201205软设上午真题
第 1 题
位于CPU与主存之间的高速缓冲存储器Cache用于存放部分主存数据的拷贝,主存地址与Cache地址之间的转换工作由( )完成。
- (A) 硬件
- (B) 软件
- (C) 用户
- (D) 程序员
答案与解析
- 试题难度:容易
- 知识点:计算机组成与体系结构>Cache
- 试题答案:[[A]]
- 试题解析:
从Cache-主存层次实现的目标看,一方面既要使CPU的访存速度接近于访Cache的速度,另一方面为用户程 序提供的运行空间应保持为主存容量大小的存储空间。在采用Cache-主存层次的系统中,Cache对用户程序而言是透明的,也就是说,用户程序可以不需 要知道Cache的存在。因此,CPU每次访存时,依然和未使用Cache的情况一样,给出的是一个主存地址。但在Cache-主存结构中,CPU首先访问的是Cache,并不是主存。为此,需要一种机制将CPU的访主存地址转换成访Cache地址,这个处理过程对速度要求非常高,因此其是完全由硬件来完成的。
第 2 题
内存单元按字节编址,地址0000A000H~0000BFFFH共有( )个存储单元。
- (A) 8192K
- (B) 1024K
- (C) 13K
- (D) 8K
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>主存编址计算
- 试题答案:[[D]]
- 试题解析:
本题考查计算机中的存储部件组成
内存按字节编址,地址从0000A000H到0000BFFFH时,存储单元数为0000BFFFH -0000A000H +1H=00002000H,转换为二进制后为0010 0000 0000 0000即213,即8K个存储单元。
第 3 题
相联存储器按( )访问。
- (A) 地址
- (B) 先入后出的方式
- (C) 内容
- (D) 先入先出的方式
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>层次化存储体系
- 试题答案:[[C]]
- 试题解析:
相联存储器一种按内容进行存储和访问的存储器。
第 4 题
若CPU要执行的指令为:MOV R1,#45(即将数值45传送到寄存器R1中),则该指令中采用的寻址方式为( )。
- (A) 直接寻址和立即寻址
- (B) 寄存器寻址和立即寻址
- (C) 相对寻址和直接寻址
- (D) 寄存器间接寻址和直接寻址
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>寻址方式
- 试题答案:[[B]]
- 试题解析:
本题主要考查各寻址方式。
立即寻址的特点是:指令的地址字段指出的不是操作数的地址,而是操作数本身;直接寻址特点是:在指令格式的地址字段中直接指出操作数在内存的地址;寄存器寻址的特点是:指令中给出的操作数地址不是内存的地址单元号,而是通用寄存器的编号(当操作数不放在内存中,而是放在CPU的通用寄存器中时,可采用寄存器寻址方式);寄存器间接寻址方式与寄存器寻址方式的区别在于:指令格式中操作数地址所指向的寄存器中存放的内容不是操作数,而是操作数的地址,通过该地址可在内存中找到操作数;相对寻址的特点是:把程序计数器PC的内容加上指令格式中的形式地址来形成操作数的有效地址。
在本题中,指令中的两个操作数,分别使用的是寄存器寻址和立即寻址,因为在这个指令中,其第一个操作数字段是一个寄存器编号,而第二个操作数字段就是操作数本身。
第 5 题
一条指令的执行过程可以分解为取指、分析和执行三步,在取指时间t取指=3△t、分析时间t分析=2△t、执行时间t执行=4△t的情况下,若按串行方式执行,则10条指令全部执行完需要( )△t;若按流水线的方式执行,则10条指令全部执行完需要( )△t。
- (A) 40
- (B) 70
- (C) 90
- (D) 100
- (A) 20
- (B) 30
- (C) 40
- (D) 45
答案与解析
- 试题难度:容易
- 知识点:计算机组成与体系结构>流水线技术
- 试题答案:[[C],[D]]
- 试题解析:
串行执行时,每条指令都需三步才能执行完,没有重叠。总的执行时间为:(3+2+4)△t×10=90△t。
按流水线方式执行,系统在同一时刻可以进行第k条指令的取指,第k+1条指令的分析,第k+2条指令的执行,所以效率大大提高了。我们平时用的流水线计算公式是:第一条指令顺序执行时间+(指令条数-1)*周期,而周期与三个步骤时间最长的一段保持一致,因此本题的计算结果为:9+(10-1)*4=45。
第 6 题
甲和乙要进行通信,甲对发送的消息附加了数字签名,乙收到该消息后利用( )验证该消息的真实性。
- (A) 甲的公钥
- (B) 甲的私钥
- (C) 乙的公钥
- (D) 乙的私钥
答案与解析
- 试题难度:一般
- 知识点:信息安全>信息摘要与数字签名
- 试题答案:[[A]]
- 试题解析:
数字签名技术是对非对称加密技术与信息摘要的综合应用。通常的做法是:先对正文产生信息摘要,之后使用发送者A的私钥对该信息摘要进行加密,这就完成了签名。当接收者B收到签了名的摘要以后,会对摘要使用发送者A的公钥进行解密(认证),若能认证,则表明该信息确实是由A发送的。这就是数字签名技术。
第 7 题
在Windows系统中,默认权限最低的用户组是( )。
- (A) everyone
- (B) administrators
- (C) power users
- (D) users
答案与解析
- 试题难度:一般
- 知识点:操作系统>其它
- 试题答案:[[A]]
- 试题解析:
Everyone即所有的用户,计算机上的所有用户都属于这个组,它的默认权限最低。
Administrators即管理员组,默认情况下,Administrators中的用户对计算机/域有不受限制的完全访问权。分配给该组的默认权限允许对整个系统进行完全控制,该组拥有最高的默认权限。
power users即高级用户组,它可以执行除了为 Administrators 组保留的任务外的其他任何操作系统任务,它的默认权限仅次于Administrators。
Users即普通用户组,这个组的用户无法进行有意或无意的改动。因此,用户可以运行经过验证的应用程序,但不可以运行大多数旧版应用程序。Users 组是最安全的组,因为分配给该组的默认权限不允许成员修改操作系统的设置或用户资料。
第 8 题
IIS6.0支持的身份验证安全机制有4种验证方法,其中安全级别最高的验证方法是( )。
- (A) 匿名身份验证
- (B) 集成Windows身份验证
- (C) 基本身份验证
- (D) 摘要式身份验证
答案与解析
- 试题难度:一般
- 知识点:信息安全>其它
- 试题答案:[[B]]
- 试题解析:
为了阻止对Web站点未经授权的访问,可以对用户进行身份验证,拒绝不能提供有效Windows用户名和密码的用户的访问。其中IIS6.0支持的身份验证安全机制有以下4种验证方法:
(1) 匿名访问
匿名验证使用户无需输入用户名或密码便可以访问Web或FTP站点的公共区域,是默认的认证方式。当用户使用匿名验证访问公共Web和FTP站点时,IIS服务器向用户分配特定的Windows用户帐号IUSR_computername,computername是指运行IIS的服务器名称。默认情况下,IUSR_computername帐户包含在Windows用户组Guests中。
(2) 基本身份验证
基本验证在允许用户访问某个站点之前,提示用户在“登录”对话框中输入用户名和密码,然后Web浏览器尝试使用这些信息建立连接。如果输入的用户名和密码有效,则建立连接,否则Web浏览器将反复显示“登录”对话框,直到用户输入有效的用户名和密码或关闭此对话框。
(3) 摘要式身份验证
摘要式验证的验证过程与基本验证类似,但在传送验证信息时使用了不同方法。基本验证使用明码传输,因而是不安全的;而摘要式验证的验证凭据则采用单向传送的“散列算法”。
摘要式验证是HTTP 1.1的一项新功能,并非所有的浏览器都支持它。如果不兼容的浏览器对服务器请求摘要式验证,服务器将拒绝请求并向客户端发送错误消息。
(4) 集成式Windows身份验证
集成Windows验证(以前称 NTLM 或 Windows NT 质询/响应验证)是一种安全的验证形式,这是因为用户名和密码不通过网络发送,使用的是在客户端当前的Windows登录信息。当启用集成Windows验证时,用户的浏览器通过与Web服务器进行密码交换,包括散列,来证明其知晓密码,它是安全级别最高的验证方法。
第 9 题
软件著作权的客体不包括( )。
- (A) 源程序
- (B) 目标程序
- (C) 软件文档
- (D) 软件开发思想
答案与解析
- 试题难度:容易
- 知识点:法律法规与标准化>保护范围与对象
- 试题答案:[[D]]
- 试题解析:
软件著作权的客体是指计算机软件,即计算机程序及其有关文档。计算机程序是指为了得到某种结果而可以由计算机等具有信息处理能力的装置执行的代码化指令序列,或者可以被自动转换成代码化指令序列的符号化序列或者符号化语句序列。同一计算机程序的源程序和目标程序为同一作品。文档是指用来描述程序的内容、组成、设计、功能规格、开发情况、测试结果及使用方法的文字资料和图表等,如程序说明、流程图、用户手册等。
在本题描述的4个选项中,D不属于软件著作权的客体。
第 10 题
中国企业M与美国公司L进行技术合作,合同约定M使用一项在有效期内的美国专利,但该项美国专利未在中国和其他国家提出申请。对于M销售依照该专利生产的产品,以下叙述正确的是( )。
- (A) 在中国销售,M需要向L支付专利许可使用费
- (B) 返销美国,M不需要向L支付专利许可使用费
- (C) 在其他国家销售,M需要向L支付专利许可使用费
- (D) 在中国销售,M不需要向L支付专利许可使用费
答案与解析
- 试题难度:一般
- 知识点:法律法规与标准化>侵权判断
- 试题答案:[[D]]
- 试题解析:
本题的正确答案选D,因为该技术只在美国申请了专利,且在有效期内,而在中国和其他国家未提出申请,因此不受这些国家的专利权保护,因此在中国或其他国家销售,M不需要向L支付专利许可使用费。
第 11 题
使用( )DPI的分辨率扫描一幅2×4英寸的照片,可以得到一幅300×600像素的图像。
- (A) 100
- (B) 150
- (C) 300
- (D) 600
答案与解析
- 试题难度:容易
- 知识点:多媒体基础>多媒体相关计算问题
- 试题答案:[['B']]
- 试题解析:
DPI即每英寸的点数,根据题目的描述,我们不难知道(300×600)/(2×4)=150 * 150 。
第 12 题
计算机数字音乐合成技术主要有( )两种方式,其中使用( )合成的音乐,其音质更好。
- (A) FM和AM
- (B) AM和PM
- (C) FM和PM
- (D) FM和Wave Table
- (A) FM
- (B) AM
- (C) PM
- (D) Wave Table
答案与解析
- 试题难度:一般
- 知识点:多媒体基础>多媒体技术基本概念
- 试题答案:[[D],[D]]
- 试题解析:
目前,计算机数字音乐合成技术主要有FM和Wave Table,其中FM即频率调制,在电子音乐合成技术中,是最有效的合成技术之一,而WaveTable即波形表合成,它是一种真实的音乐合成技术,其合成的音乐音质更好。
第 13 题
数据流图(DFD)对系统的功能和功能之间的数据流进行建模,其中顶层数据流图描述了系统的( )。
- (A) 处理过程
- (B) 输入与输出
- (C) 数据存储
- (D) 数据实体
答案与解析
- 试题难度:一般
- 知识点:软件工程>数据流图与数据字典
- 试题答案:[[B]]
- 试题解析:
数据流图主要由实体、数据存储、处理过程和数据流四部分组成。在顶层数据流图中,将系统描述成一个处理过程,而其它的是与该处理过程相关的输入输出流,因此顶层数据流图描述了系统的输入与输出。
第 14 题
模块A执行几个逻辑上相似的功能,通过参数确定该模块完成哪一个功能,则该模块具有( )内聚
- (A) 顺序
- (B) 过程
- (C) 逻辑
- (D) 功能
答案与解析
- 试题难度:一般
- 知识点:软件工程>内聚性
- 试题答案:[[C]]
- 试题解析:
内聚是指模块内部各元素之间联系的紧密程度,模块的内聚类型通常可以分为7种,根据内聚度从高到低排序分别如下:
功能内聚:完成一个单一功能,各个部分协同工作,缺一不可。
顺序内聚:处理元素相关,而且必须顺序执行。
通信内聚:所有处理元素集中在一个数据结构的区域上。
过程内聚:处理元素相关,而且必须按特定的次序执行。
瞬时内聚:所包含的任务必须在同一时间间隔内执行(如初始化模块)。
逻辑内聚:完成逻辑上相关的一组任务。
偶然内聚:完成一组没有关系或松散关系的任务。
第 15 题
下图是一个软件项目的活动图,其中顶点表示项目里程碑,连接顶点的边表示包含的活动,边上的值表示完成活动所需要的时间,则( )在关键路径上。
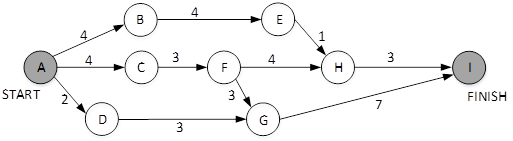
- (A) B
- (B) C
- (C) D
- (D) H
答案与解析
- 试题难度:容易
- 知识点:项目管理>Gant图与Pert图
- 试题答案:[[B]]
- 试题解析:
本题主要考查关键路径求解的问题。
从开始顶点到结束顶点的最长路径为关健路径(临界路径),关键路径上的活动为关键活动。
在本题中找出的最长路径是Start->C->F->G-->Finish,其长度为4+3+3+7=17,而其它任何路径的长度都比这条路径小,因此我们可以知道里程碑C在关键路径上。
第 16 题
( )最不适于采用无主程序员组的开发人员组织形式。
- (A) 项目开发人数少(如3~4人)的项目
- (B) 采用新技术的项目
- (C) 大规模项目
- (D) 确定性较小的项目
答案与解析
- 试题难度:一般
- 知识点:项目管理>其它
- 试题答案:[[C]]
- 试题解析:
大规模项目最不适于采用无主程序员组的开发人员组织形式,因为大项目需要主程序员来整合各模块程序。
第 17 题
若软件项目组对风险采用主动的控制方法,则( )是最好的风险控制策略。
- (A) 风险避免
- (B) 风险监控
- (C) 风险消除
- (D) 风险管理及意外事件计划
答案与解析
- 试题难度:较难
- 知识点:项目管理>风险管理
- 试题答案:[[A]]
- 试题解析:
风险避免即放弃或不进行可能带来损失的活动或工作。例如,为了避免洪水风险,可以把工厂建在地势较高、排水方便的地方,这是一种主动的风险控制方法。
风险监控是指在决策主体的运行过程中,对风险的发展与变化情况进行全程监督,并根据需要进行应对策略的调整。
风险管理是指在一个肯定有风险的环境里把风险减至最低的管理过程。对于风险我们可以转移,可以规避,但不能消除。
第 18 题
对于逻辑表达式“x and y or not z”,and、or、not分别是逻辑与、或、非运算,优先级从高到低为not、and、or,and、or为左结合,not为右结合,若进行短路计算,则( )。
- (A) x为真时,整个表达式的值即为真,不需要计算y和z的值
- (B) x为假时,整个表达式的值即为假,不需要计算y和z的值
- (C) x为真时,根据y的值决定是否需要计算z的值
- (D) x为假时,根据y的值决定是否需要计算z的值
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>逻辑运算
- 试题答案:[[C]]
- 试题解析:
本题主要考查逻辑与、或运算。
逻辑与运算需要考虑两个操作数的值,对于本题的运算优先级,最后计算的是逻辑或运算,而逻辑或只要第一个操作数为真,那么整个计算结果即为真,这种情况下无需考虑其第二个操作数的值。
对于逻辑或的两端分别为(x and y)和(not z),如果前者为真,则不用计算其他表达式,只有当x为真且y也为真时,整个表达式不需要计算(not z)部分,因此本题的答案选C。
第 19 题
对于二维数组a[1..N,1..N]中的一个元素a[i,j](1≤i,j≤N),存储在a[i,j]之前的元素个数( )。
- (A) 与按行存储或按列存储方式无关
- (B) 在i=j时与按行存储或按列存储方式无关
- (C) 在按行存储方式下比按列存储方式下要多
- (D) 在按行存储方式下比按列存储方式下要少
答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>数组与矩阵
- 试题答案:[[B]]
- 试题解析:
按行存储即先存储完第一行元素,再开始存储第二行元素,依次类推。按列存储即先存储完第一列元素,再开始存储第二列元素,依次类推。
因为按行存储和按列存储是两种不同的存储方式,因此在本题中,存储在a[i,j]之前的元素个数与存储方式的选择有关。另外,由于二维数组a的行和列都是n,是相等的,那么在i=j(即行等于列)的情况下,存储元素的个数也是与存储方式无关的。
第 20 题
算术表达式x-(y+c)*8的后缀式是( )(-、+、*表示算术的减、加、乘运算,运算符的优先级和结合性遵循惯例)。
- (A) x y c 8 - + *
- (B) x y - c + 8 *
- (C) x y c 8 * - +
- (D) x y c + 8 * -
答案与解析
- 试题难度:容易
- 知识点:程序设计语言基础>后缀表达式
- 试题答案:[[D]]
- 试题解析:
后缀表示也称为表达式的逆波兰表示。在这种表示方法中,将运算符号写在运算对象的后面,表达式中的运算符号按照计算次序书写。
对于表达式x-(y+c)*8,先计算y与c的和,再乘以8,最后用x减去这个这个计算,因此其后缀式为xyc+8*-。
第 21 题
若某企业拥有的总资金数为15,投资4个项目P1、P2、P3、P4,各项目需要的最大资金数分别是6、8、8、10,企业资金情况如图a所示。P1新申请2个资金,P2新申请1个资金,若企业资金管理处为项目P1和P2分配新申请的资金,则P1、P2、P3、P4尚需的资金数分别为( );假设P1已经还清所有投资款,企业资金使用情况如图b所示,那么企业的可用资金数为( )。若在图b所示的情况下,企业资金管理处为P2、P3、P4各分配资金数2、2、3,则分配后P2、P3、P4已用资金数分别为( )。
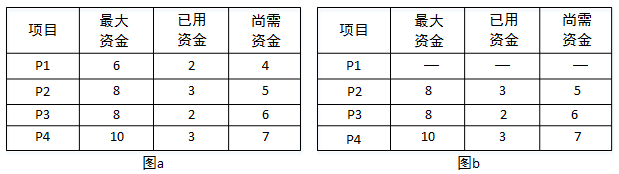
- (A) 1、3、6、7,可用资金数为0,故资金周转状态是不安全的
- (B) 2、5、6、7,可用资金数为1,故资金周转状态是不安全的
- (C) 2、4、6、7,可用资金数为2,故资金周转状态是安全的
- (D) 3、3、6、7,可用资金数为2,故资金周转状态是安全的
- (A) 4
- (B) 5
- (C) 6
- (D) 7
- (A) 3、2、3.尚需资金数分别为5、6、7,故资金周转状态是安全的
- (B) 5、4、6,尚需资金数分别为3、4、4,故资金周转状态是安全的
- (C) 3、2、3,尚需资金数分别为5、6、7,故资金周转状态是不安全的
- (D) 5、4、6,尚需资金数分别为3、4、4,故资金周转状态是不安全的
答案与解析
- 试题难度:一般
- 知识点:操作系统>银行家算法
- 试题答案:[[C],[D],[D]]
- 试题解析:
从图a我们可以看出,P1、P2、P3、P4尚需的资金数分别4、5、6、7,而目前再给P1分配2个资金、给P2分配1个资金,那么P1、P2、P3、P4尚需的资金数分别4-2=2,5-1=4,6,7。
如果P1已经还清所有投资款,再结合b图,已用资金和为:3+2+3=8,那么剩余的可用资金为15-8=7。
从b图不难看出,P2、P3、P4目前已经分别分配了3、2、3个资金,再给他们分别分配2、2、3个资金后,他们的已用资金数应分别为5、4、6,尚需资金数分别为8-5=3,8-4=4,10-6=4,此时资金已全部用完,但无法完成任何一个项目,因此资金周转状态是不安全的。
第 22 题
假设一台按字节编址的16位计算机系统,采用虚拟页式存储管理方案,页面的大小为2K,且系统中没有使用快表(或联想存储器)。某用户程序如图a所示,该程序的页面变换表如图b所示,表中状态位等于1和0分别表示页面在内存或不在内存。
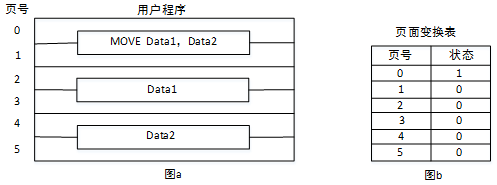
图a中MOVE Data1,Data2是一个4字节的指令,Data1和Data2表示该指令的两个32位操作数。假设MOVE指令存放在2047地址开始的内存单元中,Data1存放在6143地址开始的内存单元中,Data2存放在10239地址开始的内存单元中,那么执行MOVE指令将产生( )次缺页中断,其中:取指令产生( )次缺页中断,取Data1和Data2操作数分别产生( )次缺页中断。
- (A) 3
- (B) 4
- (C) 5
- (D) 6
- (A) 0
- (B) 1
- (C) 2
- (D) 3
- (A) 1、1
- (B) 1、2
- (C) 2、2
- (D) 2、3
答案与解析
- 试题难度:一般
- 知识点:操作系统>其它
- 试题答案:[['C'],['B'],['C']]
- 试题解析:
这个题目从其描述来看,非常复杂,但结合图来看,其实非常简单,从图a我们可以看出,MOVE执行属于页面0和1,而Data1属于页面2和3,Data2属于页面4和5,另外,结合图b可以看出,编号为1、2、3、4、5的页面都不在内存中,如果要取这几个页面的数据,必须先将其置换进内存,因此总共是5次缺页中断,其中取指令产生1次缺页中断,取Data1和Data2操作数分别产生2次缺页中断。
第 23 题
软件开发的增量模型( )。
- (A) 最适用于需求被清晰定义的情况
- (B) 是一种能够快速构造可运行产品的好方法
- (C) 最适合于大规模团队开发的项目
- (D) 是一种不适用于商业产品的创新模型
答案与解析
- 试题难度:一般
- 知识点:软件工程>开发模型
- 试题答案:[[B]]
- 试题解析:
增量模型是一种非整体开发的模型,该模型具有较大的灵活性,适合于软件需求不明确的一种模型。使用该模型开发产品,一般是尽快构造出可运行的产品,然后在该产品的基础上再增加需要的新的构建,使产品更趋于完善。
第 24 题
假设某软件公司与客户签订合同开发一个软件系统,系统的功能有较清晰的定义,且客户对交付时间有严格要求,则该系统的开发最适宜采用( )。
- (A) 瀑布模型
- (B) 原型模型
- (C) V模型
- (D) 螺旋模型
答案与解析
- 试题难度:一般
- 知识点:软件工程>开发模型
- 试题答案:[[A]]
- 试题解析:
瀑布模型严格遵循软件生命周期各阶段的固定顺序:计划、分析、设计、编程、测试和维护,上一阶段完成后才能进入到下一阶段。瀑布模型的优点是:可强迫开发人员采用规范的方法;严格规定了各阶段必须提交的文档;要求每个阶段结束后,都要进行严格的评审。但瀑布模型过于理想化,而且缺乏灵活性,无法在开发过程中逐渐明确用户难以确切表达或一时难以想到的需求。该模型比较适合于需求明确,对交付时间有严格要求的开发。
原型模型基于这样一种客观事实:并非所有的需求在系统开发之前都能准确地说明和定义。因此,它不追求也不可能要求对需求的严格定义,而是采用了动态定义需求的方法。它适用于需求不明确的开发环境。
螺旋模型综合了瀑布模型和演化模型的优点,还增加了风险分析。螺旋模型包含了四个方面的活动:制订计划、风险分析、实施工程、客户评估。采用螺旋模型时,软件开发沿着螺旋线自内向外旋转,每转一圈都要对风险进行识别和分析,并采取相应的对策。螺旋模型比较适合大规模的开发,它对风险控制有很高的要求。
综上所述,要满足题目描述的要求,应该采用瀑布模型开发最适宜。
第 25 题
某企业由于外部市场环境和管理需求的变化对现有软件系统提出新的需求,则对该软件系统进行的维护属于( )维护。
- (A) 正确性
- (B) 完善性
- (C) 适应性
- (D) 预防性
答案与解析
- 试题难度:一般
- 知识点:软件工程>软件维护类型
- 试题答案:[[C]]
- 试题解析:
改正性维护:在软件交付使用后,必然会有一部分隐藏的错误被带到运行阶段来。这些隐藏下来的错误在某些特定的使用环境下就会暴露出来。为了纠正这些错误而对软件进行的维护工作就是改正性维护。
适应性维护:随着计算机的飞速发展,外部环境(新的硬、软件配置)或数据环境(数据库、数据格式、数据输入∕输出方式、数据存储介质)或应用环境可能发生变化,为了使软件适应这种变化,而去修改软件的过程就叫做适应性维护。
完善性维护:在软件的使用过程中,用户往往会对软件提出新的功能与性能要求。为了满足这些要求,需要修改或再开发软件,以扩充软件功能、增强软件性能、改进加工效率、提高软件的可维护性。这种情况下进行的维护活动叫做完善性维护。
预防性维护:为了提高软件的可维护性、可靠性等而提出的一种维护类型,它为以后进一步改进软件打下良好基础。通常,预防性维护定义为:“把今天的方法学用于昨天的系统以满足明天的需要”。也就是说,采用先进的软件工程方法对需要维护的软件或软件中的某一部分(重新)进行设计、编制和测试。
综上所述,本题的正确答案应选C。
第 26 题
McCall软件质量模型从软件产品的运行、修正和转移三个方面确定了11个质量特性,其中( )不属于产品运行方面的质量特性。
- (A) 正确性
- (B) 可靠性
- (C) 效率
- (D) 灵活性
答案与解析
- 试题难度:一般
- 知识点:软件工程>软件质量特性
- 试题答案:[[D]]
- 试题解析:
McCall软件质量模型从软件产品的运行、修正和转移三个方面确定了11个质量特性,其中运行方面包含了正确性、可靠性、效率、完整性、使用性这些质量特性。修正方面包含了维护性、测试性、灵活性这3个质量特性。转移方面包含了维护性移植性、复用性、共运行性这3个质量特性。
第 27 题
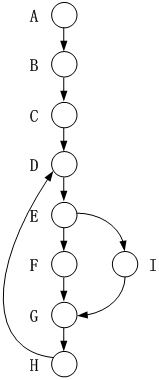
采用McCabe度量法计算下列程序图的环路复杂性为( )。
- (A) 2
- (B) 3
- (C) 4
- (D) 5
答案与解析
- 试题难度:容易
- 知识点:软件工程>McCabe复杂度计算
- 试题答案:[[B]]
- 试题解析:
McCabe度量法是一种基于程序控制流的复杂性度量方法。采用这种方法要先画出程序图,然后采用公式V(G)=m-n+2计算环路复杂度。其中,m是图G中弧的个数,n是图G中的结点数。本题图中结点数为9,边数为10,所以环路复杂度为10-9+2=3。
第 28 题
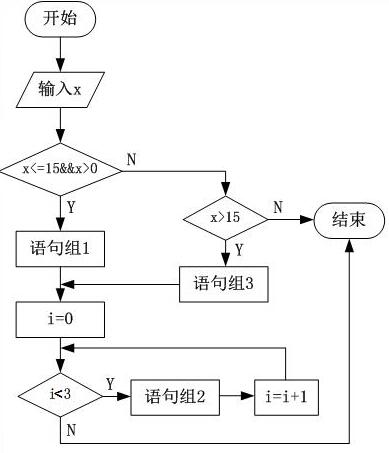
在白盒测试法中,( )是最弱的覆盖准则。下图至少需要( )个测试用例才可以完成路径覆盖,语句组2不对变量i进行操作。
- (A) 语句
- (B) 条件
- (C) 判定
- (D) 路径
- (A) 1
- (B) 2
- (C) 3
- (D) 4
答案与解析
- 试题难度:一般
- 知识点:软件工程>白盒测试用例
- 试题答案:[[A],[C]]
- 试题解析:
白盒测试常用的技术是逻辑覆盖,即考查用测试数据运行被测程序时对程序逻辑的覆盖程度。主要的覆盖标准有六种:语句覆盖、判定覆盖、条件覆盖、判定/条件覆盖、组合条件覆盖和路径覆盖。
(1)语句覆盖
语句覆盖是指选择足够多的测试用例,使得运行这些测试用例时,被测程序的每个语句至少执行一次。很显然,语句覆盖是一种很弱的覆盖标准。
(2)判定覆盖
判定覆盖又称分支覆盖,它的含义是,不仅每个语句至少执行一次,而且每个判定的每种可能的结果(分支)都至少执行一次。判定覆盖比语句覆盖强,但对程序逻辑的覆盖程度仍然不高。
(3)条件覆盖
条件覆盖的含义是,不仅每个语句至少执行一次,而且使判定表达式中的每个条件都取到各种可能的结果。条件覆盖不一定包含判定覆盖,判定覆盖也不一定包含条件覆盖。
(4)判定/条件覆盖
同时满足判定覆盖和条件覆盖的逻辑覆盖称为判定/条件覆盖。它的含义是,选取足够的测试用例,使得判定表达式中每个条件的所有可能结果至少出现一次,而且每个判定本身的所有可能结果也至少出现一次。
(5)条件组合覆盖
条件组合覆盖的含义是,选取足够的测试用例,使得每个判定表达式中条件结果的所有可能组合至少出现一次。显然,满足条件组合覆盖的测试用例,也一定满足判定/条件覆盖。因此,条件组合覆盖是上述五种覆盖标准中最强的一种。然而,条件组合覆盖还不能保证程序中所有可能的路径都至少经过一次。
(6)路径覆盖
路径覆盖的含义是,选取足够的测试用例,使得程序的每条可能执行到的路径都至少经过一次(如果程序中有环路,则要求每条环路径至少经过一次)。路径覆盖实际上考虑了程序中各种判定结果的所有可能组合,因此是一种较强的覆盖标准。
本题的第二问比较复杂,关键是我们要清楚程序流程图中有几条路径,然后为每条路径设置一个测试用例。
在本题给出的程序流程图中,如果我们将判定“x<=15&&x>0”规定为第1个判定,“x>15”规定为第2个判定,“i<3”规定为第3个判定的话,那么本题中的路径有:第1个判定为N,第2个判定为N;第1个判定为N,第2个判定为Y,第3个判定一直为Y,后再取N(这里要注意,由于在第3个判定前,给i赋初值为0,因此这个判定每次都是先为Y,循环后再为N);第1个判定为Y,第3个判定先为Y,然后再为N。总共只有这3条路径,因此至少需要设置3个测试用例来满足路径覆盖。
第 29 题
根据ISO/IEC 9126软件质量模型中对软件质量特性的定义,可维护性质量特性的( )子特性是指与为确认经修改软件所需努力有关的软件属性。
- (A) 易测试性
- (B) 易分析性
- (C) 稳定性
- (D) 易改变性
答案与解析
- 试题难度:较难
- 知识点:软件工程>软件质量特性
- 试题答案:[[A]]
- 试题解析:
可维护性质量特性是指与软件维护的难易程度相关的一组软件属性,它包含了易分析性、稳定性、易测试性和易改变性4个子特性。其中:
易分析性是描述诊断缺陷或失效原因、判定待修改程度的难易程度的特性。
稳定性是描述修改造成难以预料的后果的风险程度,风险程度越低,稳定性越好。
易测试性是描述测试已修改软件的难易程度的特性。
易改变性是描述修改、排错或适应环境变化的难易程度。
本题中,是说与为确认经修改软件所需努力有关的软件属性,也就是说要确认修改后的软件是否正确所要付出的努力,这应该是易测试性所描述的内容,因此本题答案选A。
第 30 题
面向对象技术中,组合关系表示( )。
- (A) 包与其中模型元素的关系
- (B) 用例之间的一种关系
- (C) 类与其对象的关系
- (D) 整体与其部分之间的一种关系
答案与解析
- 试题难度:一般
- 知识点:面向对象技术>UML图中的关系
- 试题答案:[[D]]
- 试题解析:
在面向对象技术中,组合描述的是整体与部分的关系,组合关系中,整体与部分的生命周期一致。比如公司与部门就是一种组合关系,公司不存在了,部门自然就不存在了。
第 31 题
以下关于封装在软件复用中所充当的角色的叙述,正确的是( )。
- (A) 封装使得其他开发人员不需要知道一个软件组件内部如何工作
- (B) 封装使得软件组件更有效地工作
- (C) 封装使得软件开发人员不简要编制开发文档
- (D) 封装使得软件组件开发更加容易
答案与解析
- 试题难度:一般
- 知识点:面向对象技术>面向对象的基本概念
- 试题答案:[[A]]
- 试题解析:
封装是面向对象技术的三大特点之一,封装的目的是使对象的定义和实现分离,这样,就能减少耦合。封装可以使得其他开发人员不需要知道一个软件组件内部是如何工作的,只需要使用该组件提供的接口来完成交互即可,如果在另外一个地方需要完成同样的功能,我们就可以将该组件使用在另外一个地方,这样提供了软件的复用性。
第 32 题
在有些程序设计语言中,过程调用和响应调用需执行的代码的绑定直到运行时才进行,这种绑定称为( )。
- (A) 静态绑定
- (B) 动态绑定
- (C) 过载绑定
- (D) 强制绑定
答案与解析
- 试题难度:容易
- 知识点:面向对象技术>面向对象的基本概念
- 试题答案:[[B]]
- 试题解析:
动态绑定是指在执行期间(非编译期)判断所引用对象的实际类型,根据其实际的类型调用其相应的方法。而静态绑定是指在程序编译期就完成的绑定。
第 33 题
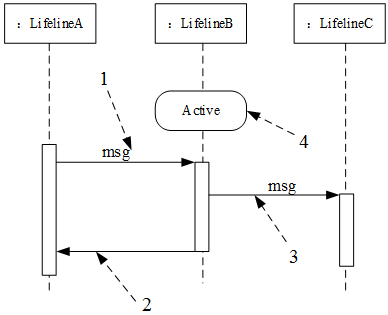
UML序列图是一种交互图,描述了系统中对象之间传递消息的时间次序。其中,异步消息与同步消息不同,( )。下图中( )表示一条同步消息,( )表示一条异步消息,( )表示一条返回消息。
- (A) 异步消息并不引起调用者终止执行而等待控制权的返回
- (B) 异步消息和阻塞调用有相同的效果
- (C) 异步消息是同步消息的响应
- (D) 异步消息和同步消息一样等待返回消息
- (A) 1
- (B) 2
- (C) 3
- (D) 4
- (A) 1
- (B) 2
- (C) 3
- (D) 4
- (A) 1
- (B) 2
- (C) 3
- (D) 4
答案与解析
- 试题难度:一般
- 知识点:面向对象技术>UML图的图示
- 试题答案:[[A],[A],[C],[B]]
- 试题解析:
在本题中,首先我们要理解同步消息与异步消息的区别。如果一个对象发送了一个同步消息,那么它要等待对方对消息的应答,收到应答后才能继续自己的操作。而发送异步消息的对象不需要等待对方对消息的应答便可以继续自己的操作。
在本题中,1表示的是同步消息,而2表示的是返回消息,3表示的是异步消息。一般情况下,在顺序图中,同步消息、异步消息、返回消息都是用本题图中的箭头表示,请注意它们的区别。
第 34 题
设计模式根据目的进行分类,可以分为创建型、结构型和行为型三种。其中结构型模式用于处理类和对象的组合。( )模式是一种结构型模式。
- (A) 适配器( Adapter)
- (B) 命令(Command)
- (C) 生成器(Builder)
- (D) 状态(State)
答案与解析
- 试题难度:一般
- 知识点:面向对象技术>设计模式概述及分类
- 试题答案:[[A]]
- 试题解析:
常见的创建型模式主要有工厂方法(Factory Method)、抽象工厂(Abstract Factory)、单例(Singleton)、构建器(Builder)、原型(Prototype)模式;结构型模式有适配器(Adapter)、组合(Composite)、装饰(Decorator)、代理(Proxy)、享元(Flyweight)、外观(Façade)、桥接(Bridge)模式;行为型模式有策略(Strategy)、模板方法(Template Method)、迭代器(Iterator)、责任链(Chain of Responsibility)、命令(Command)、备忘录(Memento)、状态(State)、访问者(Visitor)、解释器((Interpreter)、中介者(Mediator)、观察者(Observer)模式。
第 35 题
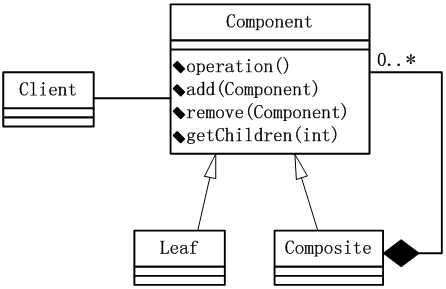
设计模式中的( )模式将对象组合成树形结构以表示“部分一整体”的层次结构,使得客户对单个对象和组合对象的使用具有一致性。下图为该模式的类图,其中,( )定义有子部件的那些部件的行为;组合部件的对象由( )通过component提供的接口操作。
- (A) 代理(Proxy)
- (B) 桥接器(Bridge)
- (C) 组合( Composite)
- (D) 装饰器(Decorator)
- (A) Client
- (B) Component
- (C) Leaf
- (D) Composite
- (A) Client
- (B) Component
- (C) Leaf
- (D) Composite
答案与解析
- 试题难度:一般
- 知识点:面向对象技术>设计模式的图
- 试题答案:[[C],[D],[A]]
- 试题解析:
本题主要组合设计模式。组合设计模式将对象组合成树形结构以表示“部分一整体”的层次结构,使得客户对单个对象和组合对象的使用具有一致性。
在类图中,Component为合成的对象声明接口;某些情况下,实现从此接口派生出所有类共有的默认行为,定义一个接口可以访问及管理它的多个部分(GetChild),如果必要也可以在递归结构中定义一个接口访问它的父节点,并且实现它;Leaf在合成中表示叶节点对象,叶节点没有子节点;Composite用来定义有子节点(子部件)的部件的行为,存储子节点(子部件);Client通过Component接口控制组合部分的对象。
第 36 题
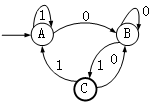
下图所示为一个有限自动机(其中,A是初态、C是终态),该自动机所识别的字符串的特点是( )。
- (A) 必须以11结尾的0、1串
- (B) 必须以00结尾的0、1串
- (C) 必须以01结尾的0、1串
- (D) 必须以10结尾韵0、1串
答案与解析
- 试题难度:容易
- 知识点:程序设计语言基础>有限自动机
- 试题答案:[[C]]
- 试题解析:
被有限自动机所识别是指从初态开始到终态结束,所输入的字符串能够按顺序地执行下去,若到某个状态不能往下走得到下一个字符,则认为不能识别。
在本题中,从初态A出发,不管经过多少个1和0之后,只能是处在A、B、C三种状态中的一种,所以在(0|1)*后,只能是处在A、B、C三种状态中的一种,不管是在那个状态,输入0后,都会处在状态B,然后输入1,都会转换到状态C,因此与本题有限自动机等价的正规式是(0|1)*01,即该自动机所识别的字符串的特点是必须以01结尾的0、1串。
第 37 题
E-R模型向关系模型转换时,三个实体之间多对多的联系m:n:p应该转换为一个独立的关系模式,且该关系模式的关键字由( )组成。
- (A) 多对多联系的属性
- (B) 三个实体的关键字
- (C) 任意一个实体的关键字
- (D) 任意两个实体的关键字
答案与解析
- 试题难度:一般
- 知识点:数据库系统>ER模型
- 试题答案:[[B]]
- 试题解析:
在E-R模型向关系模型转换时,如果是多对多的联系,那么这个联系需要转换为一个独立的关系模式,且该关系模式的属性由各实体的关键字和该联系自身的属性组成,而该关系模式的关键字(主键)由各实体的关键字组成。
第 38 题
函数(过程)调用时,常采用传值与传地址两种方式在实参与形参间传递信息。以下叙述中,正确的是( )。
- (A) 在传值方式下,将形参的值传给实参,因此,形参必须是常量或变量
- (B) 在传值方式下,将实参的值传给形参,因此,实参必须是常量或变量
- (C) 在传地址方式下,将形参的地址传给实参,因此,形参必须有地址
- (D) 在传地址方式下,将实参的地址传给形参,因此,实参必须有地址
答案与解析
- 试题难度:一般
- 知识点:程序设计语言基础>传值与传址
- 试题答案:[[D]]
- 试题解析:
形式参数就是过程定义中函数名后括号中所带的参数;实际参数是在调用点表示向被调用过程传递的数据。
在函数调用时,数据传递的方向是从实参到形参。只是采用传值传递方式时,传递的是数值,这个数值只要是确定的即可,可以是常量、变量或表达式等。而采用传址传递方式时,传递的是地址,因此实参必须有地址。
第 39 题
编译和解释是实现高级程序设计语言翻译的两种基本形式。以下关于编译与解释的叙述中,正确的是( )。
- (A) 在解释方式下,对源程序不进行词法分析和语法分析,直接进行语义分析
- (B) 在解释方式下,无需进行词法、语法和语义分析,而是直接产生源程序的目标代码
- (C) 在编译方式下,必须进行词法、语法和语义分析,然后再产生源程序的目标代码
- (D) 在编译方式下,必须先形成源程序的中间代码,然后再产生与机器对应的目标代码
答案与解析
- 试题难度:一般
- 知识点:程序设计语言基础>编译与解释
- 试题答案:[[C]]
- 试题解析:
编译和解释是语言处理的两种基本方式。编译过程包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等阶段,以及符号表管理与出错处理模块。
解释过程在词法、语法和语义分析方面与编译程序的工作原理基本相同,但是在运行用户程序时,它直接执行源程序或源程序的内部形式。
这两种语言处理程序的根本区别是:在编译方式下,机器上运行的是与源码程序等价的目标程序,源程序和编译程序都不再参与目标程序的执行过程;而在解释方式下,解释程序和源程序(或其某种等价表示)要参与到程序的运行过程中,运行程序的控制权在解释程序。
在编译方式下,词法、语法和语义分析是必须要进行的工作,而生产中间代码和优化则是可以进行也可以不进行。
第 40 题
若对关系R(A,B,C,D)进行π1,3(R)运算,则该关系运算与( )等价,表示( )。
- (A) πA=1,C=3(R)
- (B) πA=1∧C=3(R)
- (C) πA,C(R)
- (D) πA=1∨C=3(R)
- (A) 属性A和C的值分别等于1和3的元组为结果集
- (B) 属性A和C的值分别等于1和3的两列为结果集
- (C) 对R关系进行A=1、C=3的投影运算
- (D) 对R关系进行属性A和C的投影运算
答案与解析
- 试题难度:一般
- 知识点:数据库系统>关系代数
- 试题答案:[[C],[D]]
- 试题解析:
本题主要考查关系运算。
投影运算是从一个关系里面抽取指明的属性(列)组成一个新的关系,这种运算是一种对列进行操作的运算。本题中π1,3(R)的含义就是从关系R中,选取第1列(A)和第3列(C)组成一个新的关系模式,因此52题答案选C,而53题的答案选D。
第 41 题
某销售公司数据库的零件关系P(零件号,零件名称,供应商,供应商所在地,库存量),函数依赖集F={零件号→零件名称,(零件号,供应商)→库存量,供应商→供应商所在地)。零件关系模式P属于( )。
查询各种零件的平均库存量、最多库存量与最少库存量之间差值的SQL语句如下:
SELECT零件号,零件名称,( ),
FROM P
( );
- (A) 1NF
- (B) 2NF
- (C) 3NF
- (D) 4NF
- (A) AVG(库存量)AS平均库存量,MAX(库存量)-MIN(库存量)AS差值
- (B) 平均库存量AS AVG(库存量),差值AS MAX(库存量)-MIN(库存量)
- (C) AVG库存量AS平均库存量,MAX库存量-MIN库存量AS差值
- (D) 平均库存量AS AVG库存量,差值AS MAX库存量-MIN库存量
- (A) ORDER BY供应商
- (B) ORDER BY零件号
- (C) GROUP BY供应商
- (D) GROUP BY零件号
答案与解析
- 试题难度:一般
- 知识点:数据库系统>分组查询语句
- 试题答案:[[A],[A],[D]]
- 试题解析:
要求一个关系模式属于第几范式,一个很重要的步骤就是求出该关系模式的主键,在本题中,根据函数依赖集F,我们不难知道,零件关系P的主键为(零件号,供应商),因为从这两个属性出发可以推导出所有其它属性。在求出主键后,我们再看是否存在部分依赖,很显然零件号→零件名称是部分依赖,因此该关系模式不满足2NF,而只满足1NF。
对于第(55)空,根据题目要求,是要显示各种零件的平均库存量以及最多库存量与最少库存量之间差值,求平均库存量可以用函数AVG,而求最多库存量和最小库存量分别用函数MAX和MIN。AS是取别名的意思,因此本题答案选A。
根据题目意思,是要显示各零件的平均库存量以及最多库存量与最少库存量之间差值,那么这里就需要按零件的种类对查询的结果进行分组,因此第(56)空应该填GROUP BY零件号。
第 42 题
对于一个长度大于1且不存在重复元素的序列,令其所有元素依次通过一个初始为空的队列后,再通过一个初始为空的栈。设队列和栈的容量都足够大,一个序列通过队列(栈)的含义是序列的每个元素都入队列(栈)且出队列(栈)一次且仅一次。对于该序列在上述队列和栈上的操作,正确的叙述是( )。
- (A) 出队序列和出栈序列一定相同
- (B) 出队序列和出栈序列一定互为逆序
- (C) 入队序列与出队序列一定相同,入栈序列与出栈序列不一定相同
- (D) 入栈序列与出栈序列一定互为逆序,入队序列与出队序列不一定互为逆序
答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>队列与栈
- 试题答案:[[C]]
- 试题解析:
本题主要考查队列和栈的特性。队列具有先进先出的特点,而栈具有后进先出的特点。因此我们可以知道入队序列与出队序列一定相同,但入栈序列与出栈序列不一定相同。比如a,b,c这样一个序列,那么按照a,b,c的顺序入队列,那么其出队列的次序一定是a,b,c。而按照a,b,c的顺序入栈,那么可能是a入栈后就出栈,然后b入栈又出栈,然后C入栈出栈。也可能是等a,b,c都入栈后再出栈,那么出栈序列就是c,b,a。
第 43 题
在字符串的KMP模式匹配锋法中,需要求解模式串p的next函数值,其定义如下所示。若模式串p为“aaabaaa”,则其next函数值为( )。
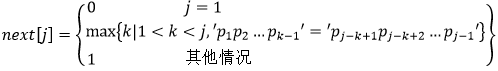
- (A) 0123123
- (B) 0123210
- (C) 0123432
- (D) 0123456
答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>字符串
- 试题答案:[['A']]
- 试题解析:
KMP模式匹配算法通俗点说就是一种在一个字符串中定位另一个串的高效算法。其实我们在做这个题目时,也可以不需要知道KMP模式匹配算法,可以根据题目给出的定义式来求解。
【对于本题公式】
1、当j=1时,由(1)式,next[1]=0;
2、当j!=1时,由(2)式,max{k|1<k<j 'p1p2...pk-1'='pj-k+1pj-k+2...pj-1'},即选择符合要求的最大k值,要求:1<k<j ,并且满足 'p1p2...pk-1'='pj-k+1pj-k+2...pj-1',如果有满足要求的k值,则next[j]=max{k};如果找不到满足条件的k值,则由(3)式next[j]=1。
3、取值范围,j、k都为正整数,且1<=j<=5
【求取next[]过程如下】1、当j=1时,由(1)式,next[1]=0;
2、当j=2时,找不到满足1<k<j的数k,由(3)式,next[2]=1;
3、当j=3时,满足1<k<j的数k=2,同时需要满足'p1p2...pk-1'='pj-k+1pj-k+2...pj-1'。'p1p2...pk-1'= 'p1p2...p1'=p1,为第一个字母a;'pj-k+1pj-k+2...pj-1'='p2p3...p2'=p2,为第二个字母a,此时,k满足条件,由(2)式,next[3]=k=2。
4、当j=4时,满足1<k<j的数k=2或3:
(1)当k=2,'p1p2...pk-1'= 'p1p2...p1'=p1,为第一个字母a,'p1p2...pk-1'= 'p3p4...p3'=p3,为第三个字母a,满足 'p1p2...pk-1'='pj-k+1pj-k+2...pj-1'。
(2)当k=3,'p1p2...pk-1'= 'p1p2...p2'=p1p2,为第一二字母aa,'pj-k+1pj-k+2...pj-1'='p2p3...p3'=p2p3,为第二三个字母aa,'p1p2...pk-1'='pj-k+1pj-k+2...pj-1'。
因此next[4]=max{2,3}=3。
5、j=5,满足1<k<j的数k=2、3或4:
(1)当k=2,'p1p2...pk-1'= 'p1p2...p1'=p1,为第一个字母a,'p1p2...pj-1'= 'p4p5...p4'=p4,为第四个字母b,不满足 'p1p2...pk-1'='pj-k+1pj-k+2...pj-1'。
(2)当k=3,'p1p2...pk-1'= 'p1p2...p2'=p1p2,为第一二字母aa,'pj-k+1pj-k+2...pj-1'='p3p4...p4'=p3p4,为第三四个字母ab,不满足 'p1p2...pk-1'='pj-k+1pj-k+2...pj-1'。
(3)当k=4,'p1p2...pk-1'= 'p1p2Lp3'=p1p2p3,为第一二三字母aaa,'pj-k+1pj-k+2...pj-1'='p2p3...p4'=p2p3p4,为第二三四个字母aab,不满足 'p1p2...pk-1'='pj-k+1pj-k+2...pj-1'。
因此,当j=5时,没有满足条件k,此时由(3)式,next[5]=1。同理我们可以求得当j=6,j=7的结果,本题正确答案选A。
第 44 题
若n2、n1、n0分别表示一个二叉树中度为2、度为1和叶子结点的数目(结点的度定义为结点的子树数目),则对于任何一个非空的二叉树,( )。
- (A) n2一定大于n1
- (B) n1一定大于n0
- (C) n2一定大于n0
- (D) n0一定大于n2
答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>树与二叉树的特性
- 试题答案:[[D]]
- 试题解析:
根据二叉树的性质,我们知道n0=n2+1,因此在一棵二叉树中,叶子结点的数目一定是大于度为2的结点的个数。
第 45 题
从存储空间的利用率角度来看,以下关于数据结构中图的存储的叙述,正确的是( )。
- (A) 有向图适合采用邻接矩阵存储,无向图适合采用邻接表存储
- (B) 无向图适合采用邻接矩阵存储,有向图适合采用邻接表存储
- (C) 完全图适合采用邻接矩阵存储
- (D) 完全图适合采用邻接表存储
答案与解析
- 试题难度:较难
- 知识点:数据结构与算法基础>图的定义及存储
- 试题答案:[['C']]
- 试题解析:
本题主要考查图的存储结构,常见的图的存储结构有邻接矩阵存储和邻接表存储,其中在邻接矩阵存储方式中,矩阵中每个元素的值都表示两个点之间的边的信息,如果每两个点之间都有变的信息,那么矩阵中的所有元素都是有效元素,那么从存储空间的利用率角度来看,其利用率较高,而采用邻接表存储其存储空间利用率肯定低于邻接矩阵,因为采用邻接表存储,不仅要存储边的信息,还要存储节点信息,指针信息等。
这种情况下,这个图很显然是一个完全图,因此从存储空间的利用率角度来看,完全图适合采用邻接矩阵存储。
第 46 题
递增序列A(a1,a2,…,an)和B (b1,b2,…,bn)的元素互不相同,若需将它们合并为一个长度为2n的递增序列,则当最终的排列结果为( )时,归并过程中元素的比较次数最多。
- (A) a1,a2,…,an,b1,b2,…,bn
- (B) b1,b2,…,bn,a1,a2,…,an
- (C) a1,b1,a2,b2,…,ai,bi,…,an,bn
- (D) a1,a2,…,ai/2,b1,b2,…,bi/2,ai/2+1,ai/2+2,…,an,bi/2+1,…,bn
答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>排序
- 试题答案:[[C]]
- 试题解析:
要将两个有序序列归并为一个有序序列时,当一个序列的最大值小于另一个序列的最小值时,这时需要比较的次数最小。当获得新序列后,两个序列的元素交替的情况(如选项C),这种情况下需比较的次数最多。
第 47 题
以下关于渐近符号的表示中,不正确的是( )。
- (A)
- (B)
- (C)
- (D)
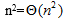

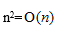
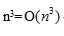
答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>时间复杂度与空间复杂度
- 试题答案:[[C]]
- 试题解析:
很明显,在本题中错误的是C选项的描述。
第 48 题
某货车运输公司有一个中央仓库和n个运输目的地,每天要从中央仓库将货物运输到所有运输目的地,到达每个运输目的地一次且仅一次,最后回到中央仓库。在两个地点i和j之间运输货物存在费用Cij。为求解旅行费用总和最小的运输路径,设计如下算法:首先选择离中央仓库最近的运输目的地1,然后选择离运输目的地1最近的运输目的地2,…,每次在需访问的运输目的地中选择离当前运输目的地最近的运输目的地,最后回到中央仓库。刚该算法采用了( )算法设计策略,其时间复杂度为( )。
- (A) 分治
- (B) 动态规划
- (C) 贪心
- (D) 回溯
- (A)
- (B)
- (C)
- (D)
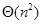
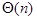
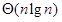
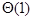
答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>贪心法
- 试题答案:[[C],[A]]
- 试题解析:

第 49 题
现要对n个实数(仅包含正实数和负实数)组成的数组A进行重新排列,使得其中所有的负实数都位于正实数之前。求解该问题的算法的伪代码如下所示,则该算法的时间和空间更杂度分别为( )。
i=0;j=n-1;
while i<j do
while A[i]<0 do
i= i+1;
while A[j]>0 do
j =j-1;
if i<j do
交换A[i]和A[j];
- (A)
- (B)
- (C)
- (D)




答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>时间复杂度与空间复杂度
- 试题答案:[[C]]
- 试题解析:
根据程序不难看出,要将负实数位于正实数之前,其实就是对所有元素进行了一次遍历,正实数和负实数互换位置即可,因此其时间复杂度为O(n),由于元素A[i]和A[j]互换时,需要一个临时存储空间来存放元素,因此其空间复杂度为O(1)。
第 50 题
以下关于网络中各种交换设备的叙述中,错误的是( )。
- (A) 以太网交换机根据MAC地址进行交换
- (B) 帧中继交换机只能根据虚电路号DLCI进行交换
- (C) 三层交换机只能根据第三层协议进行交换
- (D) ATM交换机根据虚电路标识进行信元交换
答案与解析
- 试题难度:一般
- 知识点:计算机网络>开放系统互连参考模型
- 试题答案:[[C]]
- 试题解析:
交换机有多种,共同的特点都是根据某种标识把输入数据包交换到输出端口。以太网交换机根据MAC地址进行交换:帧中继交换机根据虚电路号DLCI进行交换:Internet中使用的三层交换机根据IP地址进行转发,并根据MAC地址进行交换:ATM交换机根据虚电路标识VPI和VCI进行交换。
第 51 题
SMTP传输的邮件报文采用( )格式表示。
- (A) ASCII
- (B) ZIP
- (C) PNP
- (D) HTML
答案与解析
- 试题难度:一般
- 知识点:计算机网络>协议应用提升
- 试题答案:[[A]]
- 试题解析:
ASCII即美国信息互换标准代码,是一种基于拉丁字母的一套电脑编码系统。SMTP传输的邮件报文采用的就是这种编码。
ZIP是一种计算机文件的压缩算法,能减少文件的大小,有利用数据存储和传输。
PNP即即插即用技术,是系统自动侦测周边设备和板卡并自动安装设备驱动程序,做到插上就能用,无须人工干预。
HTML即超文本标记语言,是用于描述网页文档的一种标记语言。我们上网浏览的网页很多就是采用这种格式。
第 52 题
网络的可用性是指( )。
- (A) 网络通信能力的大小
- (B) 用户用于网络维修的时间
- (C) 网络的可靠性
- (D) 用户可利用网络时间的百分比
答案与解析
- 试题难度:一般
- 知识点:计算机网络>其它
- 试题答案:[[D]]
- 试题解析:
网络的可用性是指用户可利用网络时间的百分比。
第 53 题
建筑物综合布线系统中的园区子系统是指( )。
- (A) 由终端到信息插座之间的连线系统
- (B) 楼层接线间到工作区的线缆系统
- (C) 各楼层设备之间的互连系统
- (D) 连接各个建筑物的通信系统
答案与解析
- 试题难度:一般
- 知识点:计算机网络>其它
- 试题答案:[[D]]
- 试题解析:
综合布线分六大子系统。
1、工作区子系统(Worklocation):目的是实现工作区终端设备与水平子系统之间的连接,由终端设备连接到信息插座的连接线缆所组成。工作区常用设备是计算机、网络集线器(Hub或Mau)、电话、报警探头、摄像机、监视器、音响等。
2、水平子系统(Horizontal):目的是实现信息插座和管理子系统(跳线架)间的连接,将用户工作区引至管理子系统,并为用户提供一个符合国际标准,满足语音及高速数据传输要求的信息点出口。该子系统由一个工作区的信息插座开始,经水平布置到管理区的内侧配线架的线缆所组成。
3、管理子系统(Administration):本子系统由交连、互连配线架组成。管理间为连接其它子系统提供连接手段。交连和互连允许将通讯线路定位或重定位到建筑物的不同部分,以便能更容易地管理通信线路,使在移动终端设备时能方便地进行插拔。互连配线架根据不同的连接硬件分楼层配线架(箱)IDF和总配线架(箱)MDF,IDF可安装在各楼层的干线接线间,MDF一般安装在设备机房。
4、垂直干线子系统(Backbone):目的是实现计算机设备、程控交换机(PBX)、控制中心与各管理子系统间的连接,是建筑物干线电缆的路由。该子系统通常是两个单元之间,特别是在位于中央点的公共系统设备处提供多个线路设施。系统由建筑物内所有的垂直干线多对数电缆及相关支撑硬件组成,以提供设备间总配线架与干线接线间楼层配线架之间的干线路由。常用介质是大对数双绞线电缆和光缆。
5、设备室子系统(Equipment):本子系统主要是由设备间中的电缆、连接器和有关的支撑硬件组成,作用是将计算机、PBX、摄像头、监视器等弱电设备互连起来并连接到主配线架上。设备包括计算机系统、网络集线器(Hub)、网络交换机(Switch)、程控交换机(PBX)、音响输出设备、闭路电视控制装置和报警控制中心等。
6、建筑群子系统(Campus):即园区子系统,该子系统将一个建筑物的电缆延伸到建筑群的另外一些建筑物中的通信设备和装置上,是结构化布线系统的一部分,支持提供楼群之间通信所需的硬件。
第 54 题
如果子网172.6.32.0/20被划分为子网172.6.32.0/26,则下面的结论中正确的是( )。
- (A) 被划分为62个子网
- (B) 每个子网有64个主机地址
- (C) 被划分为31个子网
- (D) 每个子网有62个主机地址
答案与解析
- 试题难度:一般
- 知识点:计算机网络>子网划分与路由汇聚
- 试题答案:[[D]]
- 试题解析:
在本题中,我们关键要了解IP地址斜杠后面的20和26表示的含义,这个数字是说明该IP地址网络号的位数,那么子网172.6.32.0/20变成172.6.32.0/26,又多出了6位网络号,即可以划分出2的6次方个子网,即64个子网,而172.6.32.0/26中还有32-26=6位的主机号,因此每个子网可以有26-2=62个主机地址(主机号部分全0和全1的除外)。因此本题答案选D。
第 55 题
At a basic level, cloud computing is simply a means of delivering IT resources as( ). Almost all IT resources can be delivered as a cloud service: applications, compute power, storage capacity, networking, Programming tools, even communication services and collaboration( ).
Cloud computing began as large-scale Internet service providers such as Google, Amazon, and others built out their infrastructure. An architecture emerged: massively scaled,( )distributed system resources, abstracted as virtual IT services and managed as continuously configured, pooled resources. In this architecture, the data is mostly resident on( )"somewhere on the Internet" and the application runs on both the "cloud servers" and the user's browser.
Both clouds and grids are built to scale horizontally very efficiently. Both are built to withstand failures of( )elements or nodes. Both are charged on a per-use basis. But while grids typically process batch jobs, with a defined start and end point, cloud services can be continuous. What's more, clouds expand the types of resources available - file storage, databases, and Web services - and extend the applicability to Web and enterprise applications.
- (A) hardware
- (B) computers
- (C) services
- (D) software
- (A) computers
- (B) disks
- (C) machines
- (D) tools
- (A) horizontally
- (B) vertically
- (C) inclined
- (D) decreasingly
- (A) clients
- (B) middleware
- (C) servers
- (D) hard disk
- (A) entire
- (B) individual
- (C) general
- (D) separate
答案与解析
- 试题难度:一般
- 知识点:专业英语>专业英语
- 试题答案:[[C],[D],[A],[C],[B]]
- 试题解析:
基本上,云计算仅仅意味着将IT资源作为服务来提供。几乎所有的IT资源都可以作为一个云服务来提供:如应用程序,计算能力,存储容量,网络,编程工具,甚至通讯服务和协作工具。
开始大规模提供云计算的互联网服务提供商有谷歌,亚马逊和其他一些基础建设商。云架构的特点是:系统不断扩大,水平分布系统资源,抽象的虚拟服务和管理,然后不断配置,汇集资源。在这种体系结构中,数据主要存放在“互联网某处”的服务器和“云服务”与客户端运行的应用程序上。
要想建立一个能收取使用费的云网格,必须要建立经得起单个元素或节点失败的云网格。当用网格来处理一批日常工作时,需要定义一个明确的开始和结束点,云服务可以是连续的。但更重要的是,云可以扩展可用的文件存储,数据库,网络服务来适用于网络和企业应用。