201011软设下午真题
第 1 题
阅读以下说明和图,回答问题1至问题3,将解答填入答题纸的对应栏内。
【说明】
某时装邮购提供商拟开发订单处理系统,用于处理客户通过电话、传真、邮件或Web站点所下订单。其主要功能如下:
(1)增加客户记录。将新客户信息添加到客户文件,并分配一个客户号以备后续使用。
(2)查询商品信息。接收客户提交商品信息请求,从商品文件中查询商品的价格和可订购数量等商品信息,返回给客户。
(3)增加订单记录。根据客户的订购请求及该客户记录的相关信息,产生订单并添加到订单文件中。
(4)产生配货单。根据订单记录产生配货单,并将配货单发送给仓库进行备货;备好货后,发送备货就绪通知。如果现货不足,则需向供应商订货。
(5)准备发货单。从订单文件中获取订单记录,从客户文件中获取客户记录,并产生发货单。
(6)发货。当收到仓库发送的备货就绪通知后,根据发货单给客户发货;产生装运单并发送给客户。
(7)创建客户账单。根据订单文件中的订单记录和客户文件中的客户记录,产生并发送客户账单,同时更新商品文件中的商品数量和订单文件中的订单状态。
(8)产生应收账户。根据客户记录和订单文件中的订单信息,产生并发送给财务部门应收账户报表。
现采用结构化方法对订单处理系统进行分析与设计,获得如图1-1所示的顶层数据流图和图1-2所示0层数据流图。
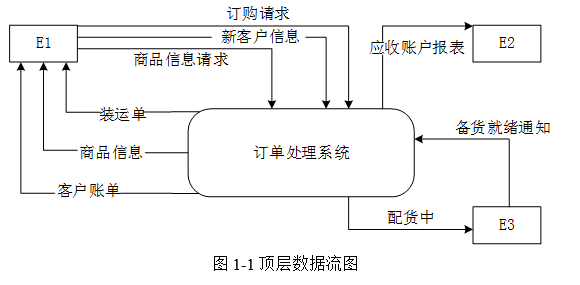
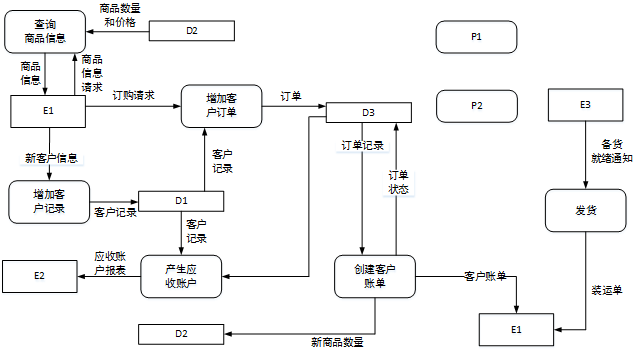
图1-2 0层数据流图
【问题1】(3分)
使用说明中的词语,给出图1-1中的实体E1~E3的名称。
【问题2】(3分)
使用说明中的词语,给出图1-2中的数据存储D1~D3的名称。
【问题3】(9分)
(1)给出图1-2中处理(加工)P1和P2的名称及其相应的输入、输出流。
(2)除加工P1和P2的输入输出流外,图1-2还缺失了1条数据流,请给出其起点和终点。
注:名称使用说明中的词汇,起点和终点均使用图1-2中的符号或词汇。
答案与解析
- 试题难度:较难
- 知识点:数据流图>数据流图
- 试题答案:【问题1】
E1:客户 E2:财务部门 E3:仓库
【问题2】
D1: 客户文件 D2: 商品文件 D3:订单文件
【问题3】
(1)加工名称 数据流
P1:产生配货单 P2:准备发货单
数据流名称:订单记录 起点:D3或订单文件 终点:P1或产生配货单
数据流名称:配货单 起点:P1或产生配货单 终点:E3或仓库
数据流名称:订单记录 起点:D3或订单文件 终点:P2或准备发货单
数据流名称:客户记录 起点:D1或客户文件 终点:P2或准备发货单
数据流名称:发货单 起点:P2或准备发货单 终点:发货
注:各行次序无关,P1和P2可互换,但必须整体互换
(2)缺少的数据流
起点:D1或客户文件 终点:创建客户账单 - 试题解析:
本题考查数据流图(DFD)的应用,是比较传统的题目,要求考生细心分析题目中所描述的内容。DFD是一种便于用户理解、分析系统数据流程的图形工具。是系统逻辑模型的重要组成部分。
【问题1】
本问题要求我们给出图1-1中的实体E1~E3的名称。这个需要我们从题目中的描述和该图来获得。题目中有信息描述:当收到仓库发送的备货就绪通知后,根据发货单给客户发货;产生装运单并发送给客户,从这条语句中我们就可以看出,应该有实体客户和仓库;另外有描述:根据客户记录和订单文件中的订单信息,产生并发送给财务部门应收账户报表。从这里我们可以找到应该还有实体财务部门。再结合图1-1中数据流和实体的对应关系可知,E1为客户,E2为财务部门,E3为仓库。
【问题2】
本问题考查数据存储的确定。说明中描述:将新客户信息添加到客户文件;从商品文件中查询商品的价格和可订购数量等商品信息,返回给客户;从订单文件中获取订单记录。我们可知系统中应存在客户文件、商品文件和订单文件。再结合图1-2,由于D1的输入输出数据流都是客户记录,可知D1应该为客户文件;D2的输入数据流是商品数量,而输出数据流有商品数量和价格,可知D2应该为商品文件;同样的道理可以知道D3应该为订单文件。
【问题3】
本问题的第一小问,要我们给出图1-2中处理P1和P2的名称及相应的数据流。在题目的描述中给出了8个处理,但在图中只有6个已经给出,那么处理P1和P2就应该是剩下的两个处理,即应该为产生配货单和准备发货单。由于在图中没有给出任何关于这两个处理的数据流,那么P1和P2是可以互换的。这里我们假设P1为产生配货单,那么根据产生配货单处理的描述(根据订单记录产生配货单,并将配货单发送给仓库进行备货)我们可以知道,它的输入数据流是从订单文件流入的订单记录,输出数据流是配货单,流向仓库。
而根据准备发货单处理的描述(从订单文件中获取订单记录,从客户文件中获取客户记录,并产生发货单),我们可以知道,它的输入流有两条,分别为从订单文件流入的订单记录和客户文件流入客户记录,输出数据流为发货单,流向发货。
第二个小问题是要我们查找缺失的数据流,做这类题应该结合上层图及题目的描述来完成,在这个题目中,主要是要根据题目的描述来完成,题目中给出了8个处理的详细描述,我们可以根据这些描述来判断,还有哪些数据流没有给出。经过仔细分析,我们可以发现创建客户账单的处理缺失一条输入数据流,它的描述说:根据订单文件中的订单记录和客户文件中的客户记录,产生并发送客户账单。很明显说明它有两条输入数据流,但在图中只给出了订单记录输入数据流,而缺失了客户记录输入数据流。
第 2 题
阅读以下说明,回答问题1至问题3,将解答填入答题纸的对应栏内。
【说明】
某公司拟开发一套小区物业收费管理系统。初步的需求分析结果如下:
(1)业主信息主要包括:业主编号,姓名,房号,房屋面积,工作单位,联系电话等。房号可唯一标识一条业主信息,且一个房号仅对应一套房屋;一个业主可以有一套或多套的房屋。
(2)部门信息主要包括:部门号,部门名称,部门负责人,部门电话等;一个员工只能属于一个部门,一个部门只有一位负责人。
(3)员工信息主要包括:员工号,姓名,出生年月,性别,住址,联系电话,所在部门号,职务和密码等。根据职务不同员工可以有不同的权限,职务为“经理”的员工具有更改(添加、删除和修改)员工表中本部门员工信息的操作权限;职务为“收费”的员工只具有收费的操作权限。
(4)收费信息包括:房号,业主编号,收费日期,收费类型,数量,收费金额,员工号等。收费类型包括物业费、卫生费、水费和电费,并按月收取,收费标准如表2-1所示。其中:物业费=房屋面积(平方米)×每平米单价,卫生费=套房数量(套)×每套房单价,水费=用水数量(吨)×每吨水单价,电费=用电数量(度)×每度电单价。
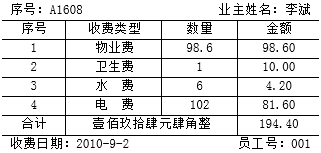
(5)收费完毕应为业主生成收费单,收费单示例如表2-2所示。
表2-1 收费标准
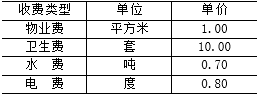
表2-2 收费单示例
【概念模型设计】
根据需求阶段收集的信息,设计的实体联系图(不完整)如图2-1所示。图2-1中收费员和经理是员工的子实体。
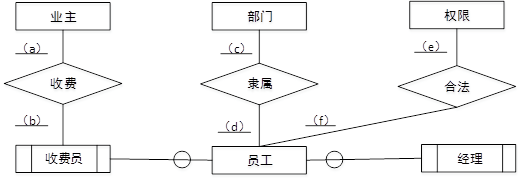
图2-1 实体联系图
【逻辑结构设计】
根据概念模型设计阶段完成的实体联系图,得出如下关系模式(不完整):
业主( (1) ,姓名,房屋面积,工作单位,联系电话)
员工( (2) ,姓名,出生年月,性别,住址,联系电话,职务,密码)
部门( (3) ,部门名称,部门电话)
权限( 职务,操作权限)
收费标准( (4) )
收费信息( (5) ,收费类型,收费金额,员工号)
【问题1】(8分)
根据图2-1,将逻辑结构设计阶段生成的关系模式中的空(1)~(5)补充完整,然后给出各关系模式的主键和外键。
【问题2】(5分)
填写图2-1中(a)~(f)处联系的类型(注:一方用1表示,多方用m或 n 或 *表示),并补充完整图2-1中的实体、联系和联系的类型。
【问题3】(2分)
业主关系属于第几范式?请说明存在的问题。
答案与解析
- 试题难度:较难
- 知识点:数据库设计>数据库设计
- 试题答案:【问题1】(8分)
(1)业主编号,房号 (0.5分)
主键:房号 外键:无 (0.5分)
(2)员工号,所在部门号 (1分)
主键:员工号 外键:所在部门号,职务 (1分)
(3)部门号,部门负责人 (1分)
主键:部门号 外键:部门负责人 (1分)
(4)收费类型,单位,单价 (0.5分)
主键:收费类型 外键:无 (0.5分)
(5)房号,业主编号,收费日期,数量 (1分)
主键:房号,业主编号,收费日期,收费类型
外键:房号,员工号,收费类型 (1分)
【问题2】(5分)
(a)n,或m,或 (0.5分)
(b)n,或m,或 (0.5分)
(c)1 (0.5分)
(d)n,或m,或 (0.5分)
(e)1 (0.5分)
(f)n,或m,或 (0.5分)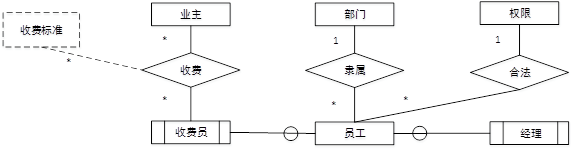 图2-1 补充完整的实体联系图(共2分,实体“收费标准”1分,三元联系“收费”及其联系类型1分)
图2-1 补充完整的实体联系图(共2分,实体“收费标准”1分,三元联系“收费”及其联系类型1分)
【问题3】(2分)
业主关系属于第2范式(1分);
存在的问题:当某业主有多套住房时,属性“业主编号,姓名,工作单位,联系电话”等信息在业主关系表中重复存储,存在数据冗余(1分)。 - 试题解析:
本题考查数据库概念结构设计、概念至逻辑结构转换及范式的判定等内容。
此类题目要求考生认真阅读题目,根据题目的需求描述,给出实体间的联系。
【问题1】
该问题要我们补充完整各关系模式中缺失的属性并给出各关系模式的主键和外键。要补充各关系模式缺失的属性应该根据题目的描述来完成。第1空是要我们补充业主缺失的属性,根据题目的描述,我们可以知道业主的信息有:业主编号,姓名,房号,房屋面积,工作单位,联系电话,因此第1空应该填(业主编号,房号);第2空是要我们补充员工缺失的属性,根据题目的描述,我们可以知道员工的信息有:员工号,姓名,出生年月,性别,住址,联系电话,所在部门号,职务和密码,因此第2空应该填(员工号,所在部门号);同样的道理我们可以知道第3空应该填(部门号,部门负责人),第5空应填(房号,业主编号,收费日期,数量)。第4空前面有所不同,它主要是通过给出的表来找出其属性的,从题目给出的收费标准表中我们可以看出收费标准应该有收费类型、单位、单价三个属性。如果题目再考难一点,可能会存在一些隐蔽点的属性,考试时也应该注意。
主键是能唯一标识一条记录的属性组,而外键是其他关系模式的主键。那么结合题目的描述我们可以知道,业主关系的主键为房号;员工关系的主键为员工号,因为它能唯一标识一个员工;部门关系的主键为部门号;收费标准关系的主键为收费类型;收费信息关系的主键为(房号,业主编号,收费日期,收费类型)。
外键是其他关系模式的主键。业主关系没有外键;员工关系的外键是所在部门号、职务,其中所在部门号是部门关系的主键,职务是权限关系的主键;部门关系的外键是部门负责人,部门负责人列出的是负责人的员工号,而员工号是员工关系的主键;收费标准没有外键;收费信息的外键有房号、员工号、收费类型,其中房号是业主关系的主键,员工号是员工关系的主键,收费类型是收费标准的主键。
【问题2】
根据题意可知,业主和收费员之间的联系类型为多对多;部门与员工之间的联系类型为1对多,因为一个部门可以有多个员工,而一个员工只能属于一个部门;员工与权限之间的联系类型为多对1,因为可以是多个员工拥有同一种权限,而一个员工只能拥有一种权限。
另外,本题中还要求我们补充完整图中实体、联系和联系的类型。从题目的描述我们可以知道,还有一个实体收费标准在图中没有给出,那么它肯定是与收费有关系的,因为收费要按照收费标准来进行,从题目的意思来看,不同的收费类型应采用不同的收费标准,因此收费标准的联系类型应该也是多端。
【问题3】
本题主要考查我们对范式定义的理解。由于在前面已经讲到,业主关系的主键是房号,是一个单属性的主键,那么就不存在部分依赖,因此是满足第2范式的,但在该关系中,房号-->业主编号,业主编号-->姓名,存在传递函数依赖,因此不满足第3范式。
当某业主有多套住房时,属性“业主编号,姓名,工作单位,联系电话”等信息在业主关系表中重复存储,存在数据冗余。
第 3 题
阅读下列说明和图,回答问题1至问题3,将解答填入答题纸的对应栏内。
【说明】
某网上药店允许顾客凭借医生开具的处方,通过网络在该药店购买处方上的药品。该网上药店的基本功能描述如下:
(1)注册。顾客在买药之前,必须先在网上药店注册。注册过程中需填写顾客资料以及付款方式(信用卡或者支付宝账户)。此外顾客必须与药店签订一份授权协议书,授权药店可以向其医生确认处方的真伪。
(2)登录。已经注册的顾客可以登录到网上药房购买药品。如果是没有注册的顾客,系统将拒绝其登录。
(3)录入及提交处方。登录成功后,顾客按照“处方录入界面”显示的信息,填写开具处方的医生的信息以及处方上的药品信息。填写完成后,提交该处方。
(4)验证处方。对于已经提交的处方(系统将其状态设置为“处方已提交”),其验证过程为:
①核实医生信息。如果医生信息不正确,该处方的状态被设置为“医生信息无效”,并取消这个处方的购买请求;如果医生信息是正确的,系统给该医生发送处方确认请求,并将处方状态修改为“审核中”。
②如果医生回复处方无效,系统取消处方,并将处方状态设置为“无效处方”。如果医生没有在7天内给出确认答复,系统也会取消处方,并将处方状态设置为“无法审核”。
③如果医生在7天内给出了确认答复,该处方的状态被修改为“准许付款”。
系统取消所有未通过验证的处方,并自动发送一封电子邮件给顾客,通知顾客处方被取消以及取消的原因。
(5)对于通过验证的处方,系统自动计算药品的价格并邮寄药品给己经付款的顾客。
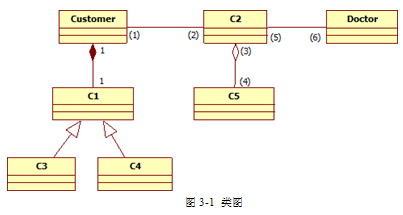
该网上药店采用面向对象方法开发,使用UML进行建模。系统的类图如图3-1所示。
【问题1】(8分)
根据说明中的描述,给出图3-1中缺少的C1~C5所对应的类名以及(1)~(6)处所对应的多重度。
【问题2】(4分)
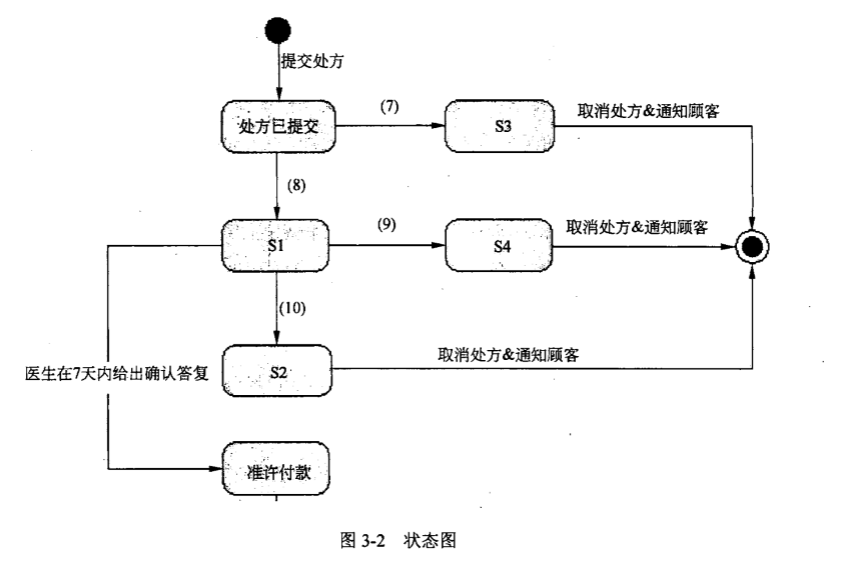
图3-2给出了“处方”的部分状态图。根据说明中的描述,给出图3-2中缺少的S 1~S4所对应的状态名以及(7)~(10)处所对应的迁移(transition)名。
【问题3】(3分)
图3-1中的符号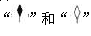 在UML中分别表示类和对象之间的哪两种关系?两者之间的区别是什么?
在UML中分别表示类和对象之间的哪两种关系?两者之间的区别是什么?
答案与解析
- 试题难度:较难
- 知识点:UML建模>状态图
- 试题答案:
【问题1】(8分)
C1:付款方式 (1分)
C2:处方 (1分)
C3:信用卡 (1分)
C4:支付宝账户 (1分)
C5:处方上的药品(或药品) (1分)
【其中C3、C4位置可互换】
(1)1 (2)0.. (3)1
(4)1.. (5)0..* (6)1
(1)~(6)各0.5分
【问题2】(4分,各0.5分)
S1:审核中 S2:无法审核 S3:医生信息无效 S4:无效处方
(7)医生信息不正确 (8)医生信息正确
(9)医生回复处方无效 (10)医生没有在7天内给出确认答复
【其中S2/(9)和S4/(10)可成对互换,S1/(7)和S3/(8)可成对互换,】
【问题3】(3分)
 表示组合(composition),
表示组合(composition), 表示聚合(aggregation)。(1分)
表示聚合(aggregation)。(1分)
在组合关系中,整体对象与部分对象具有同一的生存周期。当整体对象不存在时,部分对象也不存在。(1分)
而聚合关系中,对整体对象与部分对象没有这样的要求。(1分) - 试题解析:
本题考查面向对象开发相关知识,涉及UML类图以及类图设计时的设计模式。UML目前在面向对象软件开发中广泛使用,是面向对象软件开发考查的重要内容。
【问题1】
本问题考查类图。要完成这个题目我们需要根据题目的描述来进行,根据题目前面的描述,我们不难找出该系统中应包含的类有顾客、处方、信用卡、支付宝账户、核实医生、付款方式和药品等。在类图中已经给出了顾客和核实医生两个类。根据题目描述:顾客在买药之前,必须先在网上药店注册。注册过程中需填写顾客资料以及付款方式(信用卡或者支付宝账户)。此外顾客必须与药店签订一份授权协议书,授权药店可以向其医生确认处方的真伪。再结合类图,我们不难看出C2应该是处方,因为它与顾客和医生都有关系,那么根据类图也就知道C5是药品。另外也可以知道C1是支付方式,而C3和C4是从C1继承而来,那么很显然是题目中描述的两种付款方式,分别是信用卡和支付宝账户。
知道了C1到C5的类以后,要求他们之间的重复度,就变得容易了,由于一个顾客可以与0至多个处方联系,而一个处方可以包含一至多种药品(如果没有药品,那么处方就没有存在的必要了),另外一个医生可以验证多张处方,也可以不验证处方。因此,顾客与处方是1:0...*关系,处方与药品是1:1...*的关系,而医生与处方为1:0...*的关系。
【问题2】
本问题考查状态图。状态图用来描述一个特定对象的所有可能状态及其引起状态转移的事件。根据题目意思,在提交处方后,就应该验证处方,验证处方的步骤,首先是验证医生信息,如果医生信息不正确,该处方的状态被设置为“医生信息无效”,并取消这个处方的购买请求,那么结合状态图,我们可以知道,S3应该为“医生信息无效”,而7是医生信息不正确;那么8就是另外一个分支,是医生信息正确,如果医生信息正确,系统给该医生发送处方确认请求,并将处方状态修改为“审核中”,因此S1状态是“审核中”那么8就是医生信息正确。接着进入描述中的第二步,如果医生回复处方无效,系统取消处方,并将处方状态设置为“无效处方”。如果医生没有在7天内给出确认答复,系统也会取消处方,并将处方状态设置为“无法审核”。
结合状态图,我们可以知道S2应该是“无法审核”状态,而S4就是“无效处方”状态。相应的9就是医生回复处方无效,10就是医生没有在7天内给出确认答复。
【问题3】
本问题考查聚合与组合这两种关系的联系与区别。
表示组合(composition),表示聚合(aggregation)。
在组合关系中,整体对象与部分对象具有同一的生存周期。当整体对象不存在时,部分对象也不存在。
而聚合关系中,对整体对象与部分对象没有这样的要求。
第 4 题
阅读下列说明和C代码,回答问题1至问题3,将解答写在答题纸的对应栏内。
【说明】
堆数据结构定义如下:
对于n个元素的关键字序列{a1,a2,...,an},当且仅当满足下列关系时称其为堆。

在一个堆中,若堆顶元素为最大元素,则称为大顶堆;若顶堆元素为最小元素,则称为小顶堆。堆常用完全二叉树表示,图4-1是一个大顶堆的例子。
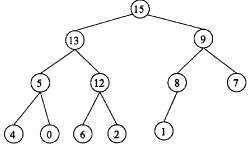
图4-1 大顶堆示例
堆数据结构常用于优先队列中,以维护由一组元素构成的集合。对应于两类堆结构,优先队列也有最大优先队列和最小优先队列,其中最大优先队列采用大顶堆,最小优先队列采用小顶堆。以下考虑最大优先队列。
假设现已建好大顶堆A,且已经实现了调整堆的函数heapify(A,n,index)。
下面将C代码中需要完善的三个函数说明如下:
(1)heapMaximum(A):返回大顶堆A中的最大元素。
(2)heapExtractMax(A):去掉并返回大顶堆A的最大元素,将最后一个元素“提前”到堆顶位置,并将剩余元素调整成大顶堆。
(3)maxHeapInsert(A,key):把元素key插入到大顶堆A的最后位置,再将A调整成大顶堆。
优先队列采用顺序存储方式,其存储结构定义如下:
define PARENT(i) i/2
typedef struct array{
int *int_array; //优先队列的存储空间首地址
int array_size; //优先队列的长度
int capacity; //优先队列存储空间的容量
}ARRAY;
【C代码】
(1)函数heapMaximumint heapMaximum(ARRAY *A){ return (1) ; }
(2)函数heapExtractMax
int heapExtractMax(ARRAY *A){
int max;
max=A->int_array[0];
(2);
A->array_size --;
heapify(A,A->array_size,0); //将剩余元素调整成大顶堆
return max;
}
(3)函数maxHeapInsert
int maxHeapInsert(ARRAY *A,int key){
int i,*p;
if (A->array_size == A->capacity) { //存储空间的容量不够时扩充空间
p=(int*)realloc(A->int_array,A->capacity *2 * sizeof(int));
if (!p) return -1;
A->int_array = p;
A->capacity = 2 * A->capacity;
}
A->array_size ++;
i = (3) ;
while (i > 0 && (4)){
A->int_array[i] = A->int_array[PARENT(i)];
i = PARENT(i);
}
(5);
return 0;
}
【问题1】(10分)
根据以上说明和C代码,填充C代码的空(1)~(5)。
【问题2】(3分)
根据以上C代码,函数heapMaximum、heapExtractMax和maxHeapInsert的时间复杂度的紧致上界分别为 (6) 、(7) 、(8) (用O符号表示)。
【问题3】(2分)
若将元素10插入到堆A={15,13,9,5,12,8,7,4,0,6,2,1}中,调用maxHeapInsert函数进行操作,则新插入的元素在堆A中的第 (9) 个位置(从1开始)。
**答案与解析** - 试题难度:较难 - 知识点:数据结构与算法应用>其它 - 试题答案:【问题1】
(1)A->int_array[0]
(2)A->int_array[0]= A->int_array[A->array_size-1]
(3)A-> array_size-1
(4)A->int_array[PARENT(i)]<key
(5)A->int_array[i]=key
【问题2】
(6)O(1) (7)O(lgn) (8)O(lgn)
【问题3】
(9)3
- 试题解析:
【问题1】
本题考查堆数据结构的相关内容。题目告诉我们函数heapMaximum(A)的功能返回大顶堆A中的最大元素;函数heapExtractMax(A)的功能是去掉并返回大顶堆A的最大元素,将最后一个元素“提前”到堆顶位置,并将剩余元素调整成大顶堆;而函数maxHeaplnsert(A, key)的功能是把元素key插入到大顶堆A的最后位置,再将A调整成大顶堆。
第(1)空在函数heapMaximum(A)中,而且从程序中可以看出,是返回的结果,那么应该是大顶堆中最大元素,就应该是A->int_array[0]。
第(2)空在函数heapExtractMax(A)中,根据该函数的功能描述,并结合程序可以看出,第(2)空是在将最大元素移出后,那么接下了来应该处理将最后一个元素“提前”到堆顶位置,那么就应该是A->int_array[0] = A->int_array[A->array_size -1]。
第(3)(4)(5)空都在函数maxHeaplnsert(A, key)中。从程序和函数的功能我们可以知道,从程序第(3)空最后,其作用是找到元素key的插入位置并插入该元素。第(3)空是给变量i赋值,从后面的程序中我们可以看出i是做为数组下标的;而查找元素插入的位置应该从后往前的顺序,因此i的初值应该为A->array_size – 1,从循环中也可以看出i的值在逐渐变小。
第(4)空是循环的一个条件,而循环的作用是找到合适的插入位置,由于大顶堆的特点是根节点的值大于左右子树节点上的值,那么找到比待插入元素大的父节点时,应该就找到了它插入的合适位置,而每次操作后i的值被赋值为PARENT(i),很显然这是找到其父节点的存储位置,因此循环结束的一个条件就是找到一个比key值大的父节点,那么循环继续的条件就是父节点的值小于key的值,所以本空的答案为A->int_array[PARENT(i)]<key 。
【问题2】
根据题目描述,heapMaximum用来返回大顶堆A中的最大元素,而且大顶堆已经建成,只需要通过一步操作就能取到。因此时间复杂度是O(1),
而对于heapExtractMax是用来去掉大顶堆A的根,然后重新建堆,当输出堆顶结点并将堆中最后一个结点设置为根结点之后,根结点将有可能不再满足堆的性质,所幸的是整个序列也只有根结点一处的堆结构可能被破坏,其余结点仍然满足堆性质,故可利用性质进行堆调整,算法的基本思想为:将新堆顶沿着其关键字较大的孩子结点向下移动,直到叶子结点或者满足堆性质为止。因此相对于有N个元素的堆,只需要log2n次比较即可完成,因此时间复杂度是O(log2n),这与书本说堆排序的算法时间复杂度是:O(nlog2n)不冲突,因为书本上是对堆中所有元素进行操作,而这里其实相当于只将一个元素入堆,因此少了一个n。同样的道理可以得到maxHeaplnsert的时间复杂度O(log2n)。
【问题3】
这个我们可以结合题目给出的那个大顶堆的图来看,首先将key插入在最后,应该是8这个节点的右子树,由于10比8大,所以应该互换,再与节点9比较,由于10仍然大于9,所以也应该互换,这个时候再与其父节点15比较,由于小于15,所以不需要再调整,那么调整后的结果就是10这个元素应该作为根节点15的右子树。那么很显然10应该是在堆A中第3个位置。
第 5 题
阅读下列说明和C++代码,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
某公司的组织结构图如图5-1所示,现采用组合(Composition)设计模式来构造该公司的组织结构,得到如图5-2所示的类图。
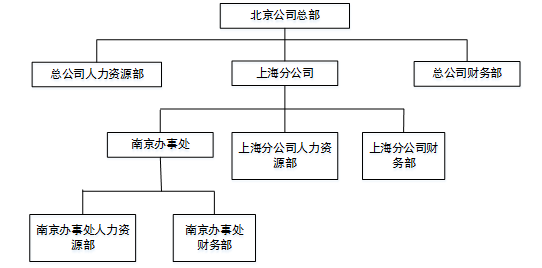
图5-1 组织结构图
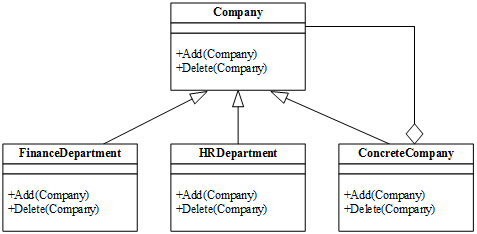
图5-2 类图
其中Company为抽象类,定义了在组织结构图上添加(Add)和删除(Delete)分公司/办事处或者部门的方法接口。类ConcreteCompany表示具体的分公司或者办事处,分公司或办事处下可以设置不同的部门。类HRDepartment和FinanceDepartment分别表示人力资源部和财务部。
【C++代码】
#include <iostream>#include <list>
#include <string>
using namespace std;
class Company {//抽象类
protected:
strìng name;
public:
Company(string name) {(1)= name;}
(2); //增加子公司、办事处或部门
(3);//删除子公司、办事处或部门
};
class ConcreteCompany: public Company {
private:
list<(4)>children; //存储子公司、办事处或部门
public:
ConcreteCompany(string name) : Company(name) { }
void Add(Company* c) { (5).push_back(c); }
void Delete(Company* c) { (6).remove(c); }
};
class HRDepartment : public Company {
public:
HRDepartment(string name) : Company(name) { } //其他代码省略
};
class FinanceDepartment : public Company {
public:
FinanceDepartment(string name) : Company(name) { } //其他代码省烙
};
void main() {
ConcreteCompany *root = new ConcreteCompany("北京总公司") ;
root->Add(new HRDepartment("总公司人力资源部") ) ;
root->Add(new FinanceDepartment("总公司财务部") ) ;
ConcreteCompany *comp = new ConcreteCompany("上海分公司") ;
comp->Add(new HRDepartment("上海分公司人力资源部") ) ;
comp->Add(new FinanceDepartment("上海分公司财务部") ) ;
(7);
ConcreteCompany *comp1 = new ConcreteCompany("南京办事处") ;
comp1->Add(new HRDepartment("南京办事处人力资源部") ) ;
comp1->Add(new FinanceDepartment("南京办事处财务部") ) ;
(8); //其他代码省略
}
**答案与解析** - 试题难度:较难 - 知识点:面向对象程序设计>C++程序设计 - 试题答案:
(1)this->name (1分)
(2)virtual void Add(Company* c) = 0 (2分)
(3)virtual void Delete(Company* c) = 0 (2分)
(4)Company* (2分)
(5)children (2分)
(6)children (2分)
(7)root->Add(comp) (2分)
(8)comp->Add(comp1) (2分)
本题考查基本面向对象设计模式的运用能力。
组合设计模式主要是表达整体和部分的关系,并且对整体和部分对象的使用无差别。由类图知Company是ConcreteCompany类、HRDepartment 类和FinanceDepartment类的父类,它抽象了三个类的共有属性和行为。
第(1)空是在构造函数中,被赋值为name,而name是构成函数所带的参数,那么这里是给类的一个属性name赋值,因此这空答案为:this->name。
第(2)空与第(3)空我们可以根据注释来完成,根据题目的描述,这里只提供接口,是虚方法,因此第(2)空与第(3)空分别应该为virtual void Add(Company* c) = 0和virtual void Delete(Company* c) = 0,这两个方法的参数可以从后面类的相应方法中获得。
第(4)空根据注释可以推导出应该填Company*。第(5)空与第(6)空的答案应该一致,都应该为children。
第(7)空和第(8)空在main函数中,用来创建组件结构图,根据题目提供的图,我们可以知道,创建了上海分公司接的后,应该将其添加至root下,因此第7空答案为root->Add(comp),同样的道理,第(8)空的答案为comp->Add(comp1)。
第 6 题
阅读下列说明和Java代码,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】某公司的组织结构图如图6-1所示,现采用组合(Composition)设计模式来设计,得到如图6-2所示的类图。
其中Company为抽象类,定义了在组织结构图上添加(Add)和删除(Delete)分公司/办事处或者部门的方法接口。类ConcreteCompany表示具体的分公司或者办事处,分公司或办事处下可以设置不同的部门。类HRDepartment和FinanceDepartment分别表示人力资源部和财务部。
图6-1 组织结构图

图6-2 类图
【Java代码】
import java.util.*;(1)Company {
protectedString name;
public Company(String name) { (2)= name; }
public abstract void Add(Company c); //增加子公司、办尊处或部门
public abstract void Delete(Company c); //删除子公司、办事处或部门
}
class ConcreteCompany extends Company {
private List<(3)> children = new ArrayList<(4)>();
//存储子公司、办事处或部门
public ConcreteCompany(String name) { super(name); }
public void Add(Company c) { (5).add(c); }
public void Delete(Company c) {(6).remove(c); }
}
class HRDepartment extends Company {
public HRDepartment(String name) { super(name); }
//其他代码省略
}
class FinanceDepartment extends Company {
public FinanceDepartment(String name) { super(name); }
//其他代码省略
}
public class Test {
public static void main(String[] args) {
ConcreteCompany root =new ConcreteCompany("北京总公司");
root.Add(new HRDepartment("总公司人力资源部") );
root.Add(new FinanceDepartment("总公司财务部") );
ConcreteCompany comp =new ConcreteCompany("上海分公司");
comp.Add(new HRDepartment("上海分公司人力资源部") );
comp.Add(new FinanceDepartment("上海分公司财务部"));
(7);
ConcreteCompany comp1 = new ConcreteCompany("南京办事处");
comp1.Add(new HRDepartment("南京办事处人力资源部") );
comp1.Add(new Fina.nceDepartment ("南京办事处财务部") );
(8); // 其他代码省略
}
}
**答案与解析** - 试题难度:较难 - 知识点:面向对象程序设计>Java程序设计>组合模式 - 试题答案:
(1)abstract class (2分)
(2)this.name (1分)
(3)Company (2分)
(4)Company (2分)
(5)children (2分)
(6)children (2分)
(7)root.Add(comp) (2分)
(8)comp.Add(comp1) (2分)
本题考查了Java语言的应用能力和组合设计模式的应用。
第(1)空在类名Company前,很明显应该要加关键字abstract class ,因为题目描述的Company类是一个抽象类。第(2)空在构造函数中的赋值语句中,应该为this.name,就是给该类的一个属性name赋值,这里应该用this.name来引用这个属性。第(3)空与第(4)空的答案应该都为Company,这样要注意在java中与C++中的区别。第(5)和第(6)空的答案应该一样,一个用来增加节点,一个用来删除节点,都是使用的children对象。根据题目提供的组织结构图,我们可以知道,创建了上海分公司接的后,应该将其添加至root(北京总公司)下,因此第7空答案为root.Add(comp),同样的道理,第(8)空的答案为comp.Add(comp1)。