201405软设上午真题
第 1 题
在CPU中,常用来为ALU执行算术逻辑运算提供数据并暂存运算结果的寄存器是( )。
- (A) 程序计数器
- (B) 状态寄存器
- (C) 通用寄存器
- (D) 累加寄存器
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>CPU的组成(运算器与控制器)
- 试题答案:[['D']]
- 试题解析:本题考查寄存器的类型和特点。寄存器是CPU中的一个重要组成部分,它是CPU内部的临时存储单元。寄存器既可以用来存放数据和地址,也可以存放控制信息或CPU工作时的状态。在CPU中增加寄存器的数量,可以使CPU把执行程序时所需的数据尽可能地放在寄存器件中,从而减少访问内存的次数,提高其运行速度。但是寄存器的数目也不能太多,除了增加成本外,由于寄存器地址编码增加也会对增加指令的长度。CPU中的寄存器通常分为存放数据的寄存器、存放地址的寄存器、存放控制信息的寄存器、存放状态信息的寄存器和其他寄存器等类型。
程序计数器用于存放指令的地址。令当程序顺序执行时,每取出一条指令,PC内容自动增加一个值,指向下一条要取的指令。当程序出现转移时,则将转移地址送入PC,然后由PC指向新的程序地址。
程序状态寄存器用于记录运算中产生的标志信息,典型的标志为有进位标志位、零标志位、符号标志位、溢出标志位、奇偶标志等。
地址寄存器包括程序计数器、堆栈指示器、变址寄存器、段地址寄存器等,用于记录各种内存地址。
累加寄存器是一个数据寄存器,在运算过程中暂时存放被操作数和中间运算结果,累加器不能用于长时间地保存一个数据。
第 2 题
某机器字长为n,最高位是符号位,其定点整数的最大值为( )。
- (A) 2n-1
- (B) 2n-1-1
- (C) 2n
- (D) 2n-1
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>码制(原码/反码/补码/移码)
- 试题答案:[['B']]
- 试题解析:如下图所示:
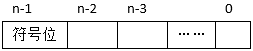
最大值为n-1位(符号位)为0(正数),从n-2到0位都为1,值为2n-1-1。
第 3 题
海明码利用奇偶性检错和纠错,通过在n个数据位之间插入k个检验位,扩大数据编码的码距。若n=48,则k应为( )。
- (A) 4
- (B) 5
- (C) 6
- (D) 7
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>海明校验码
- 试题答案:[['C']]
- 试题解析:设:N为待发送海明码的总位数,n是有效信息位数,r是校验位个数(分成r组作奇偶校验,能产生r位检错信息)校验位的个数r应满足公式 :N=n+r ≤ 2r-1。此题中n = 48,校验位个数为k,则n+k≤2k-1,即48+k≤2k-1,则k为6。
第 4 题
通常可以将计算机系统中执行一条指令的过程分为取指令,分析和执行指令3步。若取指令时间为4△t,分析时间为2△t。执行时间为3△t,按顺序方式从头到尾执行完600条指令所需时间为( )△t;若按照执行第i条,分析第i+1条,读取第i+2条重叠的流水线方式执行指令,则从头到尾执行完600条指令所需时间为( )△t。
- (A) 2400
- (B) 3000
- (C) 3600
- (D) 5400
- (A) 2400
- (B) 2405
- (C) 3000
- (D) 3009
答案与解析
- 试题难度:容易
- 知识点:计算机组成与体系结构>流水线技术
- 试题答案:[['D'],['B']]
- 试题解析:按顺序方式执行时间为(4+2+3)△t * 600=5400△t流水线方式:单条指令所需时间+(n-1)*(流水线周期),其中,流水线周期是指:指令分段执行中时间最长的一段。该题中时间最长的一段为4△t,所以流水线的周期为:4△t;所以该题按照流水线方式执行的时间为:(4+2+3)△t+(600-1)4△t=2405△t
第 5 题
若用256K×8bit的存储器芯片,构成地址40000000H到400FFFFFH且按字节编址的内存区域,则需( )片芯片。
- (A) 4
- (B) 8
- (C) 16
- (D) 32
答案与解析
- 试题难度:一般
- 知识点:计算机组成与体系结构>主存编址计算
- 试题答案:[['A']]
- 试题解析:内存区域从40000000H到40000000H,则其拥有的字节数为:400FFFFFH-40000000H+1 = 100000H=220=1024K
该内存区域有1024K个字节,其空间表示为1024K×8bit,题干中给出一个芯片的空间容量为256K × 8bit,需要的此空间大小的芯片数量为(1024K×8)/(256K × 8)= 4片。
第 6 题
以下关于木马程序的叙述中,正确的是( )。
- (A) 木马程序主要通过移动磁盘传播
- (B) 木马程序的客户端运行在攻击者的机器上
- (C) 木马程序的目的是使计算机或网络无法提供正常的服务
- (D) Sniffer是典型的木马程序
答案与解析
- 试题难度:一般
- 知识点:信息安全>计算机病毒与木马
- 试题答案:[['B']]
- 试题解析:传播方式:1、通过邮件附件、程序下载等形式传播,因此A选项错误。
2、通过伪装网页登录过程,骗取用户信息进而传播
3、通过攻击系统安全漏洞传播木马,大量黑客使用专门的黑客工具来传播木马。木马程序危害在于多数有恶意企图,例如占用系统资源,降低电脑效能,危害本机信息安全(盗取QQ账号、游戏账号甚至银行账号),将本机作为工具来攻击其他设备等,因此,C选项错误;
4、Sniffer 是用于拦截通过网络传输的TCP/IP/UDP/ICMP等数据包的一款工具,可用于分析网络应用协议,用于网络编程的调试、监控通过网络传输的数据、检测木马程序等,因此D选项错误。
本题只有B选项是正确的。
第 7 题
- (A) 防火墙工作层次越低,工作效率越高,安全性越高
- (B) 防火墙工作层次越低,工作效率越低,安全性越低
- (C) 防火墙工作层次越高,工作效率越高,安全性越低
- (D) 防火墙工作层次越高,工作效率越低,安全性越高
答案与解析
- 试题难度:一般
- 知识点:信息安全>防火墙技术
- 试题答案:[['D']]
- 试题解析:防火墙工作层次越低,工作效率越高,安全性越低。防火墙工作层次越高,工作效率越低,安全性越高。
第 8 题
以下关于包过滤防火墙和代理服务防火墙的叙述中,正确的是( )。
- (A) 包过滤成本技术实现成本较高,所以安全性能高
- (B) 包过滤技术对应用和用户是透明的
- (C) 代理服务技术安全性较高,可以提高网络整体性能
- (D) 代理服务技术只能配置成用户认证后才建立连接
答案与解析
- 试题难度:一般
- 知识点:信息安全>防火墙技术
- 试题答案:[['B']]
- 试题解析:包过滤防火墙工作在网络协议IP层,它只对IP包的源地址、目标地址及相应端口进行处理,因此速度比较快,能够处理的并发连接比较多,缺点是对应用层的攻击无能为力,包过滤成本与它的安全性能没有因果关系,而应用程序和用户对于包过滤的过程并不需要了解,因此该技术对应用和用户是透明的,本题选择B选项。代理服务器防火墙将收到的IP包还原成高层协议的通讯数据,比如http连接信息,因此能够对基于高层协议的攻击进行拦截。缺点是处理速度比较慢,能够处理的并发数比较少,所以不能提高网络整体性能,而代理对于用户认证可以设置。
第 9 题
王某买了一幅美术作品原件,则他享有该美术作品的( )。
- (A) 著作权
- (B) 所有权
- (C) 展览权
- (D) 所有权与其展览权
答案与解析
- 试题难度:一般
- 知识点:法律法规与标准化>保护范围与对象
- 试题答案:[['D']]
- 试题解析:展览权是原件持有人的特有的权利,著作权人不能以发表权限制其权利(除非有约定)。
所有权是所有人依法对自己财产所享有的占有,使用,收益和处分的权利。
第 10 题
甲、乙两软件公司于2012年7月12日就其财务软件产品分别申请“用友”和 “用有”商标注册。两财务软件相似,甲第一次使用时间为2009年7月,乙第一次使用时间为2009年5月。此情形下,( )能获准注册。
- (A) “用友”
- (B) “用友”与“用有”都
- (C) “用有”
- (D) 由甲、乙抽签结果确定
答案与解析
- 试题难度:一般
- 知识点:法律法规与标准化>知识产权人确定
- 试题答案:[['C']]
- 试题解析:
商标注册是指商标所有人为了取得商标专用权,将其使用的商标,依照法律的注册条件、原则和程序,向商标局提出注册申请,商标局经过审核,准予注册的法律制度。 注册商标时使用的商标标识须具备可视特征,且不得与他人先取得的合法权力相冲突,不得违反公序良俗。 具备可视性(显著性),要求必须为视觉可感知,可以是平面的文字、图形、字母、数字,也可以是三维立体标志或者颜色组合以及上述要素的组合。显著性要求商标的构成要素必须便于区别。但怎样的文字、图形和三维标志是具有显著特征的,我国商标法一般是从反面作出禁止性规定,凡是不含有禁用要素的商标(如同中华人民共和国的国旗、国徽相同或相近似的标识),就被视为具备显著性。显著性特征一般是指易于识别,即不能相同或相似。相同是指用于同一种或类似商品上的两个商标的文字、图形、字母、数字、三维标志或颜色组合相同。读音相同也属于相同商标,如“小燕”与“小雁”、“三九”与“999”属于相同商标。近似是指在文字的字形、读音、含义或者图形的构图及颜色或者文字与图形的整体结构上,与注册商标相比,易使消费者对商品的来源产生误认的商标。如虎、豹、猫图案外观近似;“娃哈哈”与“娃娃哈”读音近似;“长城”与“八达岭”,虽然读音、文字都不近似,但其所指的事物非常近似,其思想主题相同,也会引起消费者的误认。 不得与在先权利相冲突。在先权利是指在申请商标注册之前已有的合法权利 该题中两个商标违反了 “显著性”和“不得与在先权利相冲突”两项。所以“用友”不能获取注册。
第 11 题
以下媒体中,( )是表示媒体,( )是表现媒体。
- (A) 图像
- (B) 图像编码
- (C) 电磁波
- (D) 鼠标
- (A) 图像
- (B) 图像编码
- (C) 电磁波
- (D) 鼠标
答案与解析
- 试题难度:一般
- 知识点:多媒体基础>媒体的种类(显示媒体)
- 试题答案:[[B],[D]]
- 试题解析:表示媒体:表示媒体指的是为了传输感觉媒体而人为研究出来的媒体,借助于此种媒体,能有效地存储感觉媒体或将感觉媒体从一个地方传送到另一个地方。如语言编码、电报码、条形码等。
表现媒体:表现媒体指的是用于通信中使电信号和感觉媒体之间产生转换用的媒体。如输入、输出设备,包括键盘、鼠标器、显示器、打印机等。
第 12 题
( )表示显示器在横向(行)上具有的像素点数目。
- (A) 显示分辨率
- (B) 水平分辨率
- (C) 垂直分辨率
- (D) 显示深度
答案与解析
- 试题难度:容易
- 知识点:多媒体基础>多媒体技术基本概念
- 试题答案:[['B']]
- 试题解析:分辨率分为水平分辨率和垂直分辨率,在大多数情况下两者是相等的,因此在技术指标中一般仅给出水平分辨率,其度量单位电视线也往往简称为线。水平指横向上具有的像素点数目,垂直指纵向上具有的像素点数目。
第 13 题
以下关于结构化开发方法的叙述中,不正确的是( )。
- (A) 将数据流映射为软件系统的模块结构
- (B) 一般情况下,数据流类型包括变换流型和事务流型
- (C) 不同类型的数据流有不同的映射方法
- (D) 一个软件系统只有一种数据流类型
答案与解析
- 试题难度:容易
- 知识点:软件工程>软件开发方法
- 试题答案:[['D']]
- 试题解析:面向数据流的设计是以需求分析阶段产生的数据流图为基础,按一定的步骤映射成软件结构,因此又称结构化设计。该方法由美国IBM公司L.Constantine和E.Yourdon等人于1974年提出,与结构化分析(SA)衔接,构成了完整的结构化分析与设计技术,是目前使用最广泛的软件设计方法之一。各种软件系统,不论DFD如何庞大和复杂,一般可分为变换型和事务型,一个软件系统既可以只有一种数据流类型,也可以是两种数据流类型。在结构化设计中,可以将数据流映射为软件系统的模块结构,不同类型的数据流有不同的映射方法。
第 14 题
模块A提供某个班级某门课程的成绩给模块B,模块B计算平均成绩、最高分和最低分,将计算结果返回给模块A,则模块B在软件结构图中属于( )模块。
- (A) 传入
- (B) 传出
- (C) 变换
- (D) 协调
答案与解析
- 试题难度:一般
- 知识点:软件工程>其它
- 试题答案:[[C]]
- 试题解析:传入模块:从下属模块取得数据,经处理再将其传送给上级模块。
传出模块:从上级模块取得数据,经处理再将其传送给下属模块。变换模块:从上级模块取得数据,进行特定的处理,转换成其他形式,再传送给上级模块。
第 15 题
( )软件成本估算模型是一种静态单变量模型,用于对整个软件系统进行估算。
- (A) Putnam
- (B) 基本COCOMO
- (C) 中级COCOMO
- (D) 详细COCOMO
答案与解析
- 试题难度:一般
- 知识点:项目管理>软件项目估算
- 试题答案:[['B']]
- 试题解析:基本COCOMO是一种静态的单值模型,它使用以每千源代码行数(KLoC)来度量的程序大小来计算软件开发的工作量(及成本)。COCOMO可以应用于三种不同的软件项目:
有机项目-相对较小、较简单的软件项目,由较小的有经验的团队来完成,需求较少并且没有过份严格的限定。
中度分离项目-指中等规模(大小及复杂度)的软件项目,由不同经验水平的人组成的团队来完成,需求中即有严格的部分也有不太严格的部分。
嵌入式项目-指软件项目必须依赖于一套紧凑的硬件、软件以及符合操作限制。
第 16 题
以下关于进度管理工具Gantt图的叙述中,不正确的是( )。
- (A) 能清晰地表达每个任务的开始时间、结束时间和持续时间
- (B) 能清晰地表达任务之间的并行关系
- (C) 不能清晰地确定任务之间的依赖关系
- (D) 能清晰地确定影响进度的关键任务
答案与解析
- 试题难度:一般
- 知识点:项目管理>Gant图与Pert图
- 试题答案:[['D']]
- 试题解析:Gantt图是一种简单的水平条形图,以日历为基准描述项目任务。水平轴表示日历时间线(如时、天、周、月和年等),每个条形表示一个任务,任务名称垂直地列在左边的列中,图中水平条的起点和终点对应水平轴上的时间,分别表示该任务的开始时间和结束时间,水平条的长度表示完成该任务所持续的时间。当日历中同一时段存在多个水平条时,表示任务之间的并发。Gantt图能清晰地描述每个任务从何时开始,到何时结束,任务的进展情况以及各个任务之间的并行性。但是其缺点是不能清晰地反映出各任务之间的依赖关系,难以确定整个项目的关键所在,也不能反映计划中有潜力的部分。
第 17 题
项目复杂性、规模和结构的不确定性属于( )风险。
- (A) 项目
- (B) 技术
- (C) 经济
- (D) 商业
答案与解析
- 试题难度:一般
- 知识点:项目管理>风险管理
- 试题答案:[[A]]
- 试题解析:项目风险涉及到各种形式的预算、进度、人员、资源以及客户相关的问题,并且可能导致项目损失。
第 18 题
以下程序设计语言中,( )更适合用来进行动态网页处理。
- (A) HTML
- (B) LISP
- (C) PHP
- (D) JAVA/C++
答案与解析
- 试题难度:一般
- 知识点:程序设计语言基础>多种程序语言特点
- 试题答案:[[C]]
- 试题解析:HTML:静态网页
LISP:一种基于λ演算的函数式编程语言
PHP :混合了C、Java、Perl以及PHP自创的语法。它可以比CGI或者Perl更快速地执行动态网页。
第 19 题
引用调用方式下进行函数调用,是将( )。
- (A) 实参的值传递给形参
- (B) 实参的地址传递给形参
- (C) 形参的值传递给实参
- (D) 形参的地址传递给实参
答案与解析
- 试题难度:一般
- 知识点:程序设计语言基础>传值与传址
- 试题答案:[['B']]
- 试题解析:在函数调用时,系统为形参准备空间,并把实参的值赋值到形参空间中,在调用结束后,形参空间将被释放,而实参的值保持不变,这就是传值传递方式。传值传递方式中实参与形参之间的数据传递是单向的,只能由实参传递给形参,因而即使形参的值在函数执行过程中发生了变化,也不会影响到实参值。在C语言中,当参数类型是非指针类型和非数组类型时,均采用传值方式。传地址方式把实参的地址赋值给形参,这样形参就可以根据地址值访问和更改实参的内容,从而实现双向传递。当参数类型是指针类型或数组类型时,均采用传地址方式。
第 20 题
编译程序对高级语言源程序进行编译的过程中,要不断收集、记录和使用源程序中一些相关符号的类型和特征等信息,并将其存入( )中。
- (A) 符号表
- (B) 哈希表
- (C) 动态查找表
- (D) 栈和队列
答案与解析
- 试题难度:一般
- 知识点:程序设计语言基础>编译器工作过程
- 试题答案:[['A']]
- 试题解析:符号表:符号表是一种用于语言翻译器(例如编译器和解释器)中的数据结构。在符号表中,程序源代码中的每个标识符都和它的声明或使用信息绑定在一起,比如其数据类型、作用域以及内存地址。哈希表:也叫散列表,是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
动态查找表:动态查找表的表结构本身是在查找过程中动态生成的,即对于给定值key,若表中存在其关键字等于key的记录,则查找成功返回,否则插入关键字等于key的记录。
栈和队列:基本的数据结构。栈的基本特点是“后进先出”,而队列的基本特点是“先进先出”。
第 21 题
设计操作系统时不需要考虑的问题是( )。
- (A) 计算机系统中硬件资源的管理
- (B) 计算机系统中软件资源的管理
- (C) 用户与计算机之间的接口
- (D) 语言编译器的设计实现
答案与解析
- 试题难度:一般
- 知识点:操作系统>操作系统概述及作用
- 试题答案:[[D]]
- 试题解析:OS作为用户与计算机硬件之间的接口。OS作为计算机系统的资源管理者,可以管理计算机的软硬件资源。
第 22 题
假设某计算机系统中资源R的可用数为6,系统中有3个进程竞争R,且每个进程都需要i个R,该系统可能会发生死锁的最小i值是( )。若信号量S的当前值为-2,则R的可用数和等待R的进程数分别为( )。
- (A) 1
- (B) 2
- (C) 3
- (D) 4
- (A) 0、0
- (B) 0、1
- (C) 1、0
- (D) 0、2
答案与解析
- 试题难度:一般
- 知识点:操作系统>死锁资源数计算
- 试题答案:[['C'],['D']]
- 试题解析:当3个进程都占有2个R资源时,都需要再申请一个资源才能正常运行,此时会出现相互等待的状况。信号量为负值,说明此时系统中已经没有R资源了,此负值也代表正在等待R的进程数。
第 23 题
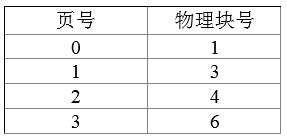
某计算机系统页面大小为4K,若进程的页面变换表如下所示,逻辑地址为十六进制1D16H。该地址经过变换后,其物理地址应为十六进制( )。
- (A) 1024H
- (B) 3D16H
- (C) 4D16H
- (D) 6D16H
答案与解析
- 试题难度:一般
- 知识点:操作系统>段式存储
- 试题答案:[['B']]
- 试题解析:
页式存储中的逻辑地址与物理地址之间的变换需要掌握变换的规则。
逻辑地址的构成是:逻辑页号+页内地址。
物理地址的构成是:物理块号+页内地址。
从构成可以看出逻辑地址与物理地址的页内地址是一样的,不同的是逻辑页号与物理块号。而这两者的关系,正是通过题目已给出的表来进行映射的。如逻辑页号1就对应着物理块号3。
所以题目告诉我们“逻辑地址为十六进制1D16H”时,我们先要把逻辑地址中的页号与页内地址分离。
通过什么条件分离呢?
题目中的“计算机系统页面大小为4K”,从这句话可以看出,页内地址是二进制的12位(4K=212)。二进制12位对应十六进制3位。
所以D16H是页内地址。页号也就是1了。通过页表查询到物理块号:3。所以物理地址是:3D16H。
第 24 题
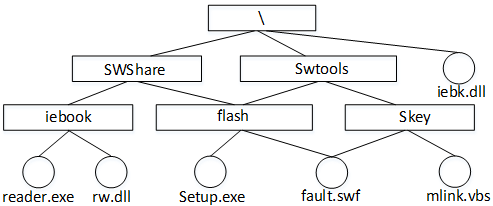
若某文件系统的目录结构如下图所示,假设用户要访问文件fault.swf,且当前工作目录为swshare,则该文件的全文件名为( ),相对路径和绝对路径分别为( )。
- (A) fauit.swf
- (B) \flash\fault.swf
- (C) swsshare\flash\fault.swf
- (D) \swshare\flash\fault.swf
- (A) swshare\flash\和\flash
- (B) flash\和\swshare\flash
- (C) \swshare\flash\和flash\
- (D) \flash\和\swshare\flash
答案与解析
- 试题难度:一般
- 知识点:操作系统>树形目录结构(绝对路径与相对路径)
- 试题答案:[['D'],['B']]
- 试题解析:
该题考查的是操作系统中文件管理的内容。
Windows操作系统中的文件目录结构:
在对数据文件进行操作时,一般要用盘符指出被操作的文件或目录在哪一磁盘。盘符也称驱动器名。
文件是按一定格式建立在外存储介质上的一组相关信息的集合。 计算机中的文件,一般上存储在磁盘、光盘或磁带中,如果没有特殊说明,我们认为文件上存储在磁盘上的,称为磁盘文件。每一个文件必须有一个名字,称为文件名。
文件目录,即Windows操作系统中的文件夹。为了实现对文件的统一管理,同时又方便用户,操作系统采用树状结构的目录来实现对磁盘上所有文件的组织和管理。根目录用“\”表示,从根目录或当前目录至所要找的文件或目录所需要经过的全部子目录的顺序组合。
绝对路径指的是从根目录开始到目标文件或目录的一条路径。所以fault.swf文件的绝对路径是“\swshare\flash\fault.swf”,即该文件的全文件名。
相对路径就是指由这个文件所在的路径引起的跟其他文件(或文件夹)的路径关系。使用相对路径可以为我们带来非常多的便利。“.”和“..”分别表示当前目录和上一级目录。 当前工作目录为swshare,该目录下swshare子目录中有文件fault.swf,所以fault.swf相对路径为flash。
第 25 题
以下关于统一过程UP的叙述中,不正确的是( )。
- (A) UP是以用例和风险为驱动,以架构为中心,迭代并且增量的开发过程
- (B) UP定义了四个阶段,即起始、精化、构建和确认阶段
- (C) 每次迭代都包含计划、分析、设计、构造、集成、测试以及内部和外部发布
- (D) 每个迭代有五个核心工作流
答案与解析
- 试题难度:一般
- 知识点:软件工程>开发模型
- 试题答案:[['B']]
- 试题解析:
什么是 Rational 统一过程( Rational Unified Process)?
Rational Unified Process 是软件工程的过程。它提供了在开发组织中分派任务和责任的纪律化方法。它的目标是在可预见的日程和预算前提下,确保满足最终用户需求的高质量产品。
统一过程模型是一种“用例驱动,以体系结构为核心,迭代及增量”的软件过程框架,由UML方法和工具支持。
RUP把一个项目分为四个不同的阶段:
构思阶段 :包括用户沟通和计划活动两个方面,强调定义和细化用例,并将其作为主要模型。
细化阶段 :包括用户沟通和建模活动,重点是创建分析和设计模型,强调类的定义和体系结构的表示。
构建阶段 :将设计转化为实现,并进行集成和测试。
移交阶段 :将产品发布给用户进行测试评价,并收集用户的意见,之后再次进行迭代修改产品使之完善。
没有确认阶段,因此B选项错误。
每个迭代有五个核心工作流:(1)捕获系统应该做什么的需求工作流;(2)精化和结构化需求的分析工作流;(3)在系统结构内实现需求的设计工作流;(4)构造软件的实习工作流;(5)验证是否如期那样工作的测试工作流。
第 26 题
某公司要开发一个软件产品,产品的某些需求是明确的,而某些需求则需要进一步细化。由于市场竞争的压力,产品需要尽快上市,则开发该软件产品最不适合采用( )模型。
- (A) 瀑布
- (B) 原型
- (C) 增量
- (D) 螺旋
答案与解析
- 试题难度:一般
- 知识点:软件工程>开发模型
- 试题答案:[[A]]
- 试题解析:瀑布模型(Waterfall Model) 是一个项目开发架构,开发过程是通过设计一系列阶段顺序展开的,从系统需求分析开始直到产品发布和维护,每个阶段都会产生循环反馈,因此,如果有信息未被覆盖或者发现了问题,那么最好 “返回”上一个阶段并进行适当的修改,项目开发进程从一个阶段“流动”到下一个阶段,这也是瀑布模型名称的由来。包括软件工程开发、企业项目开发、产品生产以及市场销售等构造瀑布模型。
第 27 题
在屏蔽软件错误的容错系统中,冗余附加技术的构成不包括( )。
- (A) 关键程序和数据的冗余存储及调用
- (B) 冗余备份程序的存储及调用
- (C) 实现错误检测和错误恢复的程序
- (D) 实现容错软件所需的固化程序
答案与解析
- 试题难度:一般
- 知识点:软件工程>软件容错技术
- 试题答案:[['A']]
- 试题解析:
冗余是指在正常系统运行所需的基础上加上一定数量的资源,包括信息、时间、硬件、和软件。冗余是容错技术的基础,通过冗余资源的加入,可以使系统的可靠性得到较大的提高。主要的冗余技术有结构冗余(硬件冗余和软件冗余)、信息冗余、时间冗余和冗余附加四种。
1.结构冗余
结构冗余是常用的冗余技术,按其工作方式,可分为静态冗余、动态冗余和混合冗余三种。
(1)静态冗余。静态冗余又称为屏蔽冗余或被动冗余,常用的有三模冗余和多模冗余。静态冗余通过表决和比较来屏蔽系统中出现的错误。例如,三模冗余是对三个功能相同,但由不同的人采用不同的方法开发出的模块的运行结果进行表决,以多数结果作为系统的最终结果。即如果模块中有一个出错,这个错误能够被其他模块的正确结果“屏蔽”。由于无需对错误进行特别的测试,也不必进行模块的切换就能实现容错,故称为静态容错。
(2)动态冗余。动态冗余又称为主动冗余,它是通过故障检测、故障定位及故障恢复等手段达到容错的目的。其主要方式是多重模块待机储备,当系统检测到某工作模块出现错误时,就用一个备用的模块来顶替它并重新运行。各备用模块在其待机时,可与主模块一样工作,也可不工作。前者叫做热备份系统(双重系统),后者叫做冷备份系统(双工系统、双份系统)。在热备份系统中,两套系统同时、同步运行,当联机子系统检测到错误时,退出服务进行检修,而由热备份子系统接替工作,备用模块在待机过程中其失效率为0;处于冷备份的子系统平时停机或者运行与联机系统无关的运算,当联机子系统产生故障时,人工或自动进行切换,使冷备份系统成为联机系统。在运行冷备份时,不能保证从系统断点处精确地连续工作,因为备份机不能取得原来的机器上当前运行的全部数据。
(3)混合冗余。混合冗余技术是将静态冗余和动态冗余结合起来,且取二者之长处。它先使用静态冗余中的故障屏蔽技术,使系统免受某些可以被屏蔽的故障的影响。而对那些无法屏蔽的故障则采用主动冗余中的故障检测、故障定位和故障恢复等技术,并且对系统可以作重新配置。因此,混合冗余的效果要大大优于静态冗余和动态冗余。然而,由于混合冗余既要有静态冗余的屏蔽功能,又要有动态冗余的各种检测和定位等功能,它的附加硬件的开销是相当大的,所以混合冗余的成本很高,仅在对可靠性要求极高的场合中采用。
2.信息冗余
信息冗余是在实现正常功能所需要的信息外,再添加一些信息,以保证运行结果正确性的方法。例如,检错码和纠错码就是信息冗余的例子。这种冗余信息的添加方法是按照一组预定的规则进行的。符合添加规则而形成的带有冗余信息的字称为码字,而那些虽带有冗余信息但不符合添加规则的字则称为非码字。当系统出现故障时,可能会将码字变成非码字,于是在译码过程中会将引起非码字的故障检测出来,这就是检错码的基本思想。纠错码则不仅可以将错误检测出来,还能将由故障引起的非码字纠正成正确的码字。
由此可见,信息冗余的主要任务在于研究出一套理想的编码和译码技术来提高信息冗余的效率。编码技术中应用最广泛的是奇偶校验码、海明校验码和循环冗余校验码。
3.时间冗余
时间冗余是以时间(即降低系统运行速度)为代价以减少硬件冗余和信息冗余的开销来达到提高可靠性的目的。在某些实际应用中,硬件冗余和信息冗余的成本、体积、功耗、重量等开销可能过高,而时间并不是太重要的因素时,可以使用时间冗余。时间冗余的基本概念是重复多次进行相同的计算,或称为重复执行(复执),以达到故障检测的目的。
实现时间冗余的方法很多,但是其基本思想不外乎是对相同的计算任务重复执行多次,然后将每次的运行结果存放起来再进行比较。若每次的结果相同,则认为无故障;若存在不同的结果,则说明检测到了故障。不过,这种方法往往只能检测到瞬时性故障而不宜检测永久性的故障。
4.冗余附加
冗余附加技术包括:冗余备份程序的存储及调用,实现错误检测和错误恢复的程序,实现容错软件所需的固化程序。
第 28 题
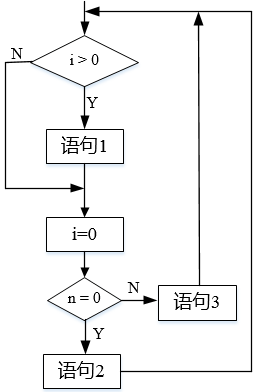
采用McCabe度量法计算下列程序图的环路复杂性为( )。
- (A) 2
- (B) 3
- (C) 4
- (D) 5
答案与解析
- 试题难度:一般
- 知识点:软件工程>McCabe复杂度计算
- 试题答案:[['C']]
- 试题解析:McCabe度量法是通过定义环路复杂度,建立程序复杂性的度量,它基于一个程序模块的程序图中环路的个数。计算有向图 G 的环路复杂性的公式为:VG=m-n+2,其中 VG是有向图 G 中的环路个数,m是 G 中的有向弧数,n 是 G 中的节点数。
图中m为8,n为6,则m-n+2=4。
第 29 题
以下关于文档的叙述中,不正确的是( )。
- (A) 文档仅仅描述和规定了软件的使用范围及相关的操作命令
- (B) 文档也是软件产品的一部分,没有文档的软件就不能称之为软件
- (C) 软件文档的编制在软件开发工作中占有突出的地位和相当大的工作量
- (D) 高质量文档对于发挥软件产品的效益有着重要的意义
答案与解析
- 试题难度:容易
- 知识点:软件工程>软件文档
- 试题答案:[[A]]
- 试题解析:软件文档的作用
在软件生产过程中,总是产生和使用大量的信息。软件文档在产品的开发过程中起着重要的作用。 提高软件开发过程的能见度。把开发过程中发生的事件以某种可阅读的形式记录在文档中。
管理人员可把这些记载下来的材料作为检查软件开发进度和开发质量的依据,实现对软件开发的工程管理,提高开发效率。软件文档的编制,使得开发人员对各个阶段的工作都进行周密思考、全盘权衡、减少返工。并且可在开发早期发现错误和不一致性,便于及时加以纠正。开发文档可以作为开发人员在一定阶段的工作成果和结束标志, 记录开发过程中有关信息,便于协调以后的软件开发、使用和维护。
提供对软件的运行、维护和培训的有关信息,便于管理人员、开发人员、操作人员、用户之间的协作、交流和了解。使软件开发活动更科学、更有成效。
便于潜在用户了解软件的功能、性能等各项指标,为他们选购符合自己需要的软件提供依据。
从某种意义上来说,文档是软件开发规范的体现和指南。 按规范要求生成一整套文档的过程,就是按照软件开发规范完成一个软件开发的过程。
所以,在使用工程化的原理和方法来指导软件的开发和维护时,应当充分注意软件文档的编制和管理。
第 30 题
某搜索引擎在使用过程中,若要增加接受语音输入的功能,使得用户可以通过语音输入来进行搜索,此时应对系统进行( )维护。
- (A) 正确性
- (B) 适应性
- (C) 完善性
- (D) 预防性
答案与解析
- 试题难度:一般
- 知识点:软件工程>软件维护类型
- 试题答案:[['C']]
- 试题解析:在系统运行过程中,软件需要维护的原因是多样的,根据维护的原因不同,可以将软件维护分为以下四种:
(1)改正性维护。为了识别和纠正软件错误、改正软件性能上的缺陷、排除实施中的误使用,应当进行的诊断和改正错误的过程就称为改正性维护。
(2)适应性维护。在使用过程中,外部环境(新的硬、软件配置)、数据环境(数据库、数据格式、数据输入/输出方式、数据存储介质)可能发生变化。为使软件适应这种变化,而去修改软件的过程就称为适应性维护。
(3)完善性维护。在软件的使用过程中,用户往往会对软件提出新的功能与性能要求。为了满足这些要求,需要修改或再开发软件,以扩充软件功能、增强软件性能、改进加工效率、提高软件的可维护性。这种情况下进行的维护活动称为完善性维护。
(4)预防性维护。这是指预先提高软件的可维护性、可靠性等,为以后进一步改进软件打下良好基础。通常,预防性维护可定义为“把今天的方法学用于昨天的系统以满足明天的需要”。也就是说,采用先进的软件工程方法对需要维护的软件或软件中的某一部分(重新)进行设计、编码和测试。《软件设计师教程(第5版)》定义:
(1)改正性维护(正确性维护)。正确性维护是指改正在系统开发阶段已发生而系统测试阶段尚未发现的错误。
(2)适应性维护。适应性维护是指应用软件适应信息技术变化和管理需求变化而进行的修改。
(3)完善性维护。这是为扩充功能和改善性能而进行的修改,主要是指对已有的软件系统增加一些在系统分析和设计阶段中没有规定的功能与性能特征。
(4)预防性维护。为了改进应用软件的可靠性和可维护性,为了适应未来的软/硬件环境的变化,应主动增加预防性的新功能,以使应用系统适应各类变化而不被淘汰。
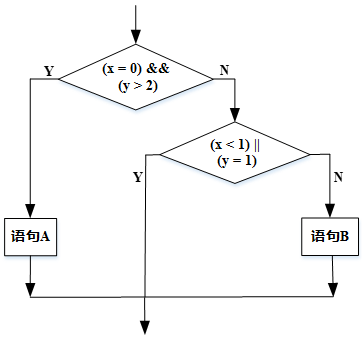
第 31 题
采用白盒测试方法对下图进行测试,设计了4个测试用例:①(x=0,y=3), ②(x=1,y=2), ③(x=-1,y=2),④(x=3,y=1)。至少需要测试用例①②才能完成( )覆盖,至少需要测试用例①②③或①②④才能完成( )覆盖。
- (A) 语句
- (B) 条件
- (C) 判定\条件
- (D) 路径
- (A) 语句
- (B) 条件
- (C) 判定\条件
- (D) 路径
答案与解析
- 试题难度:一般
- 知识点:软件工程>白盒测试用例
- 试题答案:[['A'],['D']]
- 试题解析:语句覆盖(Statement Coverage) 又称行覆盖(Line Coverage),段覆盖(Segment Coverage),基本块覆盖(Basic Block Coverage),这是最常用也是最常见的一种覆盖方式,就是度量被测代码中每个可执行语句是否被执行到了,只管覆盖代码中的执行语句,却不考虑各种分支的组合等等。
路径覆盖的含义是,选取足够多的测试数据,使程序的每条可能路径都至少执行一次(如果程序图中有环,则要求每个环至少经过一次)。
第 32 题
( )是一个类与它的一个或多个细化类之间的关系,即一般与特殊的关系。
- (A) 泛化
- (B) 关联
- (C) 聚集
- (D) 组合
答案与解析
- 试题难度:一般
- 知识点:面向对象技术>UML图中的关系
- 试题答案:[['A']]
- 试题解析:泛化(generalization)关系是一个类(称为子类、子接口)继承另外的一个类(称为父类、父接口)的功能,并可以增加它自己的新功能的能力,继承是类与类或者接口与接口之间最常见的关系。
关联(association)关系:表示类与类之间的联接,它使一个类知道另一个类的属性和方法。
聚合(aggregation)关系: 关联关系的一种特例,是强的关联关系. 聚合是整体和个体之间的关系,即has-a的关系,此时整体与部分之间是可分离的,他们可以具有各自的生命周期,部分可以属于多个整体对象,也可以为多个整体对象共享。
组合(合成)关系(composition): 也是关联关系的一种特例,他体现的是一种contains-a的关系,这种关系比聚合更强,也称为强聚合;他同样体现整体与部分间的关系,但此时整体与部分是不可分的,整体的生命周期结束也就意味着部分的生命周期结束。
第 33 题
某些程序设计语言中,在运行过程中当一个对象发送消息请求服务时,根据接收对象的具体情况将请求的操作与实现的方法进行连接,称为( )。
- (A) 静态绑定
- (B) 通用绑定
- (C) 动态绑定
- (D) 过载绑定
答案与解析
- 试题难度:容易
- 知识点:面向对象技术>面向对象的基本概念
- 试题答案:[[C]]
- 试题解析:静态绑定:绑定的是对象的静态类型,某特性(比如函数)依赖于对象的静态类型,发生在编译期。
动态绑定:绑定的是对象的动态类型,某特性(比如函数)依赖于对象的动态类型,发生在运行期。
第 34 题
在面向对象技术中,不同的对象在收到同一消息时可以产生完全不同的结果, 这一现象称为( ),它由( )机制来支持。利用类的层次关系,把具有通用功能的消息存放在高层次,而不同的实现这一功能的行为放在较低层次,在这些低层次上生成的对象能够给通用消息以不同的响应。
- (A) 绑定
- (B) 继承
- (C) 消息
- (D) 多态
- (A) 绑定
- (B) 继承
- (C) 消息
- (D) 多态
答案与解析
- 试题难度:一般
- 知识点:面向对象技术>面向对象的基本概念
- 试题答案:[['D'],['B']]
- 试题解析:本题考查面向对象多态的概念。
多态实质上是将子类的指针对象或者引用对象传递给父类指针对象后,通过这个父类指针对象调用的函数(此函数在父类中声明为虚函数,且在各个子类中重写这个函数),不是父类中定义的,而是传递进来的子类对象中重写的函数。
第 35 题
对一个复杂用例中的业务处理流程进行进一步建模的最佳工具是UML( )。
- (A) 状态图
- (B) 顺序图
- (C) 类图
- (D) 活动图
答案与解析
- 试题难度:一般
- 知识点:面向对象技术>UML图的定义
- 试题答案:[[D]]
- 试题解析:
(1)类图(class diagram)。类图描述一组类、接口、协作和它们之间的关系。在OO系统的建模中,最常见的图就是类图。类图给出了系统的静态设计视图,活动类的类图给出了系统的静态进程视图。
(2)对象图(object diagram)。对象图描述一组对象及它们之间的关系。对象图描述了在类图中所建立的事物实例的静态快照。和类图一样,这些图给出系统的静态设计视图或静态进程视图,但它们是从真实案例或原型案例的角度建立的。
(3)构件图(component diagram)。构件图描述一个封装的类和它的接口、端口,以及由内嵌的构件和连接件构成的内部结构。构件图用于表示系统的静态设计实现视图。对于由小的部件构建大的系统来说,构件图是很重要的。构件图是类图的变体。
(4)组合结构图(composite structure diagram)。组合结构图描述结构化类(例如,构件或类)的内部结构,包括结构化类与系统其余部分的交互点。组合结构图用于画出结构化类的内部内容。
(5)用例图(use case diagram)。用例图描述一组用例、参与者及它们之间的关系。用例图给出系统的静态用例视图。这些图在对系统的行为进行组织和建模时是非常重要的。
(6)顺序图(sequence diagram,序列图)。顺序图是一种交互图(interaction diagram),交互图展现了一种交互,它由一组对象或参与者以及它们之间可能发送的消息构成。交互图专注于系统的动态视图。顺序图是强调消息的时间次序的交互图。
(7)通信图(communication diagram)。通信图也是一种交互图,它强调收发消息的对象或参与者的结构组织。顺序图和通信图表达了类似的基本概念,但它们所强调的概念不同,顺序图强调的是时序,通信图强调的是对象之间的组织结构(关系)。在UML 1.X版本中,通信图称为协作图(collaboration diagram)。
(8)定时图(timing diagram,计时图)。定时图也是一种交互图,它强调消息跨越不同对象或参与者的实际时间,而不仅仅只是关心消息的相对顺序。
(9)状态图(state diagram)。状态图描述一个状态机,它由状态、转移、事件和活动组成。状态图给出了对象的动态视图。它对于接口、类或协作的行为建模尤为重要,而且它强调事件导致的对象行为,这非常有助于对反应式系统建模。
(10)活动图(activity diagram)。活动图将进程或其他计算结构展示为计算内部一步步的控制流和数据流。活动图专注于系统的动态视图。它对系统的功能建模和业务流程建模特别重要,并强调对象间的控制流程。
(11)部署图(deployment diagram)。部署图描述对运行时的处理节点及在其中生存的构件的配置。部署图给出了架构的静态部署视图,通常一个节点包含一个或多个部署图。
(12)制品图(artifact diagram)。制品图描述计算机中一个系统的物理结构。制品包括文件、数据库和类似的物理比特集合。制品图通常与部署图一起使用。制品也给出了它们实现的类和构件。
(13)包图(package diagram)。包图描述由模型本身分解而成的组织单元,以及它们之间的依赖关系。
(14)交互概览图(interaction overview diagram)。交互概览图是活动图和顺序图的混合物。
第 36 题
如下所示的序列图中( )表示返回消息,Accunt类必须实现的方法有( )。
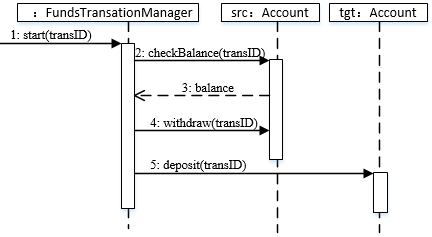
- (A) tansID
- (B) balance
- (C) withdraw
- (D) deposit
- (A) start()
- (B) checkBalance()和withdraw()
- (C) deposit()
- (D) checkBalance()、withdraw()和deposit()
答案与解析
- 试题难度:一般
- 知识点:面向对象技术>UML图的图示
- 试题答案:[[B],[D]]
- 试题解析:UML序列图中,返回消息使用虚线带箭头表示,同步消息(调用消息)使用实线带实心箭头表示,异步消息使用实线带箭头表示。
由图示,Accunt应该实现checkBalance()、withdraw()和deposit()方法。
第 37 题
下图所示为( )设计模式,适用于( )。
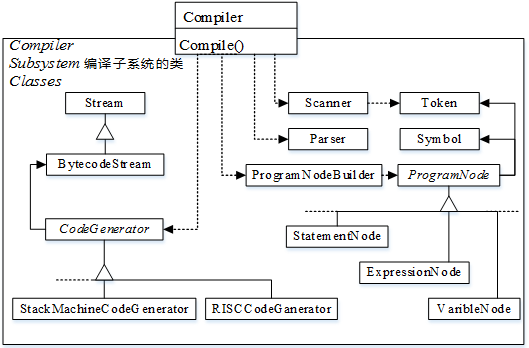
- (A) 适配器(Adapter)
- (B) 责任链(Chain of Responsibility)
- (C) 外观(Facade)
- (D) 桥接(Bridge)
- (A) 有多个对象可以处理一个请求,在运行时刻自动确定由哪个对象处理
- (B) 想使用一个已经存在的类,而其接口不符合要求
- (C) 类的抽象和其实现之间不希望有一个固定的绑定关系
- (D) 需要为一个复杂子系统提供一个简单接口
答案与解析
- 试题难度:一般
- 知识点:面向对象技术>设计模式的图
- 试题答案:[['C'],['D']]
- 试题解析:外观模式是一种使用频率非常高的结构型设计模式,它通过引入一个外观角色来简化客户端与子系统之间的交互,为复杂的子系统调用提供一个统一的入口,降低子系统与客户端的耦合度,且客户端调用非常方便。
适配器模式(Adapter):将一个类的接口转换成用户希望得到的另一种接口。它使原本不相容的接口得以协同工作。
责任链模式(Chain of Responsibility):通过给多个对象处理请求的机会,减少请求的发送者与接收者之间的耦合。将接收对象链接起来,在链中传递请求,直到有一个对象处理这个请求。
桥接模式(Bridge):将类的抽象部分和它的实现部分分离开来,使它们可以独立地变化。
第 38 题
下列设计模式中,( )模式既是类结构型模式,又是对象结构型模式。此模式与( )模式类似的特征是,都给另一个对象提供了一定程度上的间接性,都涉及到从自身以外的一个接口向这个对象转发请求。
- (A) 桥接(Bridge)
- (B) 适配器(Adapter)
- (C) 组成(Composite)
- (D) 装饰器(Decorator)
- (A) 桥接(Bridge)
- (B) 适配器(Adapter)
- (C) 组成(Composite)
- (D) 装饰器 (Decorator)
答案与解析
- 试题难度:一般
- 知识点:面向对象技术>设计模式的应用场景
- 试题答案:[['B'],['A']]
- 试题解析:适配器(adapter)模式。适配器模式将一个接口转换成客户希望的另一个接口,从而使接口不兼容的那些类可以一起工作。适配器模式既可以作为类结构型模式,也可以作为对象结构型模式。在类适配器模式中,通过使用一个具体类将适配者适配到目标接口中;在对象适配器模式中,一个适配器可以将多个不同的适配者适配到同一个目标。
桥接(bridge)模式。桥接模式将抽象部分与它的实现部分分离,使它们都可以独立地变化。它是一种对象结构型模式,又称为柄体(handle and body)模式或接口(interface)模式。桥接模式类似于多重继承方案,但是多重继承方案往往违背了类的单一职责原则,其复用性比较差,桥接模式是比多重继承方案更好的解决方法。
组合(composite)模式。组合模式又称为整体-部分(part-whole)模式,属于对象的结构模式。在组合模式中,通过组合多个对象形成树形结构以表示整体-部分的结构层次。组合模式对单个对象(即叶子对象)和组合对象(即容器对象)的使用具有一致性。
装饰(decorator)模式。装饰模式是一种对象结构型模式,可动态地给一个对象增加一些额外的职责,就增加对象功能来说,装饰模式比生成子类实现更为灵活。通过装饰模式,可以在不影响其他对象的情况下,以动态、透明的方式给单个对象添加职责;当需要动态地给一个对象增加功能,这些功能可以再动态地被撤销时可使用装饰模式;当不能采用生成子类的方法进行扩充时也可使用装饰模式。
第 39 题
以下关于实现高级程序设计语言的编译和解释方式的叙述中,正确的是( )。
- (A) 在编译方式下产生源程序的目标程序,在解释方式下不产生
- (B) 在解释方式下产生源程序的目标程序,在编译方式下不产生
- (C) 编译和解释方式都产生源程序的目标程序,差别是优化效率不同
- (D) 编译和解释方式都不产生源程序的目标程序,差别在是否优化
答案与解析
- 试题难度:一般
- 知识点:程序设计语言基础>编译与解释
- 试题答案:[['A']]
- 试题解析:编译程序的功能就是把高级语言书写的源程序翻译成与之等价的目标程序(汇编语言或机器语言)。
解释程序是另一种语言处理程序,在词法、语法和语义分析方面与编译程序的工作原理基本相同,但在运行时直接执行源程序或源程序的内部形式,即解释程序不产生源程序的目标程序,这点是它与编译程序的主要区别。
第 40 题
大多数程序设计语言的语法规则用( )描述即可。
- (A) 正规文法
- (B) 上下文无关文法
- (C) 上下文有关文法
- (D) 短语结构文法
答案与解析
- 试题难度:一般
- 知识点:程序设计语言基础>文法
- 试题答案:[[B]]
- 试题解析:上下文无关文法重要的原因在于它们拥有足够强的表达力来表示大多数程序设计语言的语法;实际上,几乎所有程序设计语言都是通过上下文无关文法来定义的。另一方面,上下文无关文法又足够简单,使得我们可以构造有效的分析算法来检验一个给定字串是否是由某个上下文无关文法产生的。
第 41 题
在C/C++程序中,整型变量a的值为0且应用在表达式“c=b/a”中,则最可能发生的情形是( )。
- (A) 编译时报告有语法错误
- (B) 编译时报告有逻辑错误
- (C) 运行时报告有语法错误
- (D) 运行时产生异常
答案与解析
- 试题难度:一般
- 知识点:程序设计语言基础>错误管理
- 试题答案:[['D']]
- 试题解析:检查语法错误是在编译时,表达式“c=b/a”符合语法逻辑,编译时不会报语法错误;由于编译时a的值无法确定,需要到运行时,实际传入值时才能确定,因此在运行时,若分母为0,将产生异常。
第 42 题
为了保证数据库中数据的安全可靠和正确有效,系统在进行事务处理时,对数据的插入、删除或修改的全部有关内容先写入( );当系统正常运行时,按一定的时间间隔,把数据库缓冲区内容写入( );当发生故障时,根据现场数据内容及相关文件来恢复系统的状态。
- (A) 索引文件
- (B) 数据文件
- (C) 日志文件
- (D) 数据字典
- (A) 索引文件
- (B) 数据文件
- (C) 日志文件
- (D) 数据字典
答案与解析
- 试题难度:一般
- 知识点:数据库系统>其它
- 试题答案:[[C],[B]]
- 试题解析:数据文件包含数据和对象,例如表、索引、存储过程和视图。 日志文件包含恢复数据库中的所有事务所需的信息。
第 43 题
“当多个事务并发执行时,任一事务的更新操作直到其成功提交的整个过程,对其他事务都是不可见的”,这一性质通常被称为事务的( )。
- (A) 原子性
- (B) 一致性
- (C) 隔离性
- (D) 持久性
答案与解析
- 试题难度:容易
- 知识点:数据库系统>事务的特性
- 试题答案:[[C]]
- 试题解析:隔离性:事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须是透明的。
第 44 题
假定某企业2014年5月的员工工资如下表所示:
2014年5月员工工资表
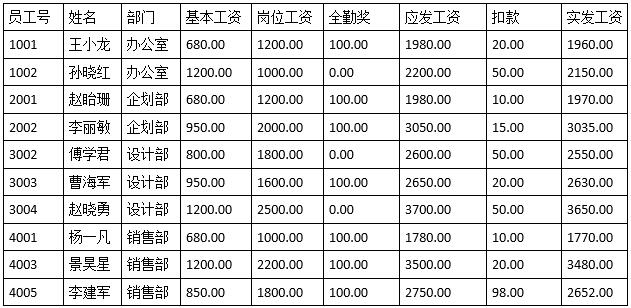
查询人数大于2的部门和部门员工应发工资的平均工资的SQL语句如下:
SELECT( )
FROM 工资表
( )
( )
查询各部门人数大于2和部门员工的平均工资的SQL语句如下:
SELECT部门,AVG(应发工资)AS平均工资
FROM 工资表
GROUP BY部门
HAVING COUNT(姓名)>2;
SQL提供可为关系和属性重新命名的机制,这是通过使用具有“Old-name as new-name”形式的as子句来实现的。As子句即可出现在select子句,也可出现在from子句中。
试题(55)的正确的答案为选项D。因为本题是按部门进行分组。ORDER BY子句的含义是对其后跟着的属性进行排序,故选项A和B均是错误的;GROUP BY子句就是对元组进行分组,保留字GROUP BY后面跟着一个分组属性列表。根据题意,要查询部门员工的平均工资,选项C显然是错误的。
试题(56)的正确的答案为选项C。因为WHERE语句是对表进行条件限定,所以选项A和B均是错误的。在GROUP BY子句后面跟一个HAVING子句可以对元组在分组前按照某种方式加上限制。COUNT(*)是某个关系中所有元组数目之和,但COUNT(A)却是A属性非空的元组个数之和。COUNT(DISTINCT(部门))的含义是对部门属性值相同的只统计1次。HAVING COUNT(DISTINCT(部门))语句分类统计的结果均为1,故选项D是错误的;HAVING COUNT(姓名)语句是分类统计各部门员工,故正确的答案为选项C。
### 第 45 题
若对线性表的最常用操作是访问任意指定序号的元素,并在表尾加入和删除元素,则适宜采用( )存储。
>- (A) 顺序表 >- (B) 单链表 >- (C) 双向链表 >- (D) 哈希表 **答案与解析** - 试题难度:一般 - 知识点:数据结构与算法基础>顺序表与链表 - 试题答案:[[A]] - 试题解析:第 46 题
二叉树如右图所示,若进行顺序存储(即用一维数组元素存储该二叉树中的结点且通过下标反映结点间的关系,例如,对于下标为i的结点,其左孩子的下标为2i、右孩子的下标为2i+1),则该数组的大小至少为( );若采用三叉链表存储该二叉树(各个结点包括结点的数据、父结点指针、左孩子指针、右孩子指针),则该链表的所有结点中空指针的数目为( )。
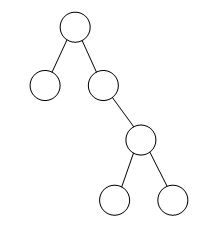
- (A) 6
- (B) 10
- (C) 12
- (D) 15
- (A) 6
- (B) 8
- (C) 12
- (D) 14
答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>树与二叉树的特性
- 试题答案:[['D'],['B']]
- 试题解析:用一维数组元素存储该二叉树中的结点且通过下标反映结点间的关系,实际上存储的是这棵二叉树对应的完全二叉树,因此需要的存储空间为2n-1=15(n为二叉树层数)。如下图所示:釆用三叉链表存储该二叉树(各个结 点包括结点的数据、父结点指针、左孩子指针、右孩子指针);如下图所示:</div>

 空指针数量为8。
空指针数量为8。
第 47 题
某双端队列如下所示,要求元素进出队列必须在同一端口,即从A端进入的元素必须从A端出、从B端进入的元素必须从B端出,则对于4个元素的序列e1、e2、e3、e4,若要求从前2个元素(e1、e2)从A端口按次序全部进入队列,后两个元素(e3、e4)从B端口按次序全部进入队列,则可能得到的出队序列是( )。

- (A) e1、e2、e3、e4
- (B) e2、e3、e4、e1
- (C) e3、e4、e1、e2
- (D) e4、e3、e2、e1
答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>队列与栈
- 试题答案:[['D']]
- 试题解析:e1、e2从A端口进入,e3、e4从B端口进入,如下图所示:

根据题意:从A端进入的元素必须从A端出、从B端进入的元素必须从B端出;则出队顺序中e2在e1前面,e4在e3前面。
只有答案D满足。
第 48 题
实现二分查找(折半查找)时,要求查找表( )。
- (A) 顺序存储,关键码无序排列
- (B) 顺序存储,关键码有序排列
- (C) 双向链表存储,关键码无序排列
- (D) 双向链表存储,关键码有序排列
答案与解析
- 试题难度:容易
- 知识点:数据结构与算法基础>二分查找
- 试题答案:[[B]]
- 试题解析:
</div>二分查找又称折半查找,优点是比较次数少,查找速度快,平均性能好;其缺点是要求待查表为有序表,且插入删除困难。因此,折半查找方法适用于不经常变动而查找频繁的有序列表。<br /> 算法要求:①必须采用顺序存储结构 ②必须按关键字大小有序排列。</p>
第 49 题
在某个算法时间复杂度递归式T(n)=T(n-1)+n,其中n为问题的规模,则该算法的渐进时间复杂度为( ),若问题的规模增加了16倍,则运行时间增加( )倍。
- (A) Θ(n)
- (B) Θ(nlgn)
- (C) Θ(n2)
- (D) Θ(n2lgn)
- (A) 16
- (B) 64
- (C) 256
- (D) 1024
答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>时间复杂度与空间复杂度
- 试题答案:[[C],[C]]
- 试题解析:由于递归式为:T(n)=T(n-1)+n。我们可以把一个规模为n的时间复杂度算出来。分析过程为:T(n)=T(n-1)+n;T(n-1)=T(n-2)+n-1;T(n-2)=T(n-3)+n-2;....T(n)=1+2+..+n-1+n。这是一个典型的等差数列。用数列求和公式有:((1+n)*n)/2。这样就求得时间复杂度为:Θ(n2)。后面一问则有:当问题规模为n时,时间复杂度Θ(n2)。当x=16n时,时间复杂度Θ(x2)=Θ((16n)2)=Θ(256n2)。
第 50 题
Prim算法和Kruscal算法都是无向连通网的最小生成树的算法,Prim算法从一个顶点开始,每次从剩余的顶点加入一个顶点,该顶点与当前生成树中的顶占的连边权重 最小,直到得到最小生成树开始,Kruscal算法从权重最小的边开始,每次从不在当前的生成树顶点之间的边中选择权重最小的边加入,直到得到一颗最小生成树,这两个算法都采用了( )设计策略,且( )。
- (A) 分治
- (B) 贪心
- (C) 动态规划
- (D) 回溯
- (A) 若网较稠密,则Prim算法更好
- (B) 两个算法得到的最小生成树是一样的
- (C) Prim算法比Kruscal算法效率更高
- (D) Kruscal算法比Prim算法效率更高
答案与解析
- 试题难度:一般
- 知识点:数据结构与算法基础>贪心法
- 试题答案:[['B'],['A']]
- 试题解析:本题考查算法设计与分析的基础知识。
Prim算法从扩展顶点开始,每次总是”贪心的“选择与当前顶点集合中距离最短的顶点,而Kruscal 算法从扩展边开始,每次总是”贪心的“选择剩余的边中最小权重的边,因此两个算法都是基于贪心策略进行的。
Prim 算法的时间复杂度为O(n2),其中n 为图的顶点数,该算法的计算时间与图中的边数无关,因此该算法适合于求边稠密的图的最小生成树;Kruscal 算法的时间复杂度为O(mlgm) ,其中m为图的边数,该算法的计算时间与图中的顶点数无关,因此该算法适合于求边稀疏的图的最小生成树。当图稠密时,用 Prim 算法效率更高。但若事先没有关于图的拓扑特征信息时,无法判断两者的优劣。由于一个图的最小生成树可能有多棵, 因此不能保证用这两种算法得到的是同一棵最小生成树。
第 51 题
IP地址块155.32.80.192/26包含了( )个主机地址,以下IP地址中,不属于这个网络的地址是( )。
- (A) 15
- (B) 32
- (C) 62
- (D) 64
- (A) 155.32.80.202
- (B) 155.32.80.195
- (C) 155.32.80.253
- (D) 155.32.80.191
答案与解析
- 试题难度:一般
- 知识点:计算机网络>子网划分与路由汇聚
- 试题答案:[['C'],['D']]
- 试题解析:变长子网的可用主机数计算公式为2n-2(n为表示主机的位数)/26即主机位为32-26=6,所以可用主机地址为64-2=62。用IP地址155.32.80.192与子网掩码进行逻辑与运算得出该IP地址所在的网络号为:155.32.80.192;所在网段的广播地址为:155.32.80.255;所以与该IP地址不在同一网段的是选项D。
第 52 题
校园网链接运营商的IP地址为202.117.113.3/30,本地网关的地址为192.168.1.254/24,如果本地计算机采用动态地址分配,在下图中应如何配置?( )。

- (A) 选取“自动获得IP地址”
- (B) 配置本地计算机IP地址为192.168.1.X
- (C) 配置本地计算机IP地址为202.115.113.X
- (D) 在网络169.254.X.X中选取一个不冲突的IP地址
答案与解析
- 试题难度:一般
- 知识点:计算机网络>协议应用提升
- 试题答案:[['A']]
- 试题解析:当选择自动获得IP地址时,表示计算机采用动态获取IP地址,计算机从DHCP服务器上获取IP地址以及相关的项目。
第 53 题
某用户在使用校园网中的一台计算机访问某网站时,发现使用域名不能访问该 网站,但是使用该网站的IP地址可以访问该网站,造成该故障产生的原因有很多,其中不包括( )。
- (A) 该计算机设置的本地DNS服务器工作不正常
- (B) 该计算机的DNS服务器设置错误
- (C) 该计算机与DNS服务器不在同一子网
- (D) 本地DNS服务器网络连接中断
答案与解析
- 试题难度:一般
- 知识点:计算机网络>网络故障诊断及常用命令
- 试题答案:[['C']]
- 试题解析:本题主要考查网络故障判断的相关知识。
如果本地的DNS服务器工作不正常或者本地DNS服务器网络连接中断都有可能导致该计算机的DNS无法解析域名,而如果直接将该计算机的DNS服务器设置错误也会导致DNS无法解析域名,从而出现使用域名不能访问该网站,但是使用该网站的IP地址可以访问该网站。但是该计算机与DNS服务器不在同一子网不会导致DNS无法解析域名的现象发生,通常情况下大型网络里面的上网计算机与DNS服务器本身就不在一个子网,只要路由可达DNS都可以正常工作。
第 54 题
中国自主研发的3G通信标准是( )。
- (A) CDMA2000
- (B) TD-SCDMA
- (C) WCDMA
- (D) WiMAX
答案与解析
- 试题难度:一般
- 知识点:计算机网络>网络接入技术
- 试题答案:[[B]]
- 试题解析:W-CDMA:英文名称是Wideband Code Division Multiple Access,中文译名为宽带码分多址,它可支持384kbps到2Mbps不等的数据传输速率,支持者主要以GSM系统为主的欧洲厂商。CDMA2000:亦称CDMA Multi-Carrier,由美国高通北美公司为主导提出,摩托罗拉、Lucent和后来加入的韩国三星都有参与,韩国现在成为该标准的主导者。TD-SCDMA:该标准是由中国独自制定的3G标准,由于中国的庞大的市场,该标准受到各大主要电信设备厂商的重视,全球一半以上的设备厂商都宣布可以支持TD-SCDMA标准。
第 55 题
Cloud computing is a phrase used to describe a variety of computing concepts that involve a large number of computers(1)through a real-time communication network such as the Internet. In science, cloud computing is a(2)for distributed computing over a network, and means the(3)to run a program or application on many connected computers at the same time.
The architecture of a cloud is developed at three layers: infrastructure, platform, and application, The infrastructure layer is built with virtualized computer, storage, and network resources. The platform layer is for general-purpose and repeated usage of the collection of software resources. The application layer is formed with a collection of all needed software modules for SaaS applications. The infrastructure layer serves as the(4)for building the platform layer of the cloud. In turn, the platform layer is a foundation for implementing the(5)layer for SaaS applications.
- (A) connected
- (B) imlemented
- (C) optimized
- (D) Virtualized
- (A) replacement
- (B) switch
- (C) substitute
- (D) synonym(同义词)
- (A) ability
- (B) applroach
- (C) function
- (D) method
- (A) network
- (B) foundation
- (C) software
- (D) hardware
- (A) resoruce
- (B) service
- (C) application
- (D) software
答案与解析
- 试题难度:一般
- 知识点:专业英语>专业英语
- 试题答案:[['A'],['D'],['A'],['B'],['C']]
- 试题解析:云计算是用来描述各种计算概念的短语,包括大量计算机通过网络相互连接以实现分布计算,意思是同时在很多互联的计算机上运行程序或应用的能力。 云的架构分为基础设施层、平台层和应用层三层。基础设施层由虚拟计算、存储和网络资源构成。平台层用于一组软件资源重复使用的通用目的。应用层由一组所需的软件模块构成即软件即服务(SaaS)。基础设施层作为构建平台层的基础。相反,平台层是应用层的基础,为SaaS应用实现应用层。