200611软设上午真题
第 1 题
若内存按字节编址,用存储容量为32K×8比特的存储器芯片构成地址编号AOOOOH至DFFFFH的内存空间,则至少需要()片。
- (A) 4
- (B) 6
- (C) 8
- (D) 10
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[C]]
- 试题解析:
本题考查内存容量的计算。
给定起、止地址码的内存容量=终止地址-起始地址+1。
将终止地址加1等于E000H,再减去起始地址,即E0000H-A0000H=40000H。十六进制的(40000)16=218。
组成内存储器的芯片数量=内存储器的容量/单个芯片的容量。
218/(32*210)=218/215=23。
第 2 题
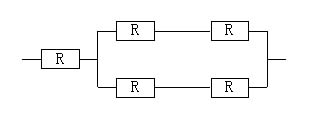
某计算机系统由下图所示的部件构成,假定每个部件的千小时可靠度R均为0.9,则该系统的千小时可靠度约为()。
- (A) 0.882
- (B) 0.867
- (C) 0.9
- (D) 0.99
答案与解析
- 试题难度:一般
- 知识点:非网络知识>计算机硬件基础
- 试题答案:[[B]]
- 试题解析:
本题考查系统可靠度的概念。
串联部件的可靠度=各部件的可靠度的乘积。
并联部件的可靠度=1-各部件失效率的乘积。
题目中给出的系统由两个部件分别串联然后并联,最好将并联的组成再与一个部件串联,要求解这类问题,应该首先计算出并联中的串联,计算结果为 0.9*0.9,如何两部分并联,计算结果为(1-(1-0.9*0.9)*(1-0.9*0.9)),最后再串联,计算结果为 0.9*(1-(1-0.9*0.9)*(1-0.9*0.9))=0.867。
第 3 题
设指令由取指、分析、执行3个子部件完成,每个子部件的工作周期均为△t.采用常规标量单流水线处理机。若连续执行10条指令,则共需时间()△t。
- (A) 8
- (B) 10
- (C) 12
- (D) 14
答案与解析
- 试题难度:容易
- 知识点:
- 试题答案:[['C']]
- 试题解析:
本题考查指令流水的概念。
顺序执行时,每条指令都需三步才能执行完,没有重叠。
采用常规标量单流水线处理机连续执行10条指令的时空图如下图所示:
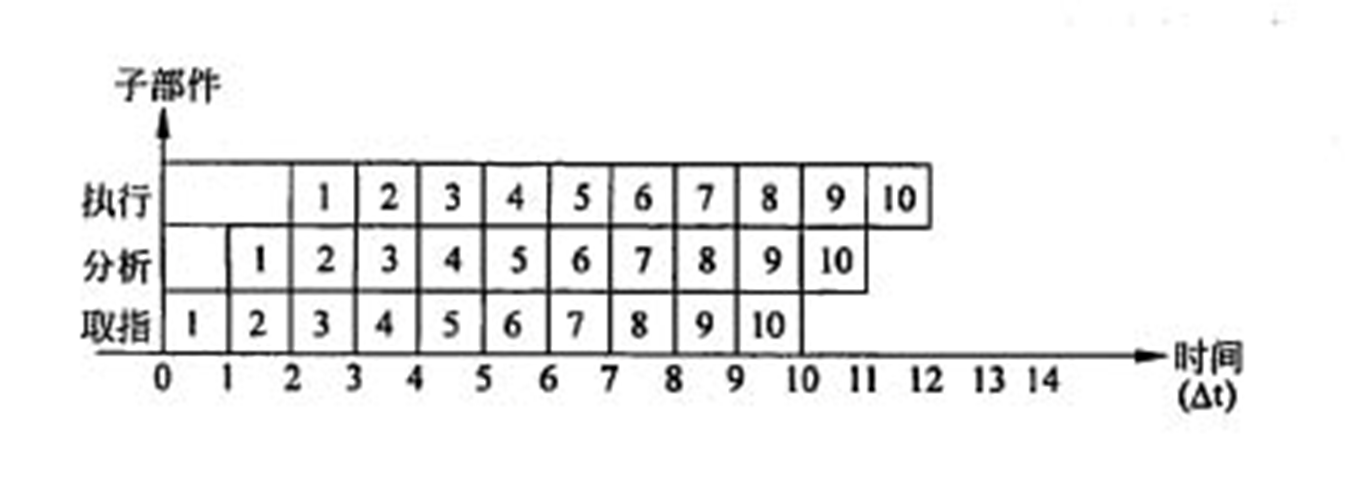
由时空图可知,从第二个时间单位之后,各子部件开始完全并行。此后每个△t都能完成一条指令,所以连续执行10条指令后,则共需时间为2+10=12△t。
第 4 题
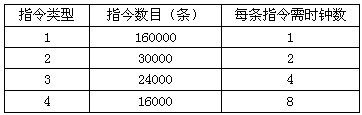
某计算机的时钟频率为400MHz,测试该计算机的程序使用4种类型的指令。每种指令的数量及所需指令时钟数( CPI)如下表所示,则该计算机的指令平均时钟数约为();该计算机的运算速度约为()MIPS。
- (A) 1.85
- (B) 1.93
- (C) 2.36
- (D) 3.75
- (A) 106.7
- (B) 169.5
- (C) 207.3
- (D) 216.2
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[B],[C]]
- 试题解析:
指令平均时钟数约为
(160000×1+30000×2 +24000×4+16000×8)/(160000+30000+24000+16000)
=444000/230000≈1.93
该计算机的运算速度约为
400M/1.93 ≈207.3 MIPS
第 5 题
某计算机指令字长为16位,指令有双操作数、单操作数和无操作数3种格式,每个操作数字段均用6位二进制表示,该指令系统共有m条(m<16)双操作数指令,并存在无操作数指令。若采用扩展操作码技术,那么最多还可设计出()条单操作数指令。
- (A) 26
- (B) (24-m)× 26 - 1
- (C) (24-m)×26
- (D) (24-m)×(26 - 1)
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[B]]
- 试题解析:
若指令字长为16位。每个操作数字段均用6位,则可设置16(216-6-6)条双操作数指令。当双操作数指令数m小于16时,余下的编码可作为扩展码(24- m个)。若为单操作数指令,则可将其中的一个操作数字段扩展为操作码(26个),因此共扩展出(24-m)×26条单操作数指令,考虑到还有无操作数指令,所以单操作数指令中必须至少留出一个编码,用于扩展无操作数指令,因此,最多还可设计出(24-m)×26-1条单操作数指令。
第 6 题
以下不属于网络安全控制技术的是()。
- (A) 防火墙技术
- (B) 访问控制技术
- (C) 入侵检测技术
- (D) 差错控制技术
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[D]]
- 试题解析:
防火墙技术、访问控制技术和入侵检测技术都属于网络安全控制技术,而差错控制技术是一种用来保证数据传输质量的技术,不属于网络安全控制技术。
第 7 题
“冲击波”病毒属于()类型的病毒,它利用Windows操作系统的()漏洞进行快速传播。
- (A) 蠕虫
- (B) 文件
- (C) 引导区
- (D) 邮件
- (A) CGI脚本
- (B) RPC
- (C) DNS
- (D) IMAP
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[A],[B]]
- 试题解析:
“冲击波”病毒是一种蠕虫类型的病毒。在进行网络传播时,利用了Windows操作系统的RPC漏洞。
第 8 题
()确定了标准体制和标准化管理体制,规定了制定标准的对象与原则以及实施标准的要求,明确了违法行为的法律责任和处罚办法。
- (A) 标准化
- (B) 标准
- (C) 标准化法
- (D) 标准与标准化
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[C]]
- 试题解析:本试题考查《标准化法》的主要内容是什么。《标准化法》分为五章二十六条,其主要内容是:确定了标准体制和标准化管理体制(第一章),规定了制定标准的对象与原则以及实施标准的要求(第二章、第三章),明确了违法行为的法律责任和处罚办法(第四章)。标准是对重复性事物和概念所做的统一规定。标准以科学、技术和实践经验的综合成果为基础,以获得最佳秩序和促进最佳社会效益为目的,经有关方面协商一致,由主管或公认机构批准,并以规则、指南或特性的文件形式发布,作为共同遵守的准则和依据。标准化是在经济、技术、科学和管理等社会实践中,以改进产品、过程和服务的适用性,防止贸易壁垒、促进技术合作、促进最大社会效益为目的,对重复性事物和概念通过制定、发布和实施标准,达到统一,以获得最佳秩序和社会效益的过程。
第 9 题
某开发人员不顾企业有关保守商业秘密的要求,将其参与该企业开发设计的应用软件的核心程序设计技巧和算法通过论文向社会发表,那么该开发人员的行为()。
- (A) 属于开发人员权利不涉及企业权利
- (B) 侵犯了企业商业秘密权
- (C) 违反了企业的规章制度但不侵权
- (D) 未侵犯权利人软件著作权
答案与解析
- 试题难度:容易
- 知识点:
- 试题答案:[[B]]
- 试题解析:
本题考查的是知识产权方面的基础知识。
高新技术企业大都是以知识创新开发产品,当知识产品进入市场后,则完全依赖于对其知识产权的保护,如果没有保护或保护不力,将影响企业的生存与发展。
我国《反不正当竞争法》第十条第3项规定:“违反约定或者违反权利人有关保守商业秘密的要求,披露、使用或者允许他人使用其所掌握的商业秘密。第三人明知或者应知前款所列违法行为,获取、使用或者披露他人的商业秘密,视为侵犯商业秘密。”
“本条所称的商业秘密,是指不为公众所知悉、能为权利人带来经济利益、具有实用性并经权利人采取保密措施的技术信息和经营信息。”
试题中“某开发人员违反企业有关保守商业秘密的要求”表明企业对软件产品或成果中的技术秘密,采取了保密措施,构成了商业秘密。一旦发生企业“技术秘密”被泄露的情况,则便于认定为技术秘密,依法追究泄密行为人的法律责任,保护企业的权益。
发表权是指决定作品是否公之于众的权利。所谓公之于众是指作品完成后,以复制、表演、播放、展览、朗诵、发行、摄制或改编、翻译等方式使作品在一定数量不特定人的范围内公开。发表权具体内容包括作品发表的时间、发表的形式和发表的地点等。
所以开发人员的行为违反了企业的规章制度,侵犯了权利人商业秘密权,侵犯了权利人软件著作权。
第 10 题
计算机要对声音信号进行处理时,必须将它转换成为数字声音信号。最基本的声音信号数字化方法是取样一量化法。若量化后的每个声音样本用2个字节表示,则量化分辨率是()。
- (A) 1/2
- (B) 1/1024
- (C) 1/65536
- (D) 1/131072
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[C]]
- 试题解析:
声音信号是一种模拟信号,计算机要对其进行处理,必须将其转换为数字声音信号即用二进制数字的编码形式来表示声音。最基本的声音信号数字化方法是取样一量化法,分成如下3个步骤。
(1)采样:把时间连续的模拟信号转换成时间离散、幅度连续的信号。在某些特定的时刻获取声音信号幅值叫做采样,由这些特定时刻采样得到的信号称为离散时问信号。一般都是每隔相等的一小段时间采样一次,其时间间隔称为取样周期,其倒数称为采样频率。采样定理是选择采样频率的理论依据,为了不产生失真,采样频率不应低于声音信号最高频率的两倍。因此,语音信号的采样频率一般为8kHz,音乐信号的采样频率则应在40kHz以上。采样频率越高,可恢复的声音信号分量越丰富,其声音的保真度越好。
(2)量化:把在幅度上连续取值(模拟量)的每一个样本转换为离散值(数字量),因此量化过程有时也称为A/D转换(模数转换)。量化后的样本是用若干位二进制数(bit)来表示的,位数的多少反映了度量声音波形幅度的精度,称为量化精度,也称为量化分辨率。例如,每个声音样本若用16位(2个字节)表示,则声音样本的取值范围是0~65536精度是1/65536;若只用8位(1个字节)表示,则样本的取值范围是0~255,精度是1/256。量化精度越高,声音的质量越好,需要的存储空间也越多:量化精度越低,声音的质量越差,需要的存储空间也越少。
(3)编码:经过采样和量化处理后的声音信号已经是数字形式了,但为了便于计算机的存储、处理和传输,还必须按照一定的要求进行数据压缩和编码,即:选择某一种或者几种方法对其进行数据压缩,以减少数据量,再按照某种规定的格式将数据组织成为文件。
第 11 题
某幅图像具有640*480个像素点,若每个像素具有8位的颜色深度,则可表示()种不同的颜色,经5:1压缩后,其图像数据需占用()(Byte)的存储空间。
- (A) 8
- (B) 256
- (C) 512
- (D) 1024
- (A) 61440
- (B) 307200
- (C) 384000
- (D) 3072000
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[B],[A]]
- 试题解析:
颜色深度是表示位图图像中单个像素的颜色或灰度所占的位数,8位的颜色深度,表示每个像素有8位颜色位,可表示256种不同的颜色。存储位图图像的数据量与图像大小有关。而位图图像的大小与分辨率、颜色深度有关。本题图像的垂直方向分辨率为640像素,水平方向分辨率为480,颜色深度为8位,则该图像所需存储空间为(640×480× 8 )/8 (Byte) = 307200(Byte)。经5:1压缩后,该图像所需存储空间为307200/5 =61440(Byte)。
第 12 题
常见的软件开发模型有瀑布模型、演化模型、螺旋模型、喷泉模型等。其中()模型适用于需求明确或很少变更的项目,()模型主要用来描述面向对象的软件开发过程。
- (A) 瀑布模型
- (B) 演化模型
- (C) 螺旋模型
- (D) 喷泉快坚
- (A) 瀑布模型
- (B) 演化模型
- (C) 螺旋模型
- (D) 喷泉模型
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[['A'],['D']]
- 试题解析:
本题考查的是常见的软件开发模型的基本概念。
瀑布模型给出了软件生存周期中制定开发计划、需求分析、软件设计、编码、测试和维护等阶段以及各阶段的固定顺序,上一阶段完成后才能进入到下一阶段,整个过程如同瀑布流水。该模型为软件的开发和维护提供了一种有效的管理模式,但在大量的实践中暴露出其缺点,其中最为突出的是缺乏灵活性,特别是无法解决软件需求不明确或不准确的问题。这些问题有可能造成开发出的软件并不是用户真正需要的,并且这一点只有在开发过程完成后才能发现。所以瀑布模型适用于需求明确,且很少发生较大变化的项目。
为了克服瀑布模型的上述缺点,演化模型允许在获取了一组基本需求后,通过快速分析构造出软件的一个初始可运行版本(称作原型),然后根据用户在适用原型的过程中提出的意见对原型进行改进,从而获得原型的新版本。这一过程重复进行,直到得到令用户满意的软件。该模型和螺旋模型、喷泉模型等适用于对软件需求缺乏明确认识的项目。
螺旋模型将瀑布模型和演化模型进行结合,在保持二者优点的同时,增加了风险分析,从而弥补了二者的不足。该模型沿着螺线旋转,并通过笛卡尔坐标的四个象限分别表示四个方面的活动:制定计划、风险分析、实施工程和客户评估。螺旋模型为项目管理人员及时调整管理决策提供了方便,进而可降低开发风险.
喷泉模型是以面向对象的软件开发方法为基础.以用户需求为动力,以对象来驱动的模型。该模型主要用于描述面向对象的开发过程,体现了面向对象开发过程的迭代和无间隙特性。迭代指模型中的活动通常需要重复多次,相关功能在每次迭代中被加入新的系统。无间隙是指在各开发活动(如分析、设计、编码)之间没有明显边界。
第 13 题
软件能力成熟度模型(CMM)是目前国际上最流行、最实用的软件生产过程标准和软件企业成熟度的等级认证标准。该模型将软件能力成熟度自低到高依次划分为初始级、可重复级、已定义级、己管理级、优化级。从()开始,要求企业建立基本的项目管理过程的政策和管理规程,使项目管理工作有章可循。
- (A) 初始级
- (B) 可重复级
- (C) 已定义级
- (D) 已管理级
答案与解析
- 试题难度:较难
- 知识点:
- 试题答案:[[B]]
- 试题解析:
CMM是美国卡内基一梅隆大学软件工程研究所与企业、政府合作的基础上开发的模型,主要用于评价软件企业的质量保证能力。CMM为软件企业的过程能力提供了一个阶梯式的进化框架,将软件过程改进的进化步骤分为5个成熟度等级,每个等级定义了一组过程能力目标,并描述了要达到这些目标应采取的实践活动,为不断改进过程奠定了循序渐近的基础.这个等级的层次关系如下图所示。图中的初始级是起点,该等级的企业一般缺少有效的管理,项目进行过程中常放弃最初的规划,开发项目成效不稳定。而从可重复级开始,每个级别都设定了一组目标,且低级别目标的实现是实现高级别目标的基础。
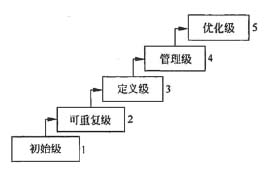
可重复级要求企业建了基本的管理制度和规程,管理工作有章可循,初步实现开发过程标准化。定义级要求整个软件生命周期的管理和技术工作均己实现标准化、文档化,并建立完善的培训制度和专家评审制度,项目质量、进度和费用均可控制。在管理级,企业的软件过程和产品己建立定量的质量目标,并通过一致的度量标准来指导软件过程,保证项目对生产率和质量进行度量,可预测过程和产品质量趋势。在优化级,企业可集中精力改进软件过程,并拥有防止出现缺陷、识别薄弱环节及进行改进的手段。
该模型经过二十多年的验证,目前已经成为国际上最流行、最实用的软件生产过程标准和软件企业成熟度的等级认证标准。
第 14 题
软件项目开发成本的估算依据,通常是开发成本估算模型。常用的模型主要有:
①IBM模型 ②PUtnam模型 ③基本COCOMO模型
④中级COCOMO模型 ⑤高级COCOMO模型
其中()均是静态单变量模型。
- (A) ①②
- (B) ②④⑤
- (C) ①③
- (D) ③④⑤
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[C]]
- 试题解析:
各种开发成本估算模型通常采用经验公式,提供一个或多个数学算法,将成本作为若干个变量的函数计算求得。常用的估算模型中,IBM模型是静态单变量模型,利用已估算的特性(如源代码函数)来估算各种资源的需求量。Putnam模型是一种动态多变量模型,它假定软件项目工作量的分布和Rayleigh曲线类似,并把项目的资源需求当作时间的函数。该模型为描述开发工作量和计划进度之间的关系定义了两个方程:①软件方程,表明开发工作量和项目规模的三次幂成正比,与开发时间的四次方称反比;②人力增加方程,表明工作量和开发时间三次幂成正比。Putnam模型一般应用于超过70000代码行的项目。
COCOMO模型是一种精确且易于适用的成本估算模型,它是由基本COCOMO模型、中级COCOMO模型和高级COCOMO模型组成的集合。基本COCOMO模型是静态单变量模型,用一个已估算的源代码行数为自变量的经验函数来计算软件开发工作量和开发成本。中级COCOMO模型在基本模型中已计算的软件开发工作量的基础上,在用涉及产品、硬件、人员、项目和项目的15个成本驱动因素来调整工作量的估算。高级COCOMO模型不但包括了中级COCOMO模型的所有特性,而且为上述15个因素在软件生存周期的不同阶段赋予了不同的权重。
COCOMO模型由Boehm于1981年首次发表,Boehm后来又和同事定义了更复杂的COCOMO II模型,该模型反映了软件工程技术的近期变化。COCOMO模型非常适合专用的、按技术说明制作的软件项目,而COCOMO II模型更适用于广泛汇集各种技术的软件项目,为商用软件、面向对象软件、通过螺旋型或进化型等开发模型制作的软件。
第 15 题
“通过指明一系列可执行的运算及运算的次序来描述计算过程”是()语言的特点。
- (A) 逻辑式
- (B) 函数式
- (C) 交互式
- (D) 命令式(或过程式)
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[D]]
- 试题解析:
本题考查程序语言的基本类型和特点。
逻辑式语言是一类以形式逻辑为基础的语言。函数式语言以补演算为基础。命令式语言是基于动作的语言,在这种语言中,计算被看成是动作的序列。因此,通过指明一系列可执行的运算及运算的次序来描述计算过程是命令式语言的特点。
第 16 题
“X=(A+B)× (C - D/E)”的后缀式表示为()。
- (A) XAB+CDE/-×=
- (B) XAB+C-DE/×=
- (C) XAB+CDE-/×=
- (D) XAB+CD-E/×=
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[A]]
- 试题解析:
本题考查表达式的表示方式。
后缀表示也称为表达式的逆波兰表示。在这种表示方法中,将运算符号写在运算对象的后面,并指明其前面的操作数或中间结果所要执行的运算。对后缀表达式从左到右求值,则每当扫描到一个运算符号时,其操作数是最近刚得到的。表达式“X=(A+B)×(C一D/E)”的后缀式为“XAB+CDE/-x=”。
第 17 题
在一个单CPU的计算机系统中,采用可剥夺式(也称抢占式)优先级的进程调度方案,且所有任务可以并行使用I/O设备。下表列出了三个任务T1、T2、T3的优先级、独立运行时占用CPU和I/O设备的时间。如果操作系统的开销忽略不计,这三个任务从同时启动到全部结束的总时间为()ms.CPU的空闲时间共有()ms。

- (A) 28
- (B) 58
- (C) 61
- (D) 64
- (A) 3
- (B) 5
- (C) 8
- (D) 13
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[B],[D]]
- 试题解析:
本题考查的是操作系统进程调度方面的知识。
根据题意可知,三个任务的优先级T1>T2>T3,进程调度过程如下图所示,分析如下。
t0时刻:进程调度程序选任务T1投入运行,运行l0ms,任务T1占用I/O;
t1时刻:此时由于CPU空闲,进程调度程序选任务T2投入运行,运行l 0ms后任务T2占用I/O。此时,t1与t2时刻任务T1在I/O,任务T2在运行。
t2时刻:此时由于CPU空闲,进程调度程序选任务T3投入运行,运行3ms后任务T1结束占用I/O。此时,t2与t3时刻任务T1和任务T2占用v0,任务T3在运行。
t3时刻:由于系统采用可剥夺式优先级的进程调度方案,所以,强行地将任务T3占用的CPU剥夺,分配给任务T1。在运行5ms后,到t4时刻任务T1运行完毕。此时,t3与t4时刻任务T1在运行,任务T2等待,任务T3占用I/O。
t4时刻:将CPU分配给T3运行5ms后,到t5时刻任务T2结束占用I/O,强行地将任务T3占用的CPU剥夺,任务T2开始运行。此时,t4与t5时刻任务T1结束,任务T2占用I/O,任务T3在运行。
t5时刻:运行5ms后,到t6时刻任务T2运行完毕。
t6时刻:系统将CPU分配给任务T3,运行2ms后,到t7时刻任务T3占用I/O。
t7时刻到t6时刻:共计13ms,没有待运行的任务。
t8时刻:任务T3结束占用I/O,运行5ms后,到t9时刻任务T3运行结束。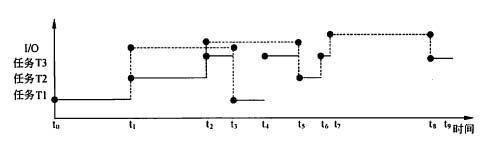
从以上分析可见,这三个任务从同时启动到全部结束的总时间为58ms,CPU的空闲时间共有13ms。
第 18 题
从下表关于操作系统存储管理方案1、方案2和方案3的相关描述可以看出,它们分别对应()存储管理方案。

- (A) 固定分区、请求分页和覆盖
- (B) 覆盖、请求分页和固定分区
- (C) 固定分区、覆盖和请求分页
- (D) 请求分页、覆盖和固定分区
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[A]]
- 试题解析:
本题考查的是操作系统存储管理方面的基础知识,正确答案为A,分析如下:
题中方案1对应的是固定分区管理方案。固定分区是一种静态分区方式,在系统生成时已将主存区划分为若干个分区,每个分区的大小可不等。操作系统通过主存分配情况表管理主存区。这种方法的突出问题是已分配区中存在未用空间,原因是程序或作业的大小不可能都刚好等于分区的大小,造成了空间的浪费。通常将已分配分区内的未用的空间叫做零头或内碎片。
题中方案2对应的是请求分页存储管理。将一个进程的地址空间划分成若干个大小相等的区域。称为页。相应地,将主存空间划分成与页相同大小的若于个物理块,称为块或页框。在为进程分配主存时,只装入若干页的用户程序和数据(而非全部程序),就可以启动运行,而且若干页可分别装入多个不相邻接的物理块中。当访问的页面不在主存区时,产生缺页中断,系统通过调页功能和页面置换功能.陆续把将要使用的页面调入主存区,同时把暂不运行的页面置换到外存上。因此,该方案当一个作业的程序地址空间大于主存区可以使用的空间时也可以执行。
题中方案3对应的是覆盖技术。覆盖技术是指让作业中不同时运行的程序模块共同使用同一主存区域。这样,不必将程序完全装入主存区即可运行。当运行中调用另一个模块时,再从辅存中调入这个模块而将原来已经运行完成的程序模块覆盖,即装入到同一个存储区域内。对此,要求用户明确地描述作业中各个程序摸块间的调用关系,这将加重用户负担。
第 19 题
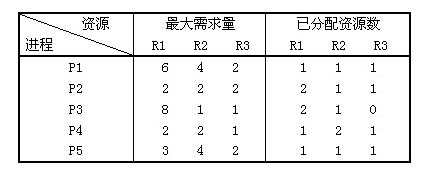
假设系统中有三类互斥资源R1、R2和R3,可用资源数分别为8、7和4。在T0时刻系统中有P1、P2、P3、P4和P5五个进程,这些进程对资源的最大需求量和己分配资源数如下表所示。在T0时刻系统剩余的可用资源数分别为()。如果进程按()序列执行,那么系统状态是安全的。
- (A) 0、1和0
- (B) 0、1和1
- (C) 1、1和0
- (D) 1、1和1
- (A) P1→P2→P4→P5→P3
- (B) P2→P1→P4→P5→P3
- (C) P4→P2→P1→P5→P3
- (D) P4→P2→P5→P1→P3
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[C],[D]]
- 试题解析:
试题(24)的正确答案是C。因为,初始时系统的可用资源数分别为8、7和4。在T0时刻己分配资源数分别为7、 6和4,因此系统剩余的可用资源数分别为1、1和0.
试题((25)的正确答案是D。安全状态是指系统能按某种进程顺序(P1,P2,…,Pn),来为每个进程Pi分配其所需的资源,直到满足每个进程对资源的最大需求,使每个进程都可以顺利完成。如果无法找到这样的一个安全序列,则称系统处于不安全状态。
本题,序列已经给出,只需将四个选项按其顺序执行一遍,便可以判断出现死锁的三个序列。
由于R3资源为0,系统不能在分配R3资源了,所以不能一开始就运行需要分配R3资源的进程。所以,A和B显然是不安全的。
现在求序列P4→P2→P1→P5→P3是否安全。进程P4可以加上能完成标志“True”,如下表所示。因为系统的可用资源数为(1,1,0),而进程P4只需要一台R1资源;进程P2可以加上能完成标志“True”,因为进程P4运行完毕将释放所有资源,此时系统的可用资源数应为(2,3,1),而进程P2只需要(0,1,1),进程P2运行完毕将释放所有资源,此时系统的可用资源数应为(4,4,2);进程P1不能加上能完成标志“True ”,因为,进程P1需要R1资源为5,系统能提供的R1资源为4,所以序列无法进行下去,因此,P4→P2→P1→P5→P3为不安全序列。
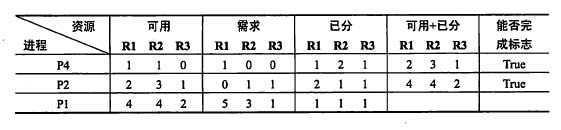
序列P4→P2→P5→P1→P3是安全的,因为所有的进程都能加上完成标志“True”,
如下表所示。
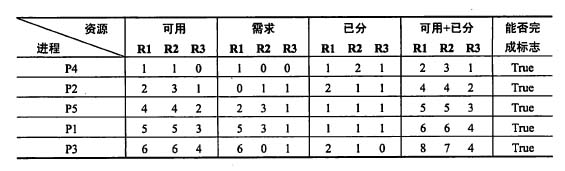
第 20 题
统一过程(UP)的基本特征是“用例驱动、以架构为中心的和受控的迭代式增量开发”。UP将一个周期的开发过程划分为4个阶段,其中()的提交结果包含了系统架构。
- (A) 先启阶段
- (B) 精化阶段
- (C) 构建阶段
- (D) 提交阶段
答案与解析
- 试题难度:较难
- 知识点:
- 试题答案:[[B]]
- 试题解析:
统一过程(UP)的基本特征是“用例驱动、以架构为中心的和受控的迭代式增量开发”。一个UP可分为若干个周期,每个周期的开发过程被分为4个阶段,每个阶段可进行若干次迭代。
UP将一个周期的开发过程划分为如下的4个阶段。
(1)先启阶段(Inception ):该阶段的主要意图是建立项目的范围和版本,确定业务实现的可能性和项目目标的稳定性。提交结果包括原始的项目需求和业务用例。
(2)精化阶段〔Elaboration):该阶段的主要意图是对问题域进行分析,建立系统的需求和架构,确定技术实现的可行性和系统架构的稳定性.提交结果包括系统架构及其相关文档、领域模型、修改后的业务用例和整个项目的开发计划.
(3)构建阶段(Construction ):主要意图是增量式地开发一个可以交付用户的软件产品。
(4)提交阶段(Transition ):主要意图是将软件产品提交用户。
第 21 题
某软件在应用初期运行在Windows NT环境中。现因某种原因,该软件需要在UNIX环境中运行,而且必须完成相同的功能。为适应这个要求,软件本身需要进行修改,而所需修改的工作量取决于该软件的()。
- (A) 可扩充性
- (B) 可靠性
- (C) 复用性
- (D) 可移植性
答案与解析
- 试题难度:容易
- 知识点:
- 试题答案:[[D]]
- 试题解析:
软件的可扩充性指软件的体系结构、数据设计和过程设计的可扩充程度,可扩充性影响着软件的灵活性和可移植性。软件可靠性指软件按照设计要求,在规定时间和条件下不出故障,可持续运行的程度,可靠性取决于软件的一致性、安全性、容错性和准确性等.软件复用性指软件或软件的部件能被再次用于其他应用中的程度,软件复用性取决于其模块独立性、通用性和数据共享性等。软件可移植性指将软件系统从一个计算机系统或环境移植到另一种计算机系统或环境中运行时所需工作量的大小,可移植性取决于系统中硬件设备的特征、软件系统的特点和开发环境、系统分析与设计中关于通用性、软件独立性和可扩一充性等方面的考虑。
第 22 题
按照ISO/IEC 9126软件质量度量模型定义,一个软件的可靠性的子特性包括()。
- (A) 容错性和安全性
- (B) 容错性和适应性
- (C) 容错性和易恢复性
- (D) 易恢复性和安全性
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[C]]
- 试题解析:
目前已有多种关于软件质量的度量模型,它们都把软件质量特性定义为分层模型,其中最基本的称作基本质量特性(简称质量特性),每个质量特性包括多项质量子特性。在最初的ISO模型中,包括8个基本特性。而1991年发布的ISO/IEC 9126模型中,基本特性减少为6个:功能性、可靠性、易使用性、效率、可维护性和可移植性。其中可靠性包括三个子特性,即成熟性、容错性和易恢复性。而安全性是功能性的子特性,适应性是可移植性的子特性。
第 23 题
()详细描述软件的功能、性能和用户界面,以使用户了解如何使用软件。
- (A) 概要设计说明书
- (B) 详细设计说明书
- (C) 用户手册
- (D) 用户需求说明书
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[C]]
- 试题解析:
本题考查软件文档知识。在软件文档中,概要设计说明书主要说明系统的功能分配、模块划分、程序的总体结构、I/O及接口设计、运行设计、数据结构设计和错误处理设计等内容;详细设计说明书着重描述每个模块是如何实现的;用户手册帮助用户了解软件的使用,需要描述软件的功能、性能和用户界面;用户需求说明书是开发人员和用户经过充分沟通后对软件需求的共同理解,主要说明软件的功能、性能和运行环境等内容。
第 24 题
各类软件维护活动中,()维护占整个维护工作的比重最大。
- (A) 完善性
- (B) 改正性
- (C) 适应性
- (D) 预防性
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[A]]
- 试题解析:
维护是软件生命周期中的重要阶段。按照引发维护的原因,可将软件维护活动分为
(1)改正性维护,是指改正系统中己发生、但测试中未发现的错误。这种维护工作量约占整个维护工作量的20%左右。
(2)适应性维护,是指为使软件适应信息技术变化、软硬件环境和管理需求等变化而修改软件,约占整个维护工作量的25%左右。
(3)完善性维护,是指为扩充软件功能、改进加工效率、改善系统性能而修改软件,这种维护对系统质量的影响较大.约占整个维护工作量的50%左右。
(4)预防性维护,是指为提高软件的可维护性和可靠性,并适应未来的软硬件环境变化而对软件或软件中的一部分重新设计,这种维护约占整个维护工作量的5%左右。
第 25 题
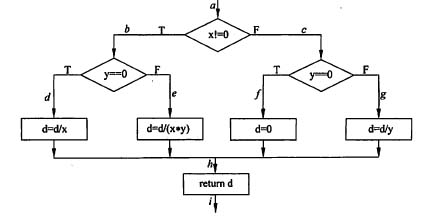
给定C语言程序:
int foo( int x, int y, int d)
{
if( x!=0)
{
if(y==0)d=d/x;
else d=d/(x*y);
}
else
{
if(y==0)d=0;
else d=d/y;
}
return d;
}
当用路径覆盖法进行测试时,至少需要设计()个测试用例。
- (A) 3
- (B) 4
- (C) 5
- (D) 8
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[B]]
- 试题解析:
路径覆盖法是白盒测试的作用方法,要求设计足够多的测试用例,覆盖程序中所有可能的路径。给定程序的流程图如下图所示。
从图中可以看出,程序中共存在四条路径,分别记为abdh, abeh、 acfh、 acgh。当用路径覆盖法设计侧试案例时,必须为每条路径至少设计一个用例。下面给出一组可覆盖全部路径的测试用例。
测试用例1: [(2,0,8),4],覆盖路径abdh
测试用例2 :[(2,2,8),2],覆盖路径abeh
测试用例3: [(0,0,8),0],覆盖路径acfh
测试用例4: [(4,2,8), 4],覆盖路径acgh
用例采用形式[输入的(x,y,d),返回的d]来描述。
第 26 题
软件的测试通常分单元测试、组装测试、确认测试、系统测试四个阶段进行。()属于确认测试阶段的活动。
- (A) 设计评审
- (B) 代码审查
- (C) 结构测试
- (D) 可靠性测试
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[D]]
- 试题解析:
测试是软件开发过程中的重要活动,为提高系统质量和可靠性提供保障。通常测试与软件开发阶段密切相对应。单元测试通常在模块的开发期间实施,主要测试程序中的一个模块或一个子程序。集成测试通常需要将所有程序模块按照设计要求组装成为系统,这种测试的目的是在保证各模块仍能够正常运行的同时,组装后的系统也能够达到预期功能。确认测试的任务是进一步检查软件的功能和性能是否与用户要求一致。系统测试把己经确认的软件在实际运行环境中,与其他系统成分组合在一起进行测试。
在本题给出的备选项中,设计评审是指对软件需求分析阶段和概要设计阶段产生的软件设计说明书进行质量等方面的评审,此时,软件还没有形成实体;代码审查以人工的模拟技术和一些类似与动态分析的方法对程序进行分析和测试,通常在单元测试阶段进行;结构测试则是在了解程序结构的前提下在单元/模块测试中进行;可靠性测试则主要检查软件的平均失效间隔时间等指标是否符合系统需求。
第 27 题
面向对象分析的第一步是()
- (A) 定义服务
- (B) 确定附加的系统约束
- (C) 确定问题域
- (D) 定义类和对象
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[C]]
- 试题解析:
定义服务、取定附加的系统约束以及定义类和对象的前提是要确定问题域。
第 28 题
面向对象程序设计语言为()提供支持。
- (A) 面向对象用例设计阶段
- (B) 面向对象分析阶段
- (C) 面向对象需求分析阶段
- (D) 面向对象实现阶段
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[D]]
- 试题解析:
选项A、B、C三个阶段都可以采用建模语言来进行描述,而面向对象程序设计语言主要为面向对象实现阶段提供支持。
第 29 题
下面关于面向对象的描述正确的()。
- (A) 针对接口编程,而不是针对实现编程
- (B) 针对实现编程,而不是针对接口编程
- (C) 接口与实现不可分割
- (D) 优先使用继承而非组合
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[A]]
- 试题解析:
针对接口编程能够将接口调用代码和接口实现代码相分离,提倡针对接口进行编程。
第 30 题
下面关于UML文档的叙述中正确的是()。
- (A) UML文档指导开发人员如何进行面向对象分析
- (B) UML文档描述了面向对象分析与设计的结果
- (C) UML文档给出了软件的开发过程和设计流程
- (D) UML文档指导开发人员如何进行面向对象设计
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[B]]
- 试题解析:
UML文档仅仅是设计与开发人员采用UML语言进行系统分析与设计的结果,并没有给出如何进行开发和采用何种开发流程,同样也不指导如何进行面向对象设计。
第 31 题
UML的设计视图包含了类、接口和协作,其中,设计视图的静态方面由()和()表现;动态方面由交互图、()表现。
- (A) 类图
- (B) 状态图
- (C) 活动图
- (D) 用例图
- (A) 状态图
- (B) 顺序图
- (C) 对象图
- (D) 活动图
- (A) 状态图和类图
- (B) 类图和活动图
- (C) 对象图和状态图
- (D) 状态图和活动图
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[A],[C],[D]]
- 试题解析:
类图和对象图反映了设计视图的静态特征,状态图和活动图反映了系统的动态特征
第 32 题
UML中的构件是遵从一组接口并提供一组接口的实现,下列说法错误的是()。
- (A) 构件应是可替换的
- (B) 构件表示的是逻辑模块而不是物理模块
- (C) 构件应是组成系统的一部分
- (D) 构件与类处于不同的抽象层次
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[B]]
- 试题解析:
构件应该是物理模块而不是逻辑模块。
第 33 题
设计模式具有()的优点。
- (A) 适应需求变化
- (B) 程序易于理解
- (C) 减少开发过程中的代码开发工作量
- (D) 简化软件系统的设计
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[A]]
- 试题解析:
设计模式能够在需求变化的情况下,尽可能不更改原有的设计和实现。
第 34 题
下面的()模式将对象组合成树形结构以表示“部分一整体”的层次结构,并使得用户对单个对象和组合对象的使用具有一致性。
- (A) 组合(Composite)
- (B) 桥接(Bridge)
- (C) 修饰(Decorator)
- (D) 外观(Facade)
答案与解析
- 试题难度:容易
- 知识点:
- 试题答案:[[A]]
- 试题解析:
组合模式将被组合的对象和组合对象抽象为同一种对象,使得用户对单个对象和组合对象的使用变得统一。
第 35 题
下图描述了一种设计模式,该设计模式不可以()。

- (A) 动态决定由一组对象中某个对象处理该请求
- (B) 动态指定处理一个请求的对象集合,并高效率地处理一个请求
- (C) 使多个对象都有机会处理请求,避免请求的发送者和接收者间的祸合关系
- (D) 将对象连成一条链,并沿着该链传递请求
答案与解析
- 试题难度:较难
- 知识点:
- 试题答案:[['B']]
- 试题解析:
本题考查设计模式的基本知识。
在题目中给出的设计模式中,Client可调用Handler接口,Handler接口可以有后继,因此,当一个Client向HandleRequest发出一个HandleRequest请求时,可以有多个具体的CancreteHandler来响应此请求。由于处理该请求的CancreteHandler形成一个具体的链,所以处理的时候效率不高。
第 36 题
在面向对象程序设计中,常常将接口的定义与接口的实现相分离,可定义不同的类实现相同的接口。在程序运行过程中,对该接口的调用可根据实际的对象类型调用其相应的实现。 为达到上述目的,面向对象语言须提供()机制。
- (A) 继承和过载(overloading)
- (B) 抽象类
- (C) 继承和重置(overriding)
- (D) 对象自身引用
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[['C']]
- 试题解析:
根据题目的描述,根据一个接口调用不同的实现,需要用多态机制支持,多态机制一般和继承机制结合使用,由于子类可以实现接口,通常将接口定义为虚拟函数,这种机制实际上是重置机制的应用。
第 37 题
下图是一有限自动机的状态转换图,该自动机所识别语言的特点是(),等价的正规式为()。
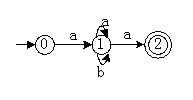
- (A) 由符号a.b构成且包含偶数个a的串
- (B) 由符号a.b构成且开头和结尾符号都为a的串
- (C) 由符号a.b构成的任意串
- (D) 由符号a.b构成且b的前后必须为a的串
- (A) (a∣b)(aa)
- (B) a(a∣b)*a
- (C) (a∣b)*
- (D) a(ba)*a
答案与解析
- 试题难度:容易
- 知识点:
- 试题答案:[[B],[B]]
- 试题解析:
本题考查有限自动机的基本运算。
在有限自动机的状态转换图中,每一个结点代表一个状态,其中双圈是终态结点。
对于字符串ω,若存在一条从初态结点到某一终止状态结点的路径,且这条路径上所有弧的标记符连接成的字符串等于ω,则称ω可由DFA M识别(接收或读出)。若一个DFA M的初态结点同时又是终态结点,则空字ε可由该DFA识别(或接收)。DFA M所能识别的语言L(M)={ω|ω)是从M的初态到终态的路径上的弧上标记所形成的串}。
分析题中给出的自动机:从初态0出发,识别一个符号a后进入状态1,在状态1可识别出任意个a或(和)任意个b,再识别出一个a而到达终态2。显然,该自动机识别的语言特点是“由a开头由a结尾,期间的a、b任意排列”。用正规式表示为“a(a|b)*a”。
第 38 题
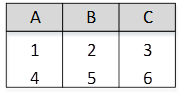
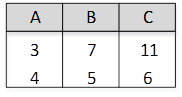
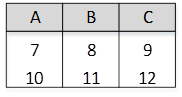
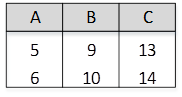
关系R、S如下图所示,元组演算表达式

- (A)
- (B)
- (C)
- (D)
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[C]]
- 试题解析:
本题考查关系代数运算和元组演算的基本知识。
题干中的元组演算表达式所构成的关系为:从关系R中选择的元组t应满足该元组在C列上的分量大于关系S中的任意一个元组u在A列上的分量.
关系R中的第一个元组(1, 2, 3)中的第三个分量r[3]=3,由于3不满足大于S关系的第一个元组u[ 1 ]=3以及S关系的第二个元组u[ 1 ]=4,故关系R中的第一个元组(1,2,3)不在新构成的关系中;
关系R中的第二个元组((4,5,6)中的第三个分量r[3]=6,由于6不满足大于S关系的第四个元组u[1]=6,故关系R中的第二个元组(4,5,6)不在新构成的关系中;
关系R中的第三个元组(7,8,9)中的第三个分量r[3]=9由于9大于S关系的任何一个元组,故关系R中的第三个元组(7,8,9)在新构成的关系中;
关系R中的第四个元组(10, 11, 12)中的第三个分量t[3]=12,由于12大于S关系的任何一个元组,故关系R中的第四个元组(10,11,12)在新构成的关系中。
根据上述分析可见,新构成的关系中有元组(7,8,9)和(10,11,12),因此本题正确答案为C。
第 39 题
某企业职工和部门的关系模式如下所示,其中部门负责人也是一个职工。职工和部门关系的外键分别是()。
职工(职工号,姓名,年龄,月工资,部门号,电话,办公室)
部门(部门号,部门名,负责人代码,任职时间)
查询每个部门中月工资最高的“职工号”的SQL查询语句如下:
Select 职工号from职工as E
where月工资=(Select Max(月工资) from职工as M())。
- (A) 职工号和部门号
- (B) 部门号和负责人代码
- (C) 职工号和负责人代码
- (D) 部门号和职工号
- (A) where M.职工号=E.职工号
- (B) where M.职工号=E.负责人代码
- (C) where M.部门号=部门号
- (D) where M.部门号=E.部门号
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[['B'],['D']]
- 试题解析:
本题考查的是关系数据库中关系模式和SQL查询方面的基础知识。
试题(1)的正确答案是B。因为,作为主键其值能唯一地标识元组的一个或多个属性,主键通常也称为主码。所谓外键是指如果关系模式R中的属性或属性组不是该关系的码,但它是其他关系的码,那么该属性集对关系模式R而言是外键,通常也称外码。根据题意分析,职工关系中的主键是职工号,部门关系中的主键是部门号。显然,职工关系中的外键是部门号。但是,部门关系中的外键是负责人代码,为什么?因为题中说明部门负责人也是一个职工,这样负责人代码的取值域为职工号,所以根据外键定义部门关系中的外键是负责人代码。
试题(2)的正确答案是D。正确的查询每个部门中月工资最高的“职工号”的SQL查询语句如下:
Select 职工号 from 职工as E
where月工资=(SelectMax(月工资)from职工asM whereto.部门号=E,部门号);
此题子查询“Select Max(月工资)from职工as M where M.部门号=E.部门号”意为找出M.部门号最高月工资,主查询“Select职工号from职工as Ewhere月工资=”意为该职工的月工资等于最高工资。
第 40 题
操作序列T1、T2、T3对数据A、B、C并发操作如下所示,T1与T2间并发操作(),T2与T3 间并发操作()。

- (A) 不存在问题
- (B) 将丢失修改
- (C) 不能重复读
- (D) 将读“脏”数据
- (A) 不存在问题
- (B) 将丢失修改
- (C) 不能重复读
- (D) 将读“脏”数据
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[C],[B]]
- 试题解析:
本题考查的是数据库并发操作方面的基础知识。
在事务并行处理的过程中,因为多个事务对相同数据的访问,千扰了其他事务的处理,产生了数据的不一致性,是事务隔离性的破坏导致了一致性的破坏。并发操作带来的数据不一致性有三类:丢失修改、不可重复读和读“脏”数据。
事务T1读取A、 B的值后进行运算,事务T2在t6时刻对B的值做了修改以后,事务T1在t8、t9时刻又重新读取A、 B的值再运算,同一事务内对同一组数据的相同运算结果不同,显然与事实不相符,这种情况的产生是由于事务T2干扰了事务T1的独立性,导致不可重复读。
事务T2、T3对数据B分别做减100和加50操作,都是写入数据库。其中事务T2在时刻t6把B修改后的值100写入数据库,但事务T3在时刻t11再把它对B加50后的值250写入数据库。两个事务都是对H的值进行修改操作并且都执行成功,但B中的值却为250,造成数据的不一致。原因在于T2事务对数据库的修改被T3事务覆盖而丢失了,破坏了事务的隔离性,所以丢失修改。
第 41 题
结点数目为n的二叉查找树(二叉排序树)的最小高度为()、最大高度为()。
- (A)
- (B)
- (C)
- (D)
- (A)
- (B)
- (C)
- (D)



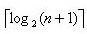
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[D],[A]]
- 试题解析:
本题考查二叉排序树的基本构造特点。
若二叉树中有n个结点,则结点分布均匀、且高度最小的树的特点是除了最后一层,其余各层的结点数目都达到最大值(第i层上有2i-1个结点),此时树的高度为[log2(n+1)]。若每层只有一个结点,则树的高度为n。
具有三个结点的二叉树的所有形态如下所示,每层只有一个结点时称为单枝树。
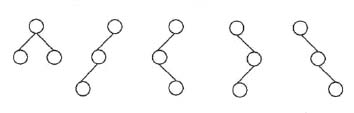
二叉排序树是根据输入序列构造的,当序列呈现有序的特点时,就构造出一棵单枝树。
第 42 题
某双向链表中的结点如下图所示,删除t所指结点的操作为()。

- (A) t->prior->next=t->next; t->next->prior=t->prior;
- (B) t->prior->prior=t->prior; t->next->next=t->next;
- (C) t->prior->next=t->prior; t->next->prior=t->next;
- (D) t->prior->prior=t->next; t->next->prior=t->prior;
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[A]]
- 试题解析:
本题考查链表的基本运算。设q指向t的前驱结点,p指向t的后继结点,如下所示。
可知,q=t->prior, p=t->nexto
删除t所指结点的操作为:
①q一next=p;
②p一prior=q。
由于题目中没有给出指针p和q,所以将①、②中的p和q分别代换为“t -> next”和“t-prior”,则得到
t->prior->next=t->next
t->next->prior=t->prior

第 43 题
对于二维数组a[0..4,1..5] ,设每个元素占1个存储单元,且以列为主序存储,则元素a[2,2]相对于数组空间起始地址的偏移量是() 。
- (A) 5
- (B) 7
- (C) 10
- (D) 15
答案与解析
- 试题难度:一般
- 知识点:
- 试题答案:[[B]]
- 试题解析:
本题考查数组元素的存储。
若二维数组A[L1...U1,L2..U2]以行为主序存储,每个元素占用d个存储单元,则元
素A[I,J]的存储位置相对于数组空间首地址的偏移量为
((I一L1)×(U2一L2+ 1)+J一L2)× d
若二维数组A[L1..U1,L2..U2]以列为主序存储,每个元素占用d个存储单元,则元
素A[I,J]的存储位置相对于数组空间首地址的偏移量为
((J-L2)×(U1一L1 +1)+ I一L1)× d
本题中d=1,L1=0.U1=4, L2=1.U2=5,代入后计算可得偏移量为7。
第 44 题
对于n个元素的关键字序列{k1,k2,...,kn},当且仅当满足关系ki≤k2i且ki≤k2i+1 (2i≤n,2i+1≤n)称其为小根堆,反之则为大根堆。以下序列中,()不符合堆的定义。
- (A) (4,10,15,72,39,23,18)
- (B) (58,27,36,12,8,23,9)
- (C) (4,10,18,72,39,23,15)
- (D) (58,36,27,12,8,23,9)
答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>排序
- 试题答案:[[C]]
- 试题解析:
本题考查堆的概念。
将序列中的元素放入一棵完全二叉树。如下所示,以便于观察结点k1,k2i和k1,k2i+1(2i ≤n, 2i + 1≤n)之间的关系。
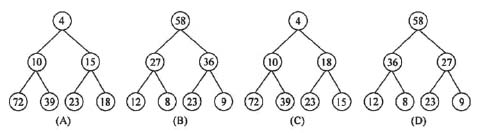
按照小根堆的定义检查选项A和C,按照大根堆的定义检查选项B和D,显然,选项C不符合小根堆的定义.
第 45 题
求单源点最短路径的迪杰斯特拉(Dijkstra)算法是按()的顺序求源点到各顶点的最短路径的。
- (A) 路径长度递减
- (B) 路径长度递增
- (C) 顶点编号递减
- (D) 顶点编号递增
答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>其它
- 试题答案:[[B]]
- 试题解析:
求单源点最短路径的迪杰斯特拉(Dijkstra)算法是按路径长度递增的顺序求源点到各顶点的最短路径的。
第 46 题
()算法策略与递归技术的联系最弱。
- (A) 动态规划
- (B) 贪心
- (C) 回溯
- (D) 分治
答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>贪心法
- 试题答案:[[B]]
- 试题解析:
对于具有最优子结构和重叠子问题的问题,可以用动态规划求解问题,求解过程中通常需要建立最优子结构的递归关系。分治算法的基本思想是将原问题分解为若干个规模更小但结构与原问题相似的子问题。递归地解这些子问题,然后将这些子问题的解组合为原问题的解。回溯算法也称为试探算法,该算法首先放弃关于问题规模大小的限制,并将问题的候选解按某种次序逐一枚举和检验。当发现当前候选解不可能是解时,就选择下一个候选解,若当前候选解除了还不满足问题规模要求外,满足所有其他要求时,继续扩大当前候选解的规模,并继续试探。用回溯算法找解的算法常常被编写成递归函数。贪心算法是一种不追求最优解,而是希望得到较为满意解的方法。贪心算法一般可以快速得到满意的解,因为它省去了为找最优解要穷尽所有可能而必须耗费大量的时间。贪心法不要回溯。因此贪心算法策略与递归技术的联系最弱。
第 47 题
对于具有n个元素的一个数据序列,若只需得到其中第k个元素之前的部分排序,最好采用(),使用分治(Divide and Conquer)策略的是()算法。
- (A) 希尔排序
- (B) 直接插入排序
- (C) 快速排序
- (D) 堆排序
- (A) 冒泡排序
- (B) 插入排序
- (C) 快速排序
- (D) 堆排序
答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>排序
- 试题答案:[[D],[C]]
- 试题解析:
本题考查排序算法及特点。
对于希尔排序、直接插入排序,只有在排序过程后才能确保全部序列以及前k个元素的最终排列,快速排序采用分治算法,常用递归算法实现,该算法根据枢轴元素进行划分,第一趟划分结束后得到了两个子序列,一个序列中的元素均不大于另一个子序列中的元素,枢轴元素介于这两个子序列之间。若仅需得到最终序列的前k个元素,每次得到枢轴元素位置后再考虑下一步的排序过程,在算法的流程控制上比较复杂。对于只需得到最终序列的前k个元素,堆排序比较简单。
第 48 题
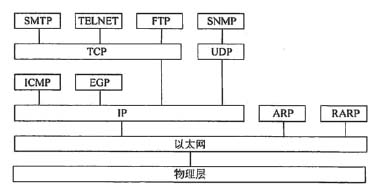
ARP协议的作用是(),ARP报文封装在()中传送。
- (A) 由IP地址查找对应的MAC地址
- (B) 由MAC地址查找对应的IP地址
- (C) 由IP地址查找对应的端口号
- (D) 由MAC地址查找对应的端口号
- (A) 以太帧
- (B) IP数据报
- (C) UDP报文
- (D) TCP报文
答案与解析
- 试题难度:一般
- 知识点:计算机网络>常见TCP/IP协议基础
- 试题答案:[[A],[A]]
- 试题解析:
在TCP/IP体系结构中,ARP协议数据单元封装在以太网的数据帧中传送,实现IP地址到MAC地址的转换,如下图所示。
第 49 题
802.11标准定义的分布式协调功能采用了()协议。
- (A) CSMA/CD
- (B) CSMA/CA
- (C) CDMA/CD
- (D) CDMA/CA
答案与解析
- 试题难度:较难
- 知识点:计算机网络>网络接入技术
- 试题答案:[[B]]
- 试题解析:
IEEE 802.11标准定义的分布式协调功能采用了载波监听多路访问肿突避免(CSMA/CA协议)。在无线网中进行冲突检测是有困难的。例如,两个站由于距离过大或中间障碍物的分隔而检测不到冲突,但是位于它们之间的第三个站可能会检测到冲突,这就是所谓隐蔽终端问题。采用冲突避免的办法可以解决隐蔽终端的问题。802.11定义了一个帧间隔(Inter Frame Spacing ,IFS )时间。另外还有一个后退计数器,其初始值是由随机数发生器设置的,递减计数直到0。基本的操作过程如下:
(1)如果一个站有数据要发送并且监听到信道忙,则产生一个随机数设置自己的后退计数器并坚持监听;
(2)监听到信道空闲后等待一个IFS时间,然后开始计数,最先计数完的站可以开始发送;
(3)其他站在监听到有新的站开始发送后暂停计数,在新的站发送完成后再等待一个 IFS时间继续计数,直到计数完成开始发送。
CSMA/CA协议可以采用载波检测方法发现信道空闲,也可以采用能量检测方法发现信道空闲。这个算法对参与竞争的站是公平的,基本上是按先来先服务的顺序获得发送的机会。
第 50 题
设有两个子网202.118.133.0/24和202.118.130.0/24,如果进行路由汇聚,得到的网络地址是()。
- (A) 202.118.128.0/21
- (B) 202.118.128.0/22
- (C) 202.118.130.0/22
- (D) 202.118.132.0/20
答案与解析
- 试题难度:一般
- 知识点:计算机网络>子网划分与路由汇聚
- 试题答案:[['A']]
- 试题解析:
网络202.118.133.0/24的二进制表示为:11001010 01110110 10000101 00000000
网络202.118.130.0/24的二进制表示为:11001010 01110110 10000010 00000000
两者的共同部分是(见黑体部分): 11001010 01110110 10000000 00000000
所以经路由汇聚后得到的超网为202.118.128.0/21
第 51 题
路由器收到一个数据包,其目标地址为195.26.17.4,该地址属于()子网。
- (A) 195.26.0.0/21
- (B) 195.26.16.0/20
- (C) 195.26.8.0/22
- (D) 195.26.20.0/22
答案与解析
- 试题难度:一般
- 知识点:计算机网络>子网划分与路由汇聚
- 试题答案:[['B']]
- 试题解析:
网络195.26.0.0/21的二进制表示为: 11000011 00011010 00000 000 00000000
网络195.26.16.0/20的二进制表示为:11000011 00011010 0001 0000 00000000
网络195.26.8.0/22的二进制表示为: 11000011 00011010 000010 00 00000000
网络195.26.20.0/22的二进制表示为:11000011 00011010 000101 00 00000000
地址195.26.17.4二进制表示为: 11000011 00011010 00010001 00000100
可以看出,选项B中的网络与地址195.26.17.4满足最长匹配规则,所以地址195.26.17.4所属的子网是195.25.16.0/20。
第 52 题
NAC’s(Network Access Control)role is to restrict network access to only compliant endpoints and()users.However, NAC is not a complete LAN()solution; additional proactive and()security measures must be implemented.Nevis is the first and only comprehensive LAN security solution that combines deep security processing of every packet at 100Gbps, ensuring a high level of security plus application availability and performance.Nevis integrates NAC as the first line of LAN security()In addition to NAC,enterprises need to implement role-based network access control as well as critical proactive security measures-real-time, multilevel ()inspection and microsecond threat containment.
- (A) automated
- (B) distinguished
- (C) authenticated
- (D) destructed
- (A) crisis
- (B) security
- (C) favorable
- (D) excellent
- (A) constructive
- (B) reductive
- (C) reactive
- (D) productive
- (A) defense
- (B) intrusion
- (C) inbreak
- (D) protection
- (A) port
- (B) connection
- (C) threat
- (D) Insurance
答案与解析
- 试题难度:一般
- 知识点:专业英语>专业英语
- 试题答案:[[C],[B],[C],[A],[C]]
- 试题解析:
网络访问控制(NAC)的作用是限制对网络的访问,只允许注册的终端和认证的用户访问网络。然而MAC不是一个完整的LAM安全解决方案,另外还要实现主动的和被动的安全手段。Nevis是第一个也是仅有的全面的LAN安全解决方案,它以l0Gbps的速率对每一个分组进行深度的安全处理,在提供高级别安全的同时能保证网络应用的可利用性和适当的性能。Nevis集成了NAC作为LAM的第一道安全防线。此外,企业还需要实现基于角色的网络访问控制,以及起关键作用的主动安全测试—实时的多级安全威胁检测和微秒级的安全威胁堵截。集中的安全策略配置、管理和报告使其能够迅速地对问题进行分析,对用户的活动进行跟踪,这些都是实时可见的,也是历史可查的。
第 53 题
Virtualization is an approach to IT that pools and shares()so that utilization is optimized and supplies automatically meet demand.Traditional IT environments are often silos, where both technology and human()。 are aligned around an application or business function.With a virtualized(),people, processes, and technology are focused on meeting service levels,()is allocated dynamically, resources are optimized, and the entire infrastructure is simplified and flexible.We offer a broad spectrum of virtualization()that allows customers to choose the most appropriate path and optimization focus for their IT infrastructure resources.
- (A) advantages
- (B) resources
- (C) benefits
- (D) precedents
- (A) profits
- (B) costs
- (C) resources
- (D) powers
- (A) system
- (B) infrastructure
- (C) hardware
- (D) link
- (A) content
- (B) position
- (C) power
- (D) capacity
- (A) solutions
- (B) networks
- (C) interfaces
- (D) Connections
答案与解析
- 试题难度:一般
- 知识点:专业英语>专业英语
- 试题答案:[[B],[C],[B],[D],[A]]
- 试题解析:
虚拟化是IT行业缓存和共享资源的一种方法,通过这种方法可以更好地利用资源,并且自动提供资源以满足需求。传统的IT环境通常是一个竖井,技术和人力资源都是围绕应用或商业功能来安排的。利用虚拟化的架构,人员、过程和技术都集中于满足服务的程度,生产量被动态地分配,资源得到优化,而且整个架构得以简化,变得很灵活。我们提供了广泛的虚拟化解决方案,允许客户为他们的IT资源的基础架构选择最适用的路线和优化的重点。