']]
- 试题解析:全局概念模式:描述分布式数据库全局数据的逻辑结构,是分布式数据库的全局概念视图。与集中式数据库的概念视图的定义相似,全局概念模式应包含模式名、属性名以及每种属性的数据类型的定义和长度。分片模式:描述全局数据逻辑划分的视图,它是全局数据的逻辑结构根据某种条件的划分,每一个逻辑划分就是一个片段或称为分片。
分配模式:描述局部逻辑的局部物理结构是划分后的片段(或分片)的物理分配视图。与集中式数据库物理存储结构的概念不同,这种分配模式是全局概念层的内容。
第 41 题
以下关于面向对象数据库的叙述中,不正确的是( ) 。
- (A) 类之间可以具有层次结构
- (B) 类内部可以具有嵌套层次结构
- (C) 类的属性不能是类
- (D) 类包含属性和方法
答案与解析
- 试题难度:容易
- 知识点:数据库发展和新技术>面向对象数据模型
- 试题答案:[['C']]
- 试题解析:对象嵌套式面向对象数据库系统中的一个重要概念。在面向对象数据模型中,对象的一个属性可以是一个单一值,也可以是一个来自于值域的值集,即一个对象的属性可以是一个对象,形成嵌套关系,产生一个嵌套层次结构。对象:是基本运行时的实体,既包括数据(属性),也包括(行为)
类:类所包含的方法和数据描述一组对象的共同行为和属性;类是在对象之上的抽象,对象是类的具体化,是类的实例。
第 42 题
以下关于数据仓库的叙述中,不正确的是( )。
- (A) 数据仓库是商业智能系统的基础
- (B) 数据仓库是面向业务的,支持联机事务处理(OLTP)
- (C) 数据仓库是面向分析的,支持联机分析处理(0LAP)
- (D) 数据仓库中的数据视图往往是多维的
答案与解析
- 试题难度:一般
- 知识点:数据库技术基础>数据仓库的数据模式
- 试题答案:[['B']]
- 试题解析:数据仓库是为企业所有级别的决策制定过程提供支持的所有类型数据的战略集合。它是单个数据存储,出于分析性报告和决策支持的目的而创建。 为企业提供需要业务智能来指导业务流程改进和监视时间、成本、质量和控制。数据库是面向事务的设计,数据仓库是面向主题设计的。
第 43 题
当不知道数据对象有哪些类型时,可以使用( )是的同类数据对象与其他类型数据对象分离。
- (A) 分类
- (B) 聚类
- (C) 关联规则
- (D) 回归
答案与解析
- 试题难度:一般
- 知识点:数据库技术基础>数据挖掘最常用的技术
- 试题答案:[['B']]
- 试题解析:将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。聚类与分类的不同在于,聚类所要求划分的类是未知的。
回归分析:反映了数据库中数据的属性值的特性,通过函数表达数据映射的关系来发现属性值之间的依赖关系。它可以应用到对数据序列的预测及相关关系的研究中去。
关联规则:是隐藏在数据项之间的关联或相互关系,即可以根据一个数据项的出现推导出其他数据项的出现。
第 44 题
IP地址块155.32.80.192/26包含了( )个主机地址,以下IP地址中,不属于这个网络的地址是( )。
- (A) 15
- (B) 32
- (C) 62
- (D) 64
- (A) 155.32.80.202
- (B) 155.32.80.195
- (C) 155.32.80.253
- (D) 155.32.80.191
答案与解析
- 试题难度:一般
- 知识点:计算机网络>IP地址与子网划分
- 试题答案:[['C'],['D']]
- 试题解析:变长子网的可用主机数计算公式为2n-2(n为表示主机的位数)/26即主机位为32-26=6,所以可用主机地址为64-2=62。
用IP地址155.32.80.192与子网掩码进行逻辑与运算得出该IP地址所在的网络号为:155.32.80.192;所在网段的广播地址为:155.32.80.255;所以与该IP地址不在同一网段的是选项D
第 45 题
校园网链接运营商的IP地址为202.117.113.3/30,本地网关的地址为192.168.1.254/24,如果本地计算机采用动态地址分配,在下图中应如何配置?( )。
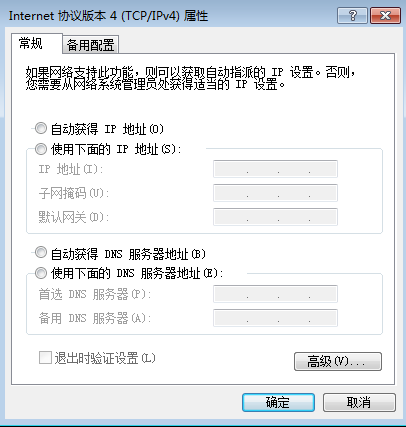
- (A) 选取“自动获得IP地址”
- (B) 配置本地计算机IP地址为192.168.1.X
- (C) 配置本地计算机IP地址为202.115.113.X
- (D) 在网络169.254.X.X中选取一个不冲突的IP地址
答案与解析
- 试题难度:容易
- 知识点:计算机网络>IP地址与子网划分
- 试题答案:[['A']]
- 试题解析:
当选择自动获得IP地址时,表示计算机采用动态获取IP地址,计算机从DHCP服务器上获取IP地址以及相关的项目。
第 46 题
某用户在使用校园网中的一台计算机访问某网站时,发现使用域名不能访问该网站,但是使用该网站的IP地址可以访问该网站,造成该故障产生的原因有很多,其中不包括( )。
- (A) 该计算机设置的本地DNS服务器工作不正常
- (B) 该计算机的DNS服务器设置错误
- (C) 该计算机与DNS服务器不在同一子网
- (D) 本地DNS服务器网络连接中断
答案与解析
- 试题难度:一般
- 知识点:计算机网络>DNS与DHCP应用
- 试题答案:[['C']]
- 试题解析:使用IP地址能访问,但使用域名不能访问,说明域名解析为IP地址的过程出现问题。但该题的选项C明显是不正确的选项,只要计算机能与DNS服务器通信,且DNS服务正常就可以进行名称解析,与计算机和DNS在不在同一网络无关。
第 47 题
中国自主研发的3G通信标准是( )。
- (A) CDMA2000
- (B) TD-SCDMA
- (C) WCDMA
- (D) WiMAX
答案与解析
- 试题难度:一般
- 知识点:计算机网络>3G与4G标准
- 试题答案:[['B']]
- 试题解析:W-CDMA:英文名称是Wideband Code Division Multiple Access,中文译名为宽带码分多址,它可支持384kbps到2Mbps不等的数据传输速率,支持者主要以GSM系统为主的欧洲厂商。CDMA2000:亦称CDMA Multi-Carrier,由美国高通北美公司为主导提出,摩托罗拉、Lucent和后来加入的韩国三星都有参与,韩国现在成为该标准的主导者。TD-SCDMA:该标准是由中国独自制定的3G标准,由于中国的庞大的市场,该标准受到各大主要电信设备厂商的重视,全球一半以上的设备厂商都宣布可以支持TD-SCDMA标准。
第 48 题
Cloud computing is a phrase used to describe a variety of computing concepts that involve a large number of computers( )through a real-time communication network such as the Internet. In science, cloud computing is a( )for distributed computing over a network, and means the( )to run a program or application on many connected computers at the same time.
The architecture of a cloud is developed at three layers: infrastructure, platform, and application, The infrastructure layer is built with virtualized computer, storage, and network resources. The platform layer is for general-purpose and repeated usage of the collection of software resources. The application layer is formed with a collection of all needed software modules for SaaS applications. The infrastructure layer serves as the( )for building the platform layer of the cloud. In turn, the platform layer is a foundation for implementing the( )layer for SaaS applications.
- (A) connected
- (B) implemented
- (C) optimized
- (D) Virtualized
- (A) replacement
- (B) switch
- (C) substitute
- (D) synonym(同义词)
- (A) ability
- (B) approach
- (C) function
- (D) method
- (A) network
- (B) foundation
- (C) software
- (D) hardware
- (A) resource
- (B) service
- (C) application
- (D) software
答案与解析
- 试题难度:一般
- 知识点:专业英语>专业英语
- 试题答案:[['A'],['D'],['A'],['B'],['C']]
- 试题解析:
云计算是用来描述各种计算概念的短语,包括大量计算机通过网络相互连接以实现分布计算,意思是同时在很多互联的计算机上运行程序或应用的能力。 云的架构分为基础设施层、平台层和应用层三层。基础设施层由虚拟计算、存储和网络资源构成。平台层用于一组软件资源重复使用的通用目的。应用层由一组所需的软件模块构成即软件即服务(SaaS)。基础设施层作为构建平台层的基础。相反,平台层是应用层的基础,为SaaS应用实现应用层。